以数据集{4,5,6,7,10,12,18}为结点权值,画出构造的哈弗曼树.
 我是猫还是狗22022-10-04 11:39:541条回答
我是猫还是狗22022-10-04 11:39:541条回答
以数据集{4,5,6,7,10,12,18}为结点权值,画出构造的哈弗曼树.
以数据集{4,5,6,7,10,12,18}为结点 权值,画出构造的哈弗曼树,计算其带权路径长度.
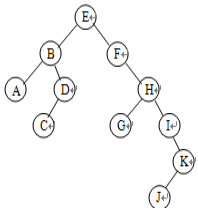
假设一棵二叉树如下图所示,求:
该二叉树的深度;
该二叉树的先序序列
该二叉树的中序序列;
该二叉树的后续序列.
根据二叉树的定义,具有三个结点的二叉树有5中不同形态,请将它们分别画出来.
已提交,审核后显示!提交回复
共1条回复
 冯大 共回答了15个问题
冯大 共回答了15个问题 |采纳率100%问题一:
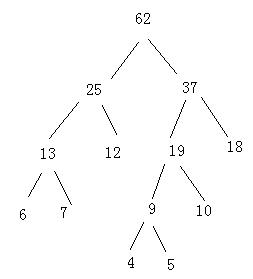
带权路径长度:6×3+7×3+12×2+4×4+5×4+10×3+18×2=18+21+24+16+20+30+36=165
问题二:
深度6
先序:EBADCFHGIKJ
中序:ABCDEFGHIJK
后序:ACDBGJKIHFE
形态:
- 1年前


相关推荐
- 怎样将一个sas数据集生成一个矩阵
loveheel011年前1
-
天麻麻亮 共回答了18个问题
|采纳率88.9%proc iml;
use sashelp.class;
read all var _num_ into xx;
print xx;
quit;1年前查看全部
- 已知均值跟协方差矩阵用MAtlab怎么来产生数据集,并画出1000个元素的散布图.
yawxy1年前1
-
叶落无狠 共回答了22个问题
|采纳率81.8%mu=[1,2];
c=[1,0;0,1];
temp=randn([1000,2]);
l=chol(c,'lower');
data=temp*l;
plot(data(:,1)+mu(1),data(:,2)+mu(2),'r.');
其中C表示协方差矩阵,mu为均值.我把那个协方差写成了两个独立的了,当然你可以根据你的改,我本来想附个图,结果每次附图都让百度给我屏蔽掉,如果你有什么问题问我就行了.1年前查看全部
- SAS语句求解~~请问一下语句什么意思?其中,egv数据集已经存在.尤其是其中:If n=1 then set egv;
SAS语句求解~~
请问一下语句什么意思?其中,egv数据集已经存在.尤其是其中:If n=1 then set egv;一句.得到的结果很是奇怪,不是选择,而是向下全部读取.若需要全部语句请吱声~~多谢了.
Data egv;
Set prinstat;
if _TYPE_='EIGENVAL' then output;
Drop _name_;
Rename x1=A1 x3=A2 x5=A3 x7=A4;
Run;
proc print data=egv;
run;
Data ds;
Set prin;
If n=1 then set egv;
Keep n code prin1 prin2 prin3 prin4 x1 x3 x5 x7 B1 B2;
B1=A1/(A1+A2);
B2=A2/(A1+A2);
Proc print data=ds;
Run;
输出结果不是判断出n=1的时候附数据集egv,而是所有的都行都被加上了数据集egv.宝宝Q1年前1 -
saylove520d 共回答了17个问题
|采纳率94.1%If n=1 then set egv这句是判断语句而已啊~就是如果N=1的话就引用egv数据集~
Keep n code prin1 prin2 prin3 prin4 x1 x3 x5 x7 B1 B2;这句是要求输出的变量名称而已~其他 的语句都是比较简单把~不啰嗦了1年前查看全部
- ds是一个数据集,DataTable dt = ds.Tables[0]; 然后对dt进行操作,再做DataGrid1.
ds是一个数据集,DataTable dt = ds.Tables[0]; 然后对dt进行操作,再做DataGrid1.DataSoure = ds,发现
DataGrid秀出来的是dt的内容,为什么?tianyinfei1年前1 -
小可小可可 共回答了18个问题
|采纳率88.9%dt = ds.Tables[0];
这句话,不仅是赋值,而且将dt归属于ds.
dt一改,当然ds也改了.
如果你想ds别改,可用dt=ds.Tables[0].copy();之类嘛1年前查看全部
- 数据结构与算法:以数据集{4,5,6,7,10,12,18}为结点权值所构造的哈夫曼树,其带权路径长度为?
东洋浪人1年前0
-
共回答了个问题
|采纳率
- 如何从统计意义上判断两个数据集的相似度?
如何从统计意义上判断两个数据集的相似度?
可以想象两组统计数据,不妨假设二维数据,即为平面上两个图形.要衡量这两个图形的相似度的话,不仅要求其中心重合,还要其外形轮廓也大体相似,那么应该用何种量化标准?数据的协方差矩阵可否?
请给出统计意义下的一个大体的量化标准十二ly1年前1 -
au_10000 共回答了12个问题
|采纳率66.7%事实上用统计来说判断两个数据集的相似度的方法不是很好!
以下是我的几点猜想!
1:假设把整个数据化成条形统计图!长方形的形状和大小应相似有个前提,就是数据图要比较精确 否则,误差很大!
2:我们知道:条形图的长方形的面积是 频率 那么两个数据集的频率也因接近!
还有频数
貌似只有这些了,我必修三数学基本上没听过课,说一没办法继续帮助你!请见谅!
有什么问题可以请教《数学麦圈》呵呵!1年前查看全部
- 数据结构关于排序算法的问题?插入排序、选择排序、冒泡排序、基数排序、堆排序的算法中其比较次数与初始数据集顺序无关的是?请
数据结构关于排序算法的问题?
插入排序、选择排序、冒泡排序、基数排序、堆排序的算法中其比较次数与初始数据集顺序无关的是?请说明理由.紫岚8181年前1 -
淮南在线 共回答了13个问题
|采纳率92.3%选择排序的算法中,其比较次数与初始数据集顺序无关.
因为它固定是N-1轮外循环,用于选N-1次最小值(升序排序),每一轮必须要比较(N-i)次,才能在(N+1-i)个数中选 出最小元素.1年前查看全部
- 关于Matlab用函数Sin产生数据集
关于Matlab用函数Sin产生数据集
由函数y=sin【(x1的平方+X2的平方)再开方】/【(x1的平方+X2的平方)再开方】,Xi在-4Pi到4Pi之间产生的数据集穿309件衣服1年前1 -
可爱囡囡 共回答了20个问题
|采纳率85%x1=-4*pi:4*pi;
x2=-4*pi:4*pi;
y=sin(sqrt(x1.^2+x2.^2))./sqrt(x1.^2+x2.^2);
disp(y);1年前查看全部
- 求助关于在SAS中将矩阵做处理后重新生成矩阵和数据集的方法
求助关于在SAS中将矩阵做处理后重新生成矩阵和数据集的方法
我对某个对称矩阵m2作如下处理后,可以得到其对角线以下的下三角矩阵的所有元素:
proc iml;
use ssj.m2;
read all var _all_ into xx;
do i=1 to nrow(xx);
do j=i+1 to ncol(xx);
x=xx[j,i];
print x;
end;
end;
quit;
最后可以将其中所有元素输出.
但是我想问的是,如果想把对角线下的所有元素提取出来后,形成一个新的矩阵,进一步地,形成一个新的数据集,应该作怎样的处理?圆目大睁1年前1 -
in2therain 共回答了13个问题
|采纳率92.3%你是想把下三角矩阵中的元素提出来,生成一个什么样的矩阵?
矩阵到数据集,利用CREATE ;APPEND函数就可以.1年前查看全部
- 构造哈夫曼树:以数据集(3,4,5,8,11,18,20,30)为结点,构造一棵哈夫曼数,并求其带权路径长度.
waterwall1年前1
-
hy1zwl 共回答了17个问题
|采纳率76.5%构建哈夫曼树的步骤:
1,选取结点(node)中最小的两个,相加,构成一个新结点
2,重复第一步,直至所有结点都在同一个树型里面.
所以,大概构成后就是这样
.81
.0/ 1
./
.31 50
.0/ 1 0/1
./ /
.18 13 20 30
.0/ 1 0/ 1
./ /
.7 11 5 8
.0/ 1
./
.3 4
从最下面向上读,node3和node4是初始数据里面最小的两个,
它们组成一个新结点7,
然后再重复相同的步骤,在新数据里面,7和11是最小,他们组成18,
原始数据里面的18可以消去.
重复步骤直至所有结点在同一个树型里面
现在看看
3的哈夫曼编码就是0000,而数字最大的30编码就是111年前查看全部
- 关于数据结构排序算法的问题插入排序、选择排序、冒泡排序、基数排序、堆排序的算法中其比较次数与初始数据集顺序无关的是?请说
关于数据结构排序算法的问题
插入排序、选择排序、冒泡排序、基数排序、堆排序的算法中其比较次数与初始数据集顺序无关的是?请说明理由.13701年前1 -
4568870 共回答了18个问题
|采纳率88.9%选择排序.
选择排序的算法原理是:第一趟从n个待排关键字中找出最小的关键字放到第一个位置,如果要找到最小关键字则必须所有元素都进行比较,所以第一趟要比较n-1次;第二趟从剩下的n-1的元素中再通过n-2次的比较找出最小的元素…………以此类推,不管初始有没有序,它都一共要进行n-1趟排序共n(n-1)/2次比较,时间复杂度始终是O(n平方)
至于其他的,拿插入排序举例:插入排序的基本思想是每次将一个待排的记录按其关键字大小插入到前面已经排好序的子序列中.试想,如果已经排好序的子序列是123,待排记录为45,插入4时,只要和3比较一次就知道排在3后面,对5排序时只要与4比较一次就知道该排在4后面,共比较2次.如果已经排好序的子序列是234,待排记录为15,插入1时,它要从后往前依次比较3次才能找到自己的位置,同样对5排序时只要与4比较一次,共比较4次.由上例可知,插入排序会随着初始数据集的顺序不同而比较次数不同.
BTW,基数排序不是基于关键字比较的排序算法.
纯手打,望采纳,不清楚还可共同探讨.1年前查看全部
- sas如何根据另一数据集的观测来筛选变量?
sas如何根据另一数据集的观测来筛选变量?
本人是sas新手,想实现一个简单的功能.有have和have1两个数据集:
data have; input x y z $; cards; a b ca b ca b ca b c; run;
data have1; input code $; cards; xy; run;
我希望能够对have中的变量进行筛选,只保留在与have1观测相同的变量,即得到如下结果:
a b
a b
a b
a b
请问该如何实现这一功能?
程序显示有误,应该是:
data have;
input x y z $;
cards;
a ba ba ba b
;
run;
data have1;
input code $;
x
y
;
run;九道门的爷1年前1 -
ginayang 共回答了13个问题
|采纳率92.3%data have;
input (x y z) ($);
datalines;
a b c
a b c
a b c
a b c
;
run;
data have1;
input code $;
datalines;
x
y
;
run;
proc sql noprint;
select code
into:var_list separated by " "
from have1;
quit;
data have2;
set have(keep=&var_list.);
run;
proc print data=have2 noobs;
run;1年前查看全部
- 已知均值跟协方差矩阵用MAtlab怎么来产生数据集
deanfang1年前1
-
伟斌 共回答了17个问题
|采纳率88.2%如果是高斯分布,则下面的命令产生NxT的矩阵,其中R为NxN的协方差矩阵,T为数据长度.x渐进满足(x-M)*(x-M)'/T=R (当T很大时),所以它的均值为M,协方差矩阵为R.
x=R^(1/2)*randn(N,T)+M;1年前查看全部
- 要素类的概念在ArcGIS中的要素类和要素数据集
陈沉醉1年前1
-
steven_wangailp 共回答了10个问题
|采纳率100%要素类(feature class):在arcgis中是指具有相同的几何特征的要素集合,比如点的集合,表现为shapefile或者是Geodatabase中的feature class.
要素数据集(feature dataset):在arcgis中表现为geodatabase中的feature dataset,在一个数据集中所有的feature class都具有相同的坐标系统,一般也是在相同的区域.1年前查看全部
大家在问
- 1在线段AB中插入一个点,这时共有多少条线段?两个点的?100个呢?规律?
- 2由既不是合数、也不是质数的数和既是质数、又是偶数的数组成的数有_____________________________
- 3英语填空1.常惊奇的发现这个屋子是空的.I am very_____ ______find the room is em
- 4(2013•武昌区模拟)下列实验事实所得出的相应结论合理的是( )
- 5第3.4.12题,红笔画波浪线的地方是哪来的啊,
- 6(6)若函数 (ω>0)在区间 上单调递增,在区间 上单调递减,则ω=
- 7在三角形ABC中,∠A=2∠B=3∠C,求∠C的度数
- 8什么有机物能被氧气氧化稍稍全面一些
- 9做匀加速直线运动的物体经过一段时间后,阻力=重力(或牵引力),如果没有路程长度的限制,则此物体的运动状态改变为匀速直线运
- 10(2006•金山区二模)如图,已知在△ABC中,AB=AC,BC在直线MN上.
- 11一铜球的质量是178g,体积是30立方厘米,该铁球是空心还是实心的?若是空心的,在空心部分注入水银,种质量是多少?(铜密
- 12某电能表的表盘上标有“3000R/KW ·h,如果在1min内转盘转过18周,则电路中用电器在1min内消耗的电能为 _
- 13怎样把1、2、3、4、25、26、27、28、29这9个数填入圆圈里,使横行、竖行和斜行上三个数相加都等于55?
- 14有没有简单的英语小故事啊?要小学三年级的
- 15英语翻译1.If your husband smokes,can you understand it?1.我会劝他戒烟.