R语言菜鸟提问.有一个6*10的矩阵,算出每列的平均值后,若这个值大于50则表示为1,若小于5
 两潭泉2022-10-04 11:39:541条回答
两潭泉2022-10-04 11:39:541条回答
R语言菜鸟提问.有一个6*10的矩阵,算出每列的平均值后,若这个值大于50则表示为1,若小于5
R语言菜鸟提问.
有一个6*10的矩阵,算出每列的平均值后,若这个值大于50则表示为1,若小于50则表示为0.并把结果做成一个向量.
这种该怎么写?
矩阵是
Set.seed(75)
aMat
R语言菜鸟提问.
有一个6*10的矩阵,算出每列的平均值后,若这个值大于50则表示为1,若小于50则表示为0.并把结果做成一个向量.
这种该怎么写?
矩阵是
Set.seed(75)
aMat
已提交,审核后显示!提交回复
共1条回复
 苹1983 共回答了21个问题
苹1983 共回答了21个问题 |采纳率95.2%- 先算每列的均值
meanMat - 1年前
相关推荐
- 能不能用R语言按下面编程形式将正态分布改为指数分布,画出指数分布概率密度和分布函数?
能不能用R语言按下面编程形式将正态分布改为指数分布,画出指数分布概率密度和分布函数?
sigma=1
u=c(-2,0,2)
#计算和绘图
x=seq(-6,6,0.1)
t1=t2=list()
for(i in 1:3){
t1[[i]]=dnorm(x,u[i],sigma)
t2[[i]]=pnorm(x,u[i],sigma)
}
par(mar=c(2,2,2,1))
plot(x,t1[[1]],xlim=c(-6,6),type="l",lty=2,col=2) #概率分布图
lines(x,t1[[2]])
lines(x,t1[[3]],col=4,lty=3)
text(u,0.35,paste("u=",u,sep=""),col=c(2,1,4))
plot(x,t2[[1]],xlim=c(-6,6),type="l",lty=2,col=2) #累计分布图
lines(x,t2[[2]])
lines(x,t2[[3]],col=4,lty=3)
text(u,0.5,paste("u=",u,sep=""),col=c(2,1,4))痴琴浪子1年前1 -
begout 共回答了21个问题
|采纳率81%如果只是画图,用curve()函数就好了
画正态密度:curve(dnorm,xlim=c(-3,3),col=2)
xlim是控制x轴显示从哪儿到哪儿,col是控制曲线颜色
画指数密度:curve(dexp(x,rate=1),xlim=c(0,5))
画指数分布:curve(pexp(x,rate=1),xlim=c(0,5))
你的方法是生成很多点x=seq(-6,6,0.1)
逐一算出函数值
t1[[i]]=dnorm(x,u[i],sigma)
t2[[i]]=pnorm(x,u[i],sigma)
最后在plot出来,用type="l"和lty=2的虚线弄出来.
curve这些功能都可以做到.
curve(dexp(x,rate=1),xlim=c(0,5),lty=2,add=T)就有虚线,
add=T可以一图多线1年前查看全部
- R语言小问题 定义分段函数 当x0时 y=1+x
R语言小问题 定义分段函数 当x0时 y=1+x
用以下语句 y=numeric(length(x))
y[x梦忆灵箫1年前4 -
民乐一ll 共回答了12个问题
|采纳率75%应该 自己定义一个函数,如下:
xtoy1年前查看全部
- 关于R语言barplot(apply(...))
关于R语言barplot(apply(...))
请问我将数据记为矩阵,按行求均值时,由于第一列是字符,均值求不出来,请问做条形图怎么能作出下面这样啊?
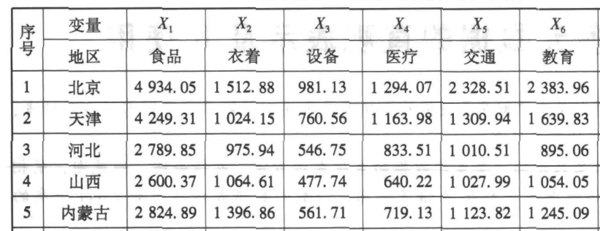
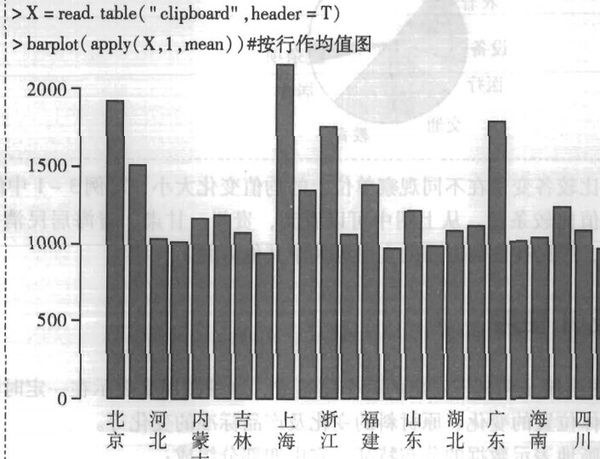
sok1681年前1 -
gg老总 共回答了18个问题
|采纳率100% 我用数字和字母表示,你对应的输进去,再画一下.我少些一列,抱歉
我用数字和字母表示,你对应的输进去,再画一下.我少些一列,抱歉
1年前查看全部

- R语言中,如果5个向量长度不同,怎样进行数据存储于一个txt文档
R语言中,如果5个向量长度不同,怎样进行数据存储于一个txt文档
因为数据相同时的date.frame,在数据长度不同时不可用1148371941年前1 -
mhltzhang 共回答了18个问题
|采纳率94.4%如果两向量为a,b
a1年前查看全部
- 请教一道R语言的统计题。。急T^T在线等
请教一道R语言的统计题。。急T^T在线等
假设有n个人去餐馆,每个人都戴了一顶帽子并将帽子寄存在餐馆门口。管理寄存帽子的人不小心将n个人的帽子打乱了,不知道哪顶帽子是属于谁的。当那n个人离开时,他便把任意一顶帽子归还给离开的人。n个人走的顺序是随机的。模拟一个R语言来回答以下问题:
1. 假设n=5。计算出没有一个人拿到自己帽子的概率。然后计算出至少有1个人拿到了自己帽子的概率。
2. 假设n=5。计算出拿到自己帽子的人数的平均数。
3. 重复第1问和第2问,当n=20的时候。
4. 假设n=50。计算出至少有1个人拿到了自己帽子的概率。计算出拿到自己帽子的人数的平均数。
5. 用更大的n来计算没有一个人拿到自己帽子的概率和拿到自己帽子的人数的平均数。
(提示:你需要模拟至少1000次,不断统计每一次有多少人拿到自己的帽子。)
ningmengdelei1年前1 -
q3629939 共回答了18个问题
|采纳率77.8%fun1年前查看全部
- 关于R语言函数sample(1:nrow(leadership))sample()函数中的第一个参数是一个由要从中抽样的
关于R语言函数
sample(1:nrow(leadership))
sample()函数中的第一个参数是一个由要从中抽样的元素组成的向量.在这里,这个向量
是1到数据框中观测的数量,请问sample函数什么意思怎么用?这句话无法理解.nrow(leadership)也不知道什么意思.
2714057571年前1 -
aaa1666 共回答了21个问题
|采纳率95.2%nrow(leadership)是leadership这个数据集的行数(可能就是样本数),1:nrow(leadership) 是一个向量,从1到nrow(leadership),sample(1:nrow(leadership)) 是将里面的这个向量进行随机排列了,不是之前那样的顺序了.sample(1:nrow(leadership))表示原来的数据集的序号被打乱了,但还是原来的数据集.1年前查看全部
- R语言,解释下这code>Eratosthenes 2) {+ sieve
正气凛然的dd1年前1
-
xiangchun 共回答了25个问题
|采纳率92%if (any(sieve ==i)) { # 如果i在sieve里 也可以写成 if ( i %in% sieve ) {
primes <- c(primes, i)# 把i放到prime里
sieve <- c(sieve[(seive %% i) != 0], i)#把所有sieve里i的整数倍数(除了i)取走
# %%是mod, 余数,所以 sieve[seive%%i) !=0]是所有seive里除以i余数不为0的数
}
整个这段代码是找出所有比n小的质数1年前查看全部
- R语言如何从一个structure类型的对象中提取出一个double型数值
R语言如何从一个structure类型的对象中提取出一个double型数值
现有一个叫 ttt的对象
R语言自带的数据编辑器 显示结果为
structure(list(mean = structure(11,.Tsp = c(3,3,5),class = "ts")),.Names = "mean")
在命令窗口中显示这个对象,结果为
> ttt
$mean
Time Series:
Start = c(3,1)
End = c(3,1)
Frequency = 5
[1] 11
如何从这个对象中把 11 这个double型的数据提取出来刺花儿1年前1 -
329554776 共回答了21个问题
|采纳率95.2%ttt$mean[1]1年前查看全部
- R语言 时间序列1、拟合一个模型,得到结果如下,怎么去判断拟合的系数的显著性啊?Series:z ARIMA(4,0,2
R语言 时间序列
1、拟合一个模型,得到结果如下,怎么去判断拟合的系数的显著性啊?
Series:z
ARIMA(4,0,2) with zero mean
Coefficients:
ar1 ar2 ar3 ar4 ma1 ma2
-0.5505 0.2316 0.0880 -0.4325 -0.1944 -0.5977
s.e.0.1657 0.1428 0.1402 0.1270 0.1766 0.1732
sigma^2 estimated as 417.6:log likelihood=-347.56
AIC=709.13 AICc=710.73 BIC=725.63
2.用auto.arima的时候得到的拟合结果是arima模型,有没有什么函数可以直接拟合sarima模型的?品风听雨1年前1 -
没天爱你 共回答了24个问题
|采纳率91.7%确定时间序列的周期一般用的是谱分析,小波分析方法,这些一般在网上能搜到相关文献!
时间序列是否平稳,ARMA(p,q)中的p,q的确定,这些方法在王文圣,丁晶等著作《随机水文学》中有详细介绍,中国水利水电出版社,第二版,你所提及的内容都有介绍,相信你会搞定!1年前查看全部
- R语言中计算期望的命令是什么
w网偷1年前2
-
lbb831209 共回答了19个问题
|采纳率84.2%ÕâºÍдjavaÓÐʲôÇø±ðÂ𣿠int j = 0; //³õʼֵΪ0£¨×¼±¸ÇóºÍ£© for(int i=1;i<=100;i++) { j +=i; } System.out.println("ºÍΪ" +1年前查看全部
- r语言 dnorm 函数现有一个矩阵m 需要求矩阵每一行的均值 方差 概率密度函数 apply(m,1,mean)可以求
r语言 dnorm 函数
现有一个矩阵m 需要求矩阵每一行的均值 方差 概率密度函数 apply(m,1,mean)可以求出每行均值。那么方差和概率密度函数怎么算呢?
维生素天然1年前1 -
黑犬黑犬土地 共回答了19个问题
|采纳率94.7%apply(m,1,var) #方差
> apply(m,1,sd) #方差
> apply(m,1,density) #概率密度1年前查看全部
- par(mgp=c(1.6,0.6,0),mar=c(3,3,2,1)) R语言里的
par(mgp=c(1.6,0.6,0),mar=c(3,3,2,1)) R语言里的
请问分别指的那个距离
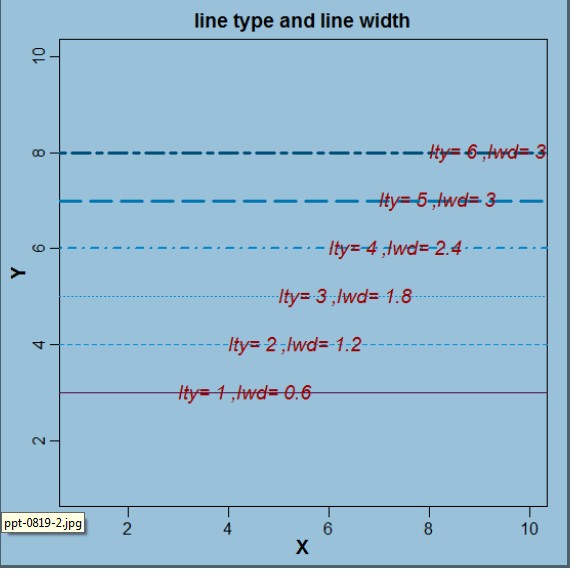
悠走无声1年前1 -
小品客 共回答了16个问题
|采纳率100%mgp指坐标轴与图之前的距离,mar指整个图的边界距离!1年前查看全部
- R语言解多元线性方程R语言中输入test之后,数据如下:>testx1 x2 y1 30.0 760.0 114.52
R语言解多元线性方程
R语言中输入test之后,数据如下:
>test
x1 x2 y
1 30.0 760.0 114.5
2 15.0 901.5 77.0
3 15.0 698.0 59.5
4 16.0 595.0 54.0
5 47.8 589.0 135.0
然后输入:
> Im.test=Im(test$y~test$x1+test$x2)
Error in Im(test$y test$x1 + test$x2) :
non-numeric argument to function
这报错了,应该怎么处理啊?mjgiggs1年前1 -
cc有cc 共回答了13个问题
|采纳率92.3%你先试试这样
lm.test=lm(y~x1+x2,test)
根据你的报错:non-numeric argument to function
就是说你的数据里面有非数字型的,可能是NA,可能是字符“n/a” 仔细排查一下吧1年前查看全部
- 在R语言中,怎么调节坐标刻度数字与坐标轴的距离
redfogman1年前1
-
握了一把妖娆 共回答了15个问题
|采纳率100%许多R 的高级图形自身就含有坐标轴,此外你可以用低级图形函数axis() 设置你自己的坐标轴.坐标轴主要包括三个部分:轴线(axis line)(线条格式由图形参数lty控制),刻度(tick mark)(划分轴线上的刻度) 和刻度标记(tick label)(标记刻度上的单位).这些部分可以通过下面的图形参数设置.lab=c(5, 7, 12) 前两个参数分别是x 和y 轴期望的刻度间隔数目.第三个参数刻度标记的字符长度(包括小数点).这个参数设的太小会导致所有的标记变成一样的数字.las=1 刻度标记的方向.0 表示总是平行于坐标轴,1 表示总是水平,以及2 表示总是垂直于坐标轴.mgp=c(3, 1, 0) 三个坐标成分的位置.第一个参数是轴标签相对轴位置的距离,以文本行作为参照单位的.第二个参数表示刻度标记的距离,最后一个参数是轴位置到轴线的距离(常常是0).正值表示在图形外,负值表示在图形内.tck=0.01 刻度的长度,以画图区域大小的比率作为度量.当tck 比较小(小于0.5),x 和y 轴上的刻度强制大小一致.值为1时,给出网格线.负值时刻度在图形外.tck=0.01 和mgp=c(1,-1.5,0)表示内部刻度.xaxs="r"yaxs="i" 分别设定x 和y 轴的形式."i" (内在的) 和"r" (默认) 形式的刻度都适合数据的范围,但是"r" 形式的刻度会在刻度范围两边留一些空隙(S 还有一些在R 里面没有实现的刻度形式).1年前查看全部
- 有放回的随机抽样怎么做用R语言怎么实现?—R
12airen1年前1
-
57543303 共回答了20个问题
|采纳率95%即随机抽样.sample(x,size,replace = FALSE,prob = NULL)replace=F,表示不重复抽样replace=T 表示可以重复抽样x=1:5sample(x,6,replace=T) #重复抽样[1] 1 2 1 4 4 3sample(x,2,replace=F) #不重复[1] 4 51年前查看全部
- R语言中怎么寻找最小值所在位置
wsgc1年前1
-
wangwei615 共回答了18个问题
|采纳率94.4%which.min()
# 例子
> x <- sample(10)
> x
[1]981562347 10
> which.min(x)
[1] 31年前查看全部
- 怎么用 r语言合并列求大神:比如第1到7列分别是1,2,3,4,5,6,7.怎么把它们合并成1234567都在一列内这样
怎么用 r语言合并列
求大神:比如第1到7列分别是1,2,3,4,5,6,7.怎么把它们合并成1234567都在一列内这样的,也就是新的一列只有一个数字“1234567”,合并后数字之间不要任何符号,
zhanglongtao1年前1 -
夏叉叉 共回答了19个问题
|采纳率73.7%a1年前查看全部
- r语言 茎叶图 'x'必需为数值
r语言 茎叶图 'x'必需为数值
x=read.table("E://data.txt")
> x
V1 V2
1 math stat
2 81 72
3 90 90
4 91 96
5 74 68
6 70 82
7 73 78
8 88 89
9 78 82
10 95 96
11 63 75
> stem(x$math)
错误于stem(x$math) :'x'必需为数值
为什么会报错?math 不就是 数值么?sailiang20081年前1 -
bondchen9533 共回答了25个问题
|采纳率96%首行问题,即math,stat这两个标签,
使用read.table("E://data.txt",header = TRUE) 应该就可以了1年前查看全部
- r语言中,t检验里的mu是什么意思
三人行三人行1年前1
-
鸳鸯锦江上 共回答了13个问题
|采纳率92.3%t.test里的mu是均值参数的意思,也就是原假设里H0:mu=const.1年前查看全部
- r语言 如何匹配两个矩阵比如有两个矩阵 a [,1] [,2][1,] 1 5[2,] 2 6[3,] 3 7[4,]
r语言 如何匹配两个矩阵
比如有两个矩阵
a
[,1] [,2]
[1,] 1 5
[2,] 2 6
[3,] 3 7
[4,] 4 8
b
[,1] [,2]
[1,] 1 5
[2,] 2 6
[3,] 3 0
[4,] 4 0
想提取a和b两列相同的部分,提取 (1,5) 和 (2,6) 如何做到阿?
MOMOCZ1年前0 -
共回答了个问题
|采纳率
- r语言求最值问题,急> a=0.2> b=0.7> f=function(x){x^a*(1-x)^b}要画图并求函数最
r语言求最值问题,急
> a=0.2
> b=0.7
> f=function(x){x^a*(1-x)^b}
要画图并求函数最大值
> curve(f)
> optimise(f,lower=0,upper=1)
请问哪里错了?程序给出的值和笔算的不一样因为活着所以活着1年前1 -
帕斯蓝 共回答了20个问题
|采纳率90%$objective不是区间最大值,是最大或最小这个值,究竟是多少.optimise的默认是求最小值,如果要求最大,>optimise(f,lower=0,upper=1,maximum=T)结果是$maximum[1] 0.222218$objective[1] 0.6208067所以xmax=0.222218 且...1年前查看全部
- R语言 里面怎么把一个数转换为二进制的0,1串,比如5=101,
A200110811年前1
-
勇斗第一剑人 共回答了19个问题
|采纳率84.2%先说简单的,有一个叫strtoi()的函数
# 如果直接写
> strtoi("111")
[1] 111
# 如果加base = 2,就是告诉R要换成十进制
> strtoi("111", base = 2)
[1] 7 反过来就有些麻烦,R自带intToBits()函数,但效果不好,要自己调整
> intToBits(12)
[1] 00 00 01 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
[25] 00 00 00 00 00 00 00 0012换成二进制是1100,上面答案实际上是反过来读,三四位是11,其余都是0.paste(rev(as.integer(intToBits(12))), collapse="")
[1] "00000000000000000000000000001100"1年前查看全部
- r语言矩阵列按某一向量排列有一个R矩阵a:列名为c1,c2,c3,c4;有一个向量b:元素顺序为c4,c2,c1,c3;
r语言矩阵列按某一向量排列
有一个R矩阵a:列名为c1,c2,c3,c4;有一个向量b:元素顺序为c4,c2,c1,c3;请教如何将矩阵a的列按向量b排序.hanhui1231年前1 -
Letasdad 共回答了17个问题
|采纳率94.1%temp = matrix(1:16,4,4)
dimnames(temp) = list(c("c1","c2","c3","c4"),c("c4","c2","c1","c3"))
temp = temp[,order(colnames(temp))]1年前查看全部
- R语言怎么样定义一个矩阵3*3的矩阵1 2 36 4 57 8 9这个矩阵怎么定义啊!
nowiztki1年前1
-
漂在首都ww 共回答了29个问题
|采纳率89.7%matrix(1:9,3,3,T)
[,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6
[3,] 7 8 9
matrix是定义矩阵的函数,1:9表示1-9连续9个数,第一个3表示3行,第二个3表示3列,T表示转置,TRUE的缩写
运行第一行,后面那是enter后的,有问题可以互相交流1年前查看全部
- R语言中把满足条件的数放到一个向量中,有没有这样的函数
cj72541年前3
-
A291375498 共回答了18个问题
|采纳率100%有操作也有函数,但是函数是在一些特定的方法库里
直接写条件即可:
如果一个向量为A
A 2&A1年前查看全部
- R语言,求解释code.>U2 U1 X Y plot ( X)> cor(x,y)Q1:plot那图出来,怎么是个菱形
R语言,求解释code.
>U2 U1 X Y plot ( X)
> cor(x,y)
Q1:plot那图出来,怎么是个菱形的样子,好奇怪?为什么会这样.
Q2:X 和Y 是随机independent
Q3:U1 和U2 也是随机independent #那图都没plot U1,U2,那怎样知道啊?
Q4:X 和 Y 是 linearly dependent
Q5:U1 和 U2 linearly dependent吗?穿nn的人1年前1 -
冷潇林 共回答了22个问题
|采纳率95.5%我逐行给你解释
>U2 U11年前查看全部
- r语言中,with,which用法的问题,
r语言中,with,which用法的问题,
b b b
[1] 101 102
> with(subset(recommendation[user==1,]),which(item==101))
[1] 1
> with(subset(recommendation[user==1,]),which(item==102))
[1] 3
> with(subset(recommendation[user==1,]),which(b%in%item))
[1] 1 2
应该输出1和3呀怎么是2edwardz391年前1 -
浪漫红笺 共回答了20个问题
|采纳率95%这个是which(item.x==101)),不是which(item==101))吧
还有which(b%in%item.x))
一开始有item.x这一列元素的,后面怎么都是item了呀?
你能把信息再补充多一点吗?譬如把 m 给出来看一下.1年前查看全部
- 用R语言将一个dataframe变量,它有3列,A,B,C,命令如何写才能把A>2且C>3的行抽取出来?
用R语言将一个dataframe变量,它有3列,A,B,C,命令如何写才能把A>2且C>3的行抽取出来?
为什么data[data$A>2 & data$C>3]不行,雾夜飘渺1年前1 -
魁园往事 共回答了20个问题
|采纳率100%data[data$A>2 & data$C>3,] 即可1年前查看全部
- 关于R语言,求解释下.>rep(seq(2,20,2), rep(2,10))[1] 2 2 4 4 6 6 8 8 1
关于R语言,求解释下.
>rep(seq(2,20,2), rep(2,10))
[1] 2 2 4 4 6 6 8 8 10 10 12 12 14 14 16 16 18 18 20 20
seq (2, 20 , 2) 里的第2个2代表什么?是不是(by=)省略了?我只知道前面2,20是代表2到20的偶数.
rep(2,10)里2,10又分别代表什么?
谢谢
myflowerfairy1年前1 -
75821508 共回答了13个问题
|采纳率92.3%seq(2,20,2)这个是创建一个向量,从2到20步长是2.seq是sequence的简写,就是序列的意思.
结果是2,4,6,...,18,20
如果是seq(2,20,1)或者seq(2,20) 那么结果是2,3,4,...,18,19,20
有更简单的方法:2*(1:10) 其中括号可以省略,因为冒号的运算优先级更高.
rep(2,10)是2重复10次的,就是2,2,2,...,2 (10个2) rep是replicate的简写,是重复的意思.
那么整句话:rep(seq(2,20,2), rep(2,10)) 就是 2,4,6,...,18,20这个序列,第一个元素重复2次,第二个元素重复2次,.,第10个元素重复2次.1年前查看全部
- 需要用R语言做Regression的讲解材料.
需要用R语言做Regression的讲解材料.
请帮忙找一份用R语言组Regression的讲解材料,老师讲话讲不清楚,听不懂,板书也特奇葩,没办法只能尽量自学了.请尽量详细通俗一些.
对了,我是文科本科生,在念商科硕士.deng2449621年前1 -
粉红BABY 共回答了15个问题
|采纳率93.3%egression,有本‘例解回归分析’真心不错,可惜和R语言没什么关系;
用R专门讲回归分析的真心不多(至少我没见到过多少),但
随便找本R的教材,里面都至少会有一章讲到regression.1年前查看全部
- R语言 > pairs(iris[,1:4]) > pairs(iris[1:4]) 这俩语句画的图一样,那个逗号是干嘛
R语言 > pairs(iris[,1:4]) > pairs(iris[1:4]) 这俩语句画的图一样,那个逗号是干嘛的?
中括号里面那个逗号cbxsl1年前1 -
彩彩44 共回答了12个问题
|采纳率91.7%这个我查了下觉得应该是这么回事:iris首先是个数据框,数据框可以看做是矩阵的推广,也可以看成是特殊的列表.在你这里通过调用iris[,1:4]和iris[,1:4]得到一个数据结果,我觉得是在调用iris[,1:4]的时候吧iris当成了特殊的矩阵,这样的话就代表iris的1到4列,前面的逗号代表所有的行.而再调用iris[1:4]的时候把iris当成了特殊的列表,调用的而是iris的第1到4个元素,正好也是iris作为矩阵的第1到4列,所以两者就像等了.1年前查看全部
- 在R语言中如何将两张散点图画在一起?
kiddof12081年前1
-
ARRowli 共回答了18个问题
|采纳率83.3%例如vd2=c(-16.3,-12.2,-8.2,-3.9,0,5.9,9.7,13.2,18.1)
vd1=c(-16.6,-12.5,-8.8,-4.2,0,6,9.8,15,18.2)
y=c(-16,-12,-8,-4,0,4,8,12,16)
plot(y~vd1)
plot(y~vd2,col="red")
然后在require(ggplot2)
vd = rbind(data.frame(v=vd1,y=y,t=as.factor(1)),data.frame(v=vd2,y=y,t=as.factor(0)))
ggplot(vd,aes(x=v,y=y)) + geom_point(aes(color=t))
可能会下个程序包1年前查看全部
- r语言写a(a-1).(a-k+1)怎么写?
yzm1561年前1
-
qingqi525 共回答了11个问题
|采纳率100%prod((a-k+1):a)
比如a=6,k=4, 那么所求的就是6·5·4·3
程序就是prod(3:6)
prod表示连乘,3:6表示(3,4,5,6)这个向量,prod(3:6)表示从3一直乘到6.1年前查看全部
- R语言做时间序列分析时,summary给出的结果都是什么意思啊?
R语言做时间序列分析时,summary给出的结果都是什么意思啊?
比如下面这个例子:
summary(auto.arima(z))
Series:z
ARIMA(4,0,2) with zero mean
Coefficients:
ar1 ar2 ar3 ar4 ma1 ma2
-0.5505 0.2316 0.0880 -0.4325 -0.1944 -0.5977
s.e.0.1657 0.1428 0.1402 0.1270 0.1766 0.1732
sigma^2 estimated as 417.6:log likelihood=-347.56
AIC=709.13 AICc=710.73 BIC=725.63
Training set error measures:
ME RMSE MAE MPE MAPE MASE
Training set 2.948732 20.43421 14.6533 85.00813 200.1053 0.6767153
有没有办法检验系数估计的显著性啊?cc摄手1年前1 -
rooney83 共回答了20个问题
|采纳率85%这个是自动适应参数估计的结果.
模型估计为ARIMA(4,0,2),即ARMA(4,2)
系数为:
ar1 ar2 ar3 ar4 ma1 ma2
-0.5505 0.2316 0.0880 -0.4325 -0.1944 -0.5977
s.e.0.1657 0.1428 0.1402 0.1270 0.1766 0.1732
s.e.是系数的标准差,系数显著性要自己算,|系数/se| > 1.96 即 95%的置信度
sigma^2 estimated 估计值方差
log likelihood 对数似然值
(这个不用解释了吧)
AIC=709.13 AICc=710.73 BIC=725.63
再就是下面一堆误差计算
MEx05Mean Error
RMSEx05Root Mean Squared Error
MAEx05Mean Absolute Error
MPEx05Mean Percentage Error
MAPEx05Mean Absolute Percentage
MASEx05Mean Absolute Scaled Erro1年前查看全部
- 关于R语言.如何构成这个向量用rep()和seq(), 构成这个向量.1 2 3 4 5 2 3 4 5 6 3 4 5
关于R语言.如何构成这个向量
用rep()和seq(), 构成这个向量.
1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
然后能解释下吗.
asasww1年前1 -
施穗 共回答了20个问题
|采纳率80%seq可以用冒号代替的,用起来更方便.
首先用rep生成5个1,2,3,4,5的重复,然后加上向量5个0,5个1,到5个4
操作如下
>rep(1:5,5)+rep(0:4,rep(5,5))
[1] 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9
不喜欢冒号的话就用seq
>rep(seq(1,5),5)+rep(seq(0,4),rep(5,5))
[1] 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 91年前查看全部
- R语言中替代命令是什么,就是把一组数中的某一个全部换成另一个数
btmxyjza1年前1
-
璞蝶傲扬 共回答了14个问题
|采纳率100%a=rep(1:6,3)
a
a[a==4]=0
a1年前查看全部
- r语言绘图 一页多图问题要求是:图形分为6个区域,每个区域画一个小图,用par(mfrow=...)开头该怎么写?par
r语言绘图 一页多图问题
要求是:图形分为6个区域,每个区域画一个小图,用par(mfrow=...)
开头该怎么写?
par(mfrow=c(2,3))
之后还需要什么吗?xylo1年前0 -
共回答了个问题
|采纳率
- R语言 生物统计学作业求问这道题用R怎么写?
踏雪无痕8211061年前1
-
th123啊去 共回答了21个问题
|采纳率95.2%matrix(c(65,77,42,94,18,16,6,11,30,36,23,47,13,18,11,36),nc=4)->x
chisq.test(x)1年前查看全部
- 一张成绩单 怎么用R语言 怎么输数据 并对数据进行分析,比如求均值,中位数,方差分析 回归分析
137223485711年前1
-
aztlyt 共回答了19个问题
|采纳率100%容量指样本数,显然为7
中位数是将样本从小到大排列,处于中间的那个样本(样本数为奇数)或处于中间的那两个样本(样本数为偶数)的均值,这里是0 2 2 2 5 10 14 中间的是第4个数:2
样本均值,总和=35,再除以样本数7,结果为5
样本方差按以下公式计算:1/(n-1)Σ(xi-x0)^2 其中x0表示样本均值
1/6*[5^2+3^2*3+0+5^2+9^2]=158/6=26.33
9月1年前查看全部
- R语言中怎么画自定义函数图像p=function(n,m){N=10^6x=c(rep(0,5),1)z=numeric
R语言中怎么画自定义函数图像
p=function(n,m){
N=10^6
x=c(rep(0,5),1)
z=numeric(N)
for(i in 1:N){
y=sample(x,n,replace=T)
z[i]=sum(y)>=m
}
return(sum(z)/N)
}
当m=2,3,4时,把这三函数在同一个坐标化成散点图,然后拟合曲线!林京山先生1年前1 -
秋天的羔羊 共回答了21个问题
|采纳率90.5%用curve(function,add=T)试试1年前查看全部
大家在问
- 1高一英语作文:MyHometown
- 2英语翻译请意译,不要直译,要有诗意一点.A triend is sommeonewho knows the song i
- 3为了加强公民的节水意识,合理利用水资源,某市对居民用水实行阶梯水价,收费价格见下表:
- 4课外阅读训练:课外训练:①驰名世界的凡尔赛宫坐落在巴黎西南18公里的凡尔赛镇,它是人类艺术宝库的一颗灿烂的明珠.②凡尔赛
- 5英语翻译是不是翻译为:it is 3 years since he has smoked.
- 6托盘天平横梁上都有标尺和游码,向右移动游码的作用是( )
- 7将0~9这10数字填入下图的方框中,使得等式成立,现在已经填入“3”,请将其他9个数字填入(注:首位不能
- 8函数y=[cos(x-π/12)]^2+[sin(x+π/12)]^2-1是周期为___的____(奇/偶)函数.
- 9数学六年级上册能简算的要简算2道
- 10《从百草园到三味书屋》第二段的几种植物动物生活的季节
- 11渤海将变成死海 阅读答案!快!水利专家杨振环说:“眼下,渤海到了生死存亡的紧要关头,一些近岸海域已经超过了自净能力,达到
- 12英语翻译句子为“一颗微星照亮了天上的路”;还是light up作动词词组,把way翻译为副词的“远远地”high “高高
- 13已知三角形ABC,角A是直角,AB垂直BC于D,AB=4,AD=12/5,求AC、BC的长
- 1425g物质M与5g物质N充分反应后所得的混合物中有10gM、11gP和一种新物质Q.若M、N、P、Q的相对分子质量分别为
- 15几道数学题1.小李爱好集邮,他用10元钱买了6角和8角的两种邮票,共15张,那么他买了6角邮票多少张?8角邮票多少张?