SAS聚类分析中的类平均法是如何定义类间距离的?
 99sunboy2022-10-04 11:39:542条回答
99sunboy2022-10-04 11:39:542条回答
SAS聚类分析中的类平均法是如何定义类间距离的?
如题!
如题!
已提交,审核后显示!提交回复
共2条回复
 灏明嘴角的一粒痘 共回答了15个问题
灏明嘴角的一粒痘 共回答了15个问题 |采纳率100%- 类平均法(Average Linkage)中,用两类样品中,所有观测值两两观测间距离的平均作为类间距离.
类平均法事一种应用比较广泛,聚类效果较好的方法. - 1年前
- 大赛哆嗦 共回答了1362个问题
|采纳率 - 就是这样子滴
- 1年前
相关推荐
- 急:SPSS分析软件中聚类图的横坐标Rescaled Distance Cluster Combine怎么翻译?
adamas_su1年前1
-
crispwei 共回答了13个问题
|采纳率84.6%聚类重新标定距离(Rescaled Distance Cluster Combine)1年前查看全部
- IPv6的地址分配必须遵循聚类的原则,
娃哈哈drn1年前1
-
friendy1982 共回答了11个问题
|采纳率90.9%将来IPv6可能使地球上的每一粒沙子都有自己的逻辑地址,说明其地址空间非常大,采用聚类原则后,比如分为欧洲区、亚洲区、美洲区等,就可以简化路由的存储转发算法,节省开销.1年前查看全部
- SPSS聚类分析结果没规律我用SPSS做K-聚类分析把数据,分出的3类没有规律,好坏参差不齐,比如第一类中前两个数据都是
SPSS聚类分析结果没规律
我用SPSS做K-聚类分析把数据,分出的3类没有规律,好坏参差不齐,比如第一类中前两个数据都是最好的,但是第三种数据就明显不是最好的,数据都是实验真实数据,想问一下有别的什么原因造成的,有解决办法么?(答案有帮助在加50分)清晨一杯咖啡1年前1 -
西窗烛 共回答了21个问题
|采纳率100%可以在尝试选择依据不同的变量 或者变量的数量进行一下删减 再重新聚类一下
这个聚类结果跟你选择的变量有很大的关系1年前查看全部
- 中文解释…物以聚类…这个词『急用』
chengliangbb1年前1
-
5441688 共回答了19个问题
|采纳率84.2%物以类聚的中文解释
同类的东西聚在一起.指坏人彼此臭味相投,勾结在一起.
【出自】:《易·系辞上》:“方以类聚,物以群分.”
【示例】:自古道:.过迁性喜游荡,就有一班浮浪子弟引诱打合.◎明·冯梦龙《醒世恒言》卷十七
【近义词】:同流合污、臭味相投
【反义词】:格格不入、水火不容
【语法】:主谓式;作谓语、定语、分句;含贬义1年前查看全部
- 数据挖掘中分类、预测、聚类的定义和区别.
丙夫1年前1
-
猪在七楼半 共回答了21个问题
|采纳率85.7%sc-cpda 数据分析师公众交流平台 详细看我资料
区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较.例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较.最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低
GPA 的学生的65%不是.
关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件.例如,一个数据挖掘系统可能发现的关联规则为:major(X,“computing science”) ⇒ owns(X,“personal computer”) [support=12%,confidence=98%] 其中,X 是一个表示学生的变量.这个规则指出正在学习的学生,12% (支持度)主修计算机科学并且拥有一台个人计算机.这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度).
分类与预测
不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值.它们的相似性是他们都是预测的工具:
分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值.
聚类分析的数据对象不考虑已知的类标号.对象根据最大花蕾内部的相似性、最小化类之间的相似性的原则进行聚类或分组.形成的每一簇可以被看作一个对象类.聚类也便于分类法组织形式,将观测组织成类分层结构,把类似的事件组织在一起.
数据演变分析描述和模型化随时间变化的对象的规律或趋势,尽管这可能包括时间相关数据的特征化、区分、关联和相关分析、分类、或预测,这种分析的明确特征包括时间序列数据分析、序列或周期模式匹配、和基于相似性的数据分析1年前查看全部
- matlab作矩阵的聚类并做出图形.产生一个200×3值在10到100之间的随机矩阵,将200条记录聚类为5类,一距离最
matlab作矩阵的聚类并做出图形.产生一个200×3值在10到100之间的随机矩阵,将200条记录聚类为5类,一距离最小为原则,每类并在三维图形中以不同的颜色和符号显示结果,聚类中心用红色的五角星表示I行云流水1年前1
-
cmnsdjfkasdfoiau 共回答了21个问题
|采纳率100%%生成随机数据
clear;clc;
a=10*(1:2:9);
b=[0,sort(randint(1,4,[1,199])),200];
idx=randperm(200);
for n=1:5
X(idx((b(n)+1):b(n+1)),:)=unifrnd(a(n),a(n)+10,b(n+1)-b(n),3);
end
%聚类
Z=clusterdata(X,'maxclust',5);
%绘图
for n=1:5
Y(n,:)=mean(X(Z==n,:));
end
scatter3(X(:,1),X(:,2),X(:,3),10,Z);
hold on;
plot3(Y(:,1),Y(:,2),Y(:,3),'rp','markerfacecolor','r','markersize',10)1年前查看全部
- 模糊聚类分析图的具体含义是什么?怎样绘制啊?
被遗忘的帅哥1年前1
-
coolersummer 共回答了22个问题
|采纳率86.4%我帮楼主查了一些文献,由于这里篇幅有限,就只能把题目提供一下,如果需要详细的文献,请发消息给我:)
在数据分类中,常用的分类方法有多元统计中的系统聚类法〔‘」、模糊聚类分析[2]等.在模糊聚类分析中,首先要计算模糊相似矩阵,而不同的模糊相似矩阵会产生不同的分类结果;即使采用相同的模糊相似矩阵,不同的阑值也会产生不同的分类结果.“如何确定这些分类的有效性”便成为模糊聚类和模糊
识别研究中的一个重要问题.文献【3一5」把有效性不满意的原因归结于数据集几何结构的不理想.但笔者认为,不同的几何结构是对实际需要的反映,我们不能排除实际需要而追求所谓的“理想几何结构”,不理想的分类不应归因于数据集的几何结构.针对同一模糊相似矩阵,文献【2,6〕建立了确定模糊聚类有效性的方法.文献【2」用固定的显著性水平,在不同分类的F一统计量和F检验临界值的差中选最大者,即为有效分类.但是,当显著性水平变化时,此方法的结果也会变化.文献〔2〕引进了一种模糊划分嫡来评价模糊聚类的有效性,并人为规定当两类的嫡大于一数时,此两类可合并,通过逐次合并,最终得到有效分类.此方法人为干预较多,当这个规定数不同时,也会得到不同的结果.另外这两种方法也未比较不同模糊相似矩阵的分类结果.
现列举一些应用:
1.模糊聚类分析法在分析数据评估上的应用
2.模糊聚类分析在领口性能评价系统中的应用
3.花椒园棉蚜及其捕食性天敌动态的模糊聚类分析
4.南美斑潜蝇及其寄生蜂种群动态的模糊聚类分析
5.长三角城市经济发展的模糊聚类分析
6.模糊聚类分析在沥青路面养护路段划分中的应用
7.基于模糊聚类分析的冷连轧负荷分配修正
8.城市防空中目标优化分配的模糊聚类分析
9.抚河流域水环境质量模糊聚类分析
10.模糊聚类分析在经销商选择评估中的应用1年前查看全部
- 聚类分析中为什么要对类间距进行重新转化?重新标定距离的意义是什么?
过客GONE1年前1
-
shtj43 共回答了22个问题
|采纳率90.9%对类间距的重新转化是为了标准化,就是为了使不同类之间的距离可以直接比较,进行各种运算.重新标定距离的意义在于充分利用相对距离的概念,使后续的计算更加合理.1年前查看全部
- 聚类分析树状图如何分析,怎么判断分成几类?
聚类分析树状图如何分析,怎么判断分成几类?
做出的结果如图所示,请问该怎么分类?
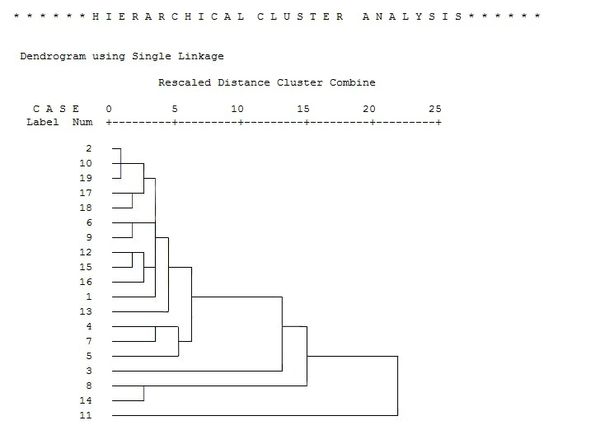 云逸昭1年前1
云逸昭1年前1 -
gudanluoye 共回答了16个问题
|采纳率93.8%从右边开始看,分为两类;然后从右往左看每个分叉就多分出一类.
换个方式说:就是把图逆时针转90度,你就能看明白了,就像一个树状图.
应该是分2到4类比较好,分类的间距越大效果越好.1年前查看全部
- 为什么要进行聚类分析
dengpin1年前1
-
xinyu83 共回答了16个问题
|采纳率81.3%聚类分析是研究“物以类聚”的一种科学有效的方法,由实验测试得到的数据是原始数据,原始数据是没有进行分类的、无规律的、错综复杂的变量,要使得这些数据能够反映出一定的规律性或特殊的分类性,需要对数据或变量进行聚类分析,以使数据或变量呈现一定的分门别类的特征.
聚类分析的一般做法是:先确定聚类统计量,然后利用统计量对样品或者变量进行聚类,对n个样品进行聚类的方法称为Q型聚类,常用的统计量称为“距离”;对m个变量进行聚类的方法称为R型聚类,常用个统计量称为“相似系数”.1年前查看全部
- 粒子群优化算法解决聚类集成问题?
粒子群优化算法解决聚类集成问题?
我用了kmeans等聚类方法对iris进行聚类,得到不同聚类分类号,其中一个算法得到的结果是
Columns 1 through 16
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Columns 17 through 32
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Columns 33 through 48
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Columns 49 through 64
1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2
Columns 65 through 80
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
Columns 81 through 96
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
Columns 97 through 112
2 2 1 2 3 2 3 2 3 3 2 2 2 3 2 2
Columns 113 through 128
3 2 2 3 2 3 3 2 3 2 3 2 3 3 2 2
Columns 129 through 144
2 3 3 3 2 2 2 3 3 2 2 3 3 3 2 3
Columns 145 through 150
3 3 2 2 3 2
不同算法得到的结果都是类似这种,假如现在有20*150维的类标号矩阵,我的想法是把这个矩阵当成是PSO的初始种群,利用基本的PSO算法实验了一下,速度随机取值,学习因子c1=1.49445; c2=1.49445;maxgen=300; %迭代次数,其中适应度函数取类标号与数据集标准分类号的正确率,然后利用算法迭代寻优,在实验过程中,迭代起不了任何作用,我怀疑是参数设置出了问题,再追加50分
我想在这20*150维矩阵中找到最优或者通过PSO算法粒子与速度更新得到最优的类标号,使得分类正确率高于 kmeans等算法得到的结果(也就是20*150的结果)qcc30111年前1 -
websnow 共回答了12个问题
|采纳率100%kmeans 给出的是150个样本的聚类后所属类别.你的样本是150*20的,也就是说,样本个数150,维数20.用粒子群做聚类的方法是,采用粒子群迭代的方法优化得到N个最优位置,这N个位置对应N个聚类的中心,本题N=3. 然...1年前查看全部
- 模式识别中,C均值算法的初始聚类中心点的选取会影响聚类情况的变化?
洞庭碧螺春1年前1
-
marho 共回答了24个问题
|采纳率91.7%会对结果有影响,包括聚类的种类都对聚类的结果有影响1年前查看全部
- 英语翻译统计方法 (1) Q 型系统聚类 :采用欧氏距离,类与类的距离定义为最长距离,用最长距离法合并两类.数据处理采用
英语翻译
统计方法 (1) Q 型系统聚类 :采用欧氏距离,类与类的距离定义为最长距离,用最长距离法合并两类.数据处理采用SPSS 软件.(2) Ridit 分析 对等级资料进行等级分布比
较,用X2 检验和薛氏X2 检验进行两两比较,数据处理用Excel 软件.冬天人1年前1 -
satan135 共回答了20个问题
|采纳率90%Statistical methods (1) Q type system clustering: using Euclidean distance, classes and class distance defined as the longest distance, use the longest distance method merged two kinds. Data processing by SPSS software. (2) Ridit analysis to grade material grades distribution ratio
Relatively, use X2 inspection and test XueShi X2 binary comparison, data processing, use of Excel software.1年前查看全部
- k-均值聚类和c-均值聚类一样吗
踢九四脚1年前1
-
逍遥匪客 共回答了15个问题
|采纳率66.7%完全一样.清华大学出版社的《模式识别》提到过.楼下说不一样,可能是把C均值聚类和模糊C均值算法混在一起了.1年前查看全部
- 英语翻译聚类是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程.由聚类所生成的簇是一组数据对象的集合,这些对象与
英语翻译
聚类是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程.由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异.“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题.聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法.聚类分析起源于分类学,但是聚类不等于分类.聚类与分类的不同在于,聚类所要求划分的类是未知的.聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等.txzh03221年前1 -
找爱的小猪 共回答了14个问题
|采纳率92.9%Clustering is a physical or abstract objects into a similar object composed of multiple classes of process. The clustering generated by the cluster is a group of data collections of objects, these objects with the same object in a cluster are similar to each other, and other objects in different clusters. " Like attracts like., birds of a feather flock together.", in the natural and Social Sciences, there exist a lot of problems of classification. Clustering analysis is also called group analysis, it is research ( samples or index ) classification of a statistical analysis method. Cluster analysis originated in the taxonomy, but not equal to the classification clustering. Clustering and classification of different clustering is required, dividing the class is unknown. Cluster analysis is very rich in content, a system clustering method, ordered sample cluster method, dynamic clustering, fuzzy clustering, graph clustering, clustering and prediction method1年前查看全部
- 英语翻译园林遥感普查遥感影像图量算面积正射纠正线形拉伸 边缘增强图像融合比值法时象几何校正 合成影像截减 聚类提取
SIX501年前2
-
白仙子 共回答了15个问题
|采纳率93.3%Remote sensing survey garden
Remote sensing image
Measurement area
Ortho-rectified
Linear tensile
Edge Enhancement
Image Fusion
Ratio method
Like when
Synthesis geometric correction
Image closed reduction
Clustering Extraction1年前查看全部
- 关于聚类分析的问题聚类分析后画出树状谱系图,谱系图的横坐标是原来需要进行分析的变量,那纵坐标是什么呢
清蒸ww1年前1
-
jobsjob 共回答了19个问题
|采纳率100%纵坐标是样本点间的距离(看你选的哪个距离了,但这没关系,与这里的主题无关),但你最好先把你的原始数据标准化,如x2=zscore(x),这里的x是原始数据矩阵.你试试,还不明白的话再问我吧1年前查看全部
- 关于K均值聚类会出现两次分类结果一样但是类中心坐标变化的情况吗?比如第一次分类{1,2,3} {4,5,6}第二次也是这
关于K均值聚类
会出现两次分类结果一样但是类中心坐标变化的情况吗?
比如第一次分类{1,2,3} {4,5,6}
第二次也是这个结果,但是重心坐标稍有变化.苍建新1年前1 -
likebo36 共回答了15个问题
|采纳率86.7%因为中心坐标是分类后各类内部数据的均值,分类一样,各类的数据就一样,均值当然一样.
除非你两次的分类结果是不一样的,分类结果不一样是可能的,因为初始化中心的不同会造成分类结果不同.1年前查看全部
- K均值聚类的基本过程是什么
聆听_11年前1
-
mgh-lei 共回答了14个问题
|采纳率100%假设你有n个样本,想聚成k类.从n个样本中随机抽取k个,作为最初的类中心.计算每个样本,到这k个中心的距离,离谁近就归为哪一类.这样就得到了k类,对新的每一类计算类中心,计算方法就是此类中包含的所有样本的均值.计算每个样本到k个新的类中心的距离,离谁近就归为哪一类.重复以上两步,即计算新的类中心,每个样本重新归类.知道分类没有变化了为止.以上就是k-means聚类的基本原理,基于以上原理,后来又有很多的改进算法,无非就是在初始类中心的选取、距离计算等环节做文章.1年前查看全部
- 英语翻译但乡村旅游概念界定依然模糊不清.通过比较聚类,文章从目的地、旅游客体、旅游主体和旅游动机四个维度对乡村旅游进行了
英语翻译
但乡村旅游概念界定依然模糊不清.通过比较聚类,文章从目的地、旅游客体、旅游主体和旅游动机四个维度对乡村旅游进行了定义.东方水虎1年前3 -
融融rong 共回答了20个问题
|采纳率90%但乡村旅游概念界定依然模糊不清.通过比较聚类,文章从目的地、旅游客体、旅游主体和旅游动机四个维度对乡村旅游进行了定义.
But the definition of the concept of rural tourism is still unclear.By comparing the clustering,the article from the destination,the object of tourism,travel and tourism the main motive of the four dimensions of rural tourism defined.1年前查看全部
- 排列组合问题 判断一句话的正误“分类计数原理体现了聚类分析的思想,运用分类计数原理得出的结果也可能错误” 这句话对么?说
排列组合问题 判断一句话的正误
“分类计数原理体现了聚类分析的思想,运用分类计数原理得出的结果也可能错误” 这句话对么?说法是否正确?leftwind1年前2 -
起飞的人 共回答了15个问题
|采纳率93.3%不正确1年前查看全部
- 动态聚类法有哪些?k-means ,FCM ,层次聚类,CURE,模糊聚类 这些哪些是系统聚类,哪些是动态聚类?
gwt131986411年前1
-
kobecnbryant 共回答了19个问题
|采纳率84.2%应该都是动态聚类算法,K均值肯定是1年前查看全部
- 请问层次聚类法与模糊聚类法有什么区别与联系?
请问层次聚类法与模糊聚类法有什么区别与联系?
我准备做一个关于物流节点类型分类的问题,拟把节点划分为三个层次,需要综合考虑多种因素.我准备用聚类分析的方法来做,请问该用层次聚类还是用模糊聚类呢?
如果用层次聚类,请问是如何将层次分析法和聚类分析相结合的呢.
答案只需要说一些概念性的东西,最好能具体推荐一些文献.网络商务通1年前1 -
习习卡卡 共回答了14个问题
|采纳率100%你的应用背景我不了解.但是感觉你好像要把样本分成三类,如果是这样的话,最好不要用层次聚类算法.层次聚类算法是不能自己指定聚类个数的,你需要用划分的聚类算法.聚类算法粗略分为两类:基于“层次的”与基于“划分”的.你说的模糊聚类算法也分很多种,最著名的也是最常用的就是模糊c均值聚类算法,它是基于“划分”的,个人感觉它应该适用于你的问题.你不需要把“层次”聚类与“划分”的或者“模糊”聚类进行结合.模糊c均值聚类本身就可以人为指定聚类个数,如果结合聚类有效性指标,也可以自动确定聚类个数.聚类有效性指标以及模糊c均值你可以查文献,上中国知网搜索,很多的,要想看具体的介绍可以搜索相关博士或者硕士论文,在里面都会介绍具体细节.模糊c均值的改进算法主要是可能性聚类算法,1年前查看全部
- 生物蛋白质分子的作用的聚类主要是为了什么目的,pathway图是用来干什么的?
生物蛋白质分子的作用的聚类主要是为了什么目的,pathway图是用来干什么的?
蛋白质分子的作用的聚类主要是为了什么目的,pathway有是用来干什么的?chenming091年前1 -
李先明 共回答了11个问题
|采纳率90.9%蛋白质相互作用网络是计算机科学技术的一个新研究领域.蛋白质功能预测是蛋白质相互作用网络富有挑战性的问题之一.它的研究不仅可以直接阐明生命体在生理或病理条件下的变化机制,而且对生物制药,农业生物科技等应用领域同样具有直接的指导作用.本文在深入分析现有蛋白质相互作用网络的聚类算法和蛋白质功能预测方法的基础上,对适合蛋白质相互作用网络的聚类算法和蛋白质功能预测问题进行了研究,提出一种新的聚类算法,并将聚类结果结合蚁群算法双序列比对来进行蛋白质功能预测,并进行了相应的实验分析,取得了较好的结果.论文主要工作包括:总结出当前蛋白质功能预测所面临的挑战和困难.本文从蛋白质序列,结构与相互作用入手,研究了蛋白质相互作用及其网络统计参数和网络拓扑结构,并系统分析了蛋白质功能预测研究现状.以往,蛋白质相互作用网络中结点之间的距离度量是需要通过基于网络的最短路径距离来重新定义,其计算代价高,这使得已有的基于欧几何距离的聚类算法不能直接运用到这种环境中.因此,通过蛋白质相互作用网络的特征提出了一种新的聚类算法.算法使用网络中的边和结点信息来缩减搜索空间,避免了一些不必要的距离计算.实验结果表明,算法对于真实的蛋白质相互作用网络中的结点聚类是高效的.提出了利用蚁群算法双序列比对从蛋白质相互作用网络中预测孤立蛋白质与聚类中心蛋白质的相互作用,进而预测孤立蛋白质的功能.实验结果表明,该方法蛋白质功能预测中的应用是可行和有效的,对蛋白质序列进行测试并与基于局部比较的滑动窗口序列比对算法相比,可以得到较为满意的结果.1年前查看全部
大家在问
- 1已知函数f(x)=x3+ax2+bx+c(1)若函数f(x)在区间【-1,0】上是单调减函数,求
- 2给朋友的道歉纸条 作文
- 3一段英语翻译您的签证邀请函已经拿到了.请你确认一下内容.没有问题的,我邮寄给您.随便告诉我一下地址.谢谢.这句话帮忙翻译
- 4人生是什么 作文
- 5一列客车和一列货车同时从ab两地相对开出,当两车相遇时,客车走了全长的70%,货车离中点还有40km客车行完全程需要4小
- 6为爱撑一把伞(第一次离开) 作文
- 7Jim每天(everyday)都会看电视
- 8若(a-1)²+1b-21=0,则以a,b为边长的等腰三角形的周长为
- 9“阳光总在风雨后,乌云上有晴空……请相信有彩虹,风风雨雨都接受。”上述歌词贴切地比喻了我们的成长过程总是 [
- 10如图7所示,已知直线AB‖EF,∠1=∠2=50°,∠3=130°,求∠BCD的度数
- 11“cause"这个单词的意思是什么?
- 12有一个蓄水池装有9根水管,其中一根为进水管,其余8根为相同的出水管.进水管以均匀的速度不停地向这个蓄水池注水.后来有人想
- 13高一英语改错Soon I began to enjoy talk to myself on paper as I was
- 141.氧化铁与稀盐酸稀硫酸反应的现象2.氧化铜与稀盐酸稀硫酸反应的现象
- 15已知集合,则集合M中元素个数是( )