用Eviews6做回归分析,得出趋势方程,但为什么将原数据带入趋势方程后方程两边不相等,急,到底是为什么呢?
 飞廉水墨2022-10-04 11:39:541条回答
飞廉水墨2022-10-04 11:39:541条回答
用Eviews6做回归分析,得出趋势方程,但为什么将原数据带入趋势方程后方程两边不相等,急,到底是为什么呢?

 将序号设为了X,GDP为Y1..
将序号设为了X,GDP为Y1..
将序号设为了X,GDP为Y1..
已提交,审核后显示!提交回复
共1条回复
 zzzxyz 共回答了12个问题
zzzxyz 共回答了12个问题 |采纳率100%- 当然不相等了,你这是个一元线性回归的,是一个直线拟合啊,eviews通常默认用的是最小二乘法,你写的那个方程表达式叫回归方程,每个x带入方程得到的y是个估计值,与真实值有偏差的啊,最小二乘法的思想就是使得这些偏差的平方和达到最小,也就是信息损失达到最小,其实真正的方程式:y=281.05+374.85x+et(随机误差项),方程两边结果的的偏差就用那个随机误差项来表示,通常省略后面的随机误差项,要的就是在可接受的损失范围内达到满足实际应用的要求.
- 1年前
相关推荐
- 截面数据怎么修正自相关?eviews能做吗?(尽管自相关普遍存在时间序列数据,但是截面数据仍然可能存在)
截面数据怎么修正自相关?eviews能做吗?(尽管自相关普遍存在时间序列数据,但是截面数据仍然可能存在)
我现在想用eviews修正截面数据的自相关,请问有方法吗?如何操作?
鹏城湘帅1年前1 -
gzqiking 共回答了16个问题
|采纳率100%可以做的
广义差分可以
我经常帮别人做这类的数据分析1年前查看全部
- 谁能帮我分析一下这个eviews的结果!
谁能帮我分析一下这个eviews的结果!

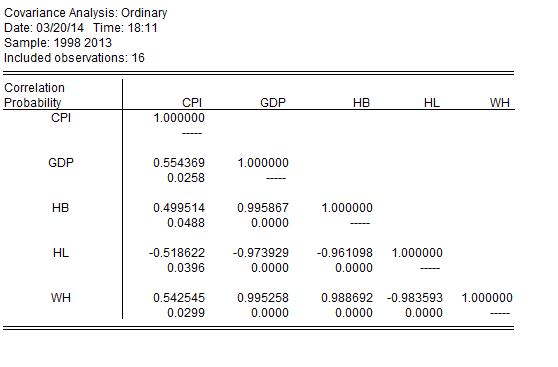
一个回归,一个相关性!两个分别分析一下!村地1年前1 -
tttbbb20000 共回答了20个问题
|采纳率90%回归分析:
四个自变量中,前三个的P值小于0.1,通过了显著性检验,即前三个变量对因变量有显著影响
调整后的判定系数为0.709,拟合优度不错.
DW值为2.04,表明不存在一阶自相关.
相关分析表明:CPI和四个变量都有显著的相关关系,因为P值都小于0.05,通过了0.05水平的显著性检验.而且,三个是正相关,一个是负相关,看符号就行了.
有困惑,可以加我QQ.1年前查看全部
- 计量经济学小白求助~eviews软件~关于DW值和修正自相关性导致T值通不过检验的问题
计量经济学小白求助~eviews软件~关于DW值和修正自相关性导致T值通不过检验的问题
用eviews做一个解释变量的回归模型,DW值为0.5,加ar(1),ar(2)后DW为1.5,但是解释变量的t值到了0.27了,这样是否该模型就没有意义了?如果要使其有意义该如何修正呢?cshoung1年前1 -
justleave 共回答了19个问题
|采纳率89.5%楼主为什么一定要AR(2)呢?...
AR(1)用广义差分就可以了...
经济意义一般AR(1)...楼主改AR(1)试试...
如果还不行...看看是不是有别的问题...改模型设定看看...或者改成大样本看看...
还有...
如果模型只是为了预测目的..系数不显著也勉强可以接受1年前查看全部
- Eviews做面板数据回归,什么时候需要进行单位根检验和协整检验呢?数据是2007-2011年,样本量很大
Eviews做面板数据回归,什么时候需要进行单位根检验和协整检验呢?数据是2007-2011年,样本量很大
我是研究股权结构和绩效的关系,数据是2007-2011五年的,样本量很大有82个公司,是否需要做单位根检验呢?我的R平方很小,DW统计量接近2,应该不是伪回归的特征吧?asdwjkli1年前1 -
哦是的 共回答了27个问题
|采纳率81.5%按照正规程序,面板数据模型在回归前需检验数据的平稳性.一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的.平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声.因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无.
因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验.而检验数据平稳性最常用的办法就是单位根检验.
如果基于单位根检验的结果发现变量之间是同阶单整的,那么我们可以进行协整检验.1年前查看全部
- 在eviews中的Ln计算我有4个变量,然后在最小二乘里输入log(y) c log(x1) log(x2) log(x
在eviews中的Ln计算
我有4个变量,然后在最小二乘里输入log(y) c log(x1) log(x2) log(x3) log(x4)
然后他就提醒我什么No index provided for group y
不明白是哪里出错了..记得以前也是这样输的啊魔幻玻璃瓶1年前3 -
zilingbbi 共回答了19个问题
|采纳率84.2%可以输入命令行
ls log(y)=c(1)+c(2)*log(x1)+c(3)*log(x2)+c(4)*log(x3)+c(5)*log(x4)1年前查看全部
- EViews回归结果计算,R-squared和sum都怎么求
skyfish20081年前1
-
xiaohui495 共回答了13个问题
|采纳率92.3%quick ,estimate equation,输入回归方程,回车,得到的回归估计结果中就有R-squared
quick,group statistics,descriptive statistics,common sample,输入变量名,回车,得到的结果中有sum1年前查看全部
- 用eviews对多元非平稳时间序列进行分析!
用eviews对多元非平稳时间序列进行分析!
样本容量很小,只有98-12年的数据这个幸运的机会1年前1 -
loved1999 共回答了13个问题
|采纳率100%没有办法.时间序列要求较大样本的.
当然,如果要求不是太高,比如不做协整检验,只用普通的回归,可以做一下.
但总的来说,样本太小,影响结论的可靠性.
统计人刘得意1年前查看全部
- 根据eviews写white检验辅助回归的表达式
根据eviews写white检验辅助回归的表达式
表里边不是有一个C 一个X 一个X~2 但是不是有5个解释变量吗?那个是哪个的系数阿gbiea11年前1 -
胖苍蝇 共回答了20个问题
|采纳率80%不清楚楼主的问题,可否详细说来,或者贴个图之类的1年前查看全部
- 用EViews做granger检验的时候选项的 lags填多少?
用EViews做granger检验的时候选项的 lags填多少?
做两个序列之间的格兰杰检验(20年年度数据)
view-granger causality 然后弹出一个对话框 lags to include:___
系统好像默认是2
我发现填1,2,3,4,5,6的结果会差很多,数字再大就开始报错了
这个地方的lags到底应该是多少?
谢谢了!中原早有孜然啦1年前1 -
hanlufeihua 共回答了17个问题
|采纳率94.1%默认2,计算VAR后:view-->lag structure-->lag lengh criteria
结果出来 按多种标准,选出来的最佳滞后阶数,你可从中选一个适合你预期的滞后阶数,重新计算VAR,再granger causality .
这个地方随意性比较大,也是现在大家都说时间序列模型不靠谱的主要原因之一.1年前查看全部
- EVIEWS做ADF检验得出时间序列是1阶单整,那么如何对该序列做1阶拆分?
EVIEWS做ADF检验得出时间序列是1阶单整,那么如何对该序列做1阶拆分?
下一步做协整时,用的是拆分后的序列还是拆分前的?如何做X和Y的最小二乘法,结果怎么看,如何判断?如何构建误差修正模型?dsgdfhjgfj1年前1 -
忘却的音符 共回答了16个问题
|采纳率87.5%1.用差分前的序列数据(x,y);
2.最小二乘:quick——estimate equation中输入:y c x 运行即可
3.结果分析:把回归的残差序列命名为e 命令窗口:series e=resid
对生成的序列e 进行单位根检验,若平稳,即有协整关系;
4.误差修正模型:quick——estimate equation中输入:d(y) c d(x) e(-1)
回归的结果即为误差修正模型.1年前查看全部
- 多元线性回归 我有Y和X1.X2.X3.X4.现在用EVIEWS对Y,X1.X2.X3.X4作了协整检验,确定存在一个协
多元线性回归
我有Y和X1.X2.X3.X4.现在用EVIEWS对Y,X1.X2.X3.X4作了协整检验,确定存在一个协整向量.这说明了什么呢?要存在几个协整向量算是X1.X2.X3.X4都与Y有长期均衡关系呢?skysol1年前1 -
kqinglong 共回答了18个问题
|采纳率88.9%存在协整关系主要是为了做误差修正模型(ECM)用的,ECM可以看出长期均衡关系,只做协整是看不出来的,这方面的书可以参考张晓彤的《计量经济分析》1年前查看全部
- 请问用EVIEWS做多元回归后,F检验和T检验怎么做?其中自由度的n-1,n-k这些的n和k分别是指什么?
dssdsdds1231年前2
-
halisen 共回答了13个问题
|采纳率84.6%多元回归分析会给出F检验和T检验结果的,其中F检验是针对整个模型的,如果检验显著那么说明自变量对因变量能够较好地解释;而T检验是针对单个变量的,如果显著说明单个自变量对因变量有较大影响否则就需要将其踢出模型之外.
自由度n一般是指样本总数,k是指自变量的个数.1年前查看全部
- eviews模型用对数模型的好处
kaizo1年前1
-
这忒狠 共回答了29个问题
|采纳率96.6%1降低异方差的影响
2用对数进行回归后的系数就代表弹性啦1年前查看全部
- 用eviews进行1000名新生儿体重数据的描述统计.(利用均值3000,标准差300的服从正态分布的随机变量模拟)
用eviews进行1000名新生儿体重数据的描述统计.(利用均值3000,标准差300的服从正态分布的随机变量模拟)
这个用eviews怎么做啊?naiboad1年前1 -
茶三 共回答了26个问题
|采纳率88.5%这个需要编程完成的,描述统计是比较简单的
view里面直接就有
我替别人做这类的数据分析蛮多的1年前查看全部
- eviews方程写入我需要研究,FOREX和CR对CPI的影响,利用最小二乘法,做估计,方程应该怎么写呀?
wxplzbwxp1年前1
-
进行干尸的温柔 共回答了22个问题
|采纳率90.9%equation eq01.ls CPI FOREX CR1年前查看全部
- 求助!用Eviews对下列数据进行协整检验和误差修正模型!希望有好心人帮忙!小的感激不尽!
求助!用eviews对下列数据进行协整检验和误差修正模型!希望有好心人帮忙!小的感激不尽!
年份 gdp 用电量
1995 311.24 414842
1996 369.96 447127
1997 408.83 474477
1998 433.39 493008
1999 460.31 546460
2000 524.03 640720
2001 586.73 740499
2002 677.65 885406
2003 823.54 1085492
2004 1002.41 1268263
2005 1159.66 1509403
2006 1346.65 1810517
2007 1585.31 2128890
2008 1815.3 2317449
希望能把过程发到我的邮箱:xiaohua623@yeah.net,万分感激!!诠释视觉1年前1 -
风移影动再动 共回答了16个问题
|采纳率75%进行协整检验之前要先对数据进行单位根检验,只有是同阶单整的时间序列数据,才能进一步进行协整检验,协整检验一般用EG两步法,第一步是回归分析,第二步是对残差的单位根检验,如果残差不存在单位根,就是协整的.对于误差修正模型,需要先建立一个模型,然后进行回归分析,分析它的短期均衡关系.
如果你是在写毕业论文,最好还是自己动手整一下,因为万一答辩的时候老师问到了,也好回答,我是亲身经历,最近刚答辩完.1年前查看全部
- 如何从EViews里面的Johansen检验结果看出协整方程?
如何从EViews里面的Johansen检验结果看出协整方程?
Date:04/30/14 Time:11:21
Sample (adjusted):1983 2012
Included observations:30 after adjustments
Trend assumption:Linear deterministic trend
Series:M N P
Lags interval (in first differences):1 to 1
Unrestricted Cointegration Rank Test (Trace)
Hypothesized Trace 0.05
No.of CE(s) Eigenvalue Statistic Critical Value Prob.**
None * 0.467116 30.53590 29.79707 0.0410
At most 1 0.314106 11.65237 15.49471 0.1744
At most 2 0.011316 0.341410 3.841466 0.5590
Trace test indicates 1 cointegrating eqn(s) at the 0.05 level
* denotes rejection of the hypothesis at the 0.05 level
**MacKinnon-Haug-Michelis (1999) p-values
Unrestricted Cointegration Rank Test (Maximum Eigenvalue)
Hypothesized Max-Eigen 0.05
No.of CE(s) Eigenvalue Statistic Critical Value Prob.**
None 0.467116 18.88352 21.13162 0.1003
At most 1 0.314106 11.31096 14.26460 0.1393
At most 2 0.011316 0.341410 3.841466 0.5590
Max-eigenvalue test indicates no cointegration at the 0.05 level
* denotes rejection of the hypothesis at the 0.05 level
**MacKinnon-Haug-Michelis (1999) p-values
Unrestricted Cointegrating Coefficients (normalized by b'*S11*b=I):
M N P
1.912314 7.897272 7.298349
0.892072 0.329896 -10.51537
4.812426 -4.492027 -26.96774
Unrestricted Adjustment Coefficients (alpha):
D(M) -0.045222 -0.019310 0.008725
D(N) -0.054281 -0.028006 0.001551
D(P) -0.008705 0.010221 0.001037
1 Cointegrating Equation(s):Log likelihood 147.6442
Normalized cointegrating coefficients (standard error in parentheses)
M N P
1.000000 4.129693 3.816501
(1.00692) (2.00876)
Adjustment coefficients (standard error in parentheses)
D(M) -0.086479
(0.03872)
D(N) -0.103802
(0.02980)
D(P) -0.016647
(0.00867)
2 Cointegrating Equation(s):Log likelihood 153.2997
Normalized cointegrating coefficients (standard error in parentheses)
M N P
1.000000 0.000000 -13.32235
(2.75020)
0.000000 1.000000 4.150150
(0.70247)
Adjustment coefficients (standard error in parentheses)
D(M) -0.103704 -0.363500
(0.04194) (0.15708)
D(N) -0.128786 -0.437911
(0.03069) (0.11494)
D(P) -0.007529 -0.065374
(0.00854) (0.03200)jrkia1年前1 -
水狼 共回答了20个问题
|采纳率85%关键看这几行:
None * 0.467116 30.53590 29.79707 0.0410
At most 1 0.314106 11.65237 15.49471 0.1744
At most 2 0.011316 0.341410 3.841466 0.5590
尤其是最后的P值,None后的P是0.04,小于0.05,拒绝原假设,而原假设是None,就是没有一个协整方程,拒绝以了,就表明有.但要知道几个,往下看.
第二行后面的P是0.17,大于0.05,接受原假设,而原假设是最多一个协整方程,因此,分析结束.结果是:存在一个协整方程.
若有帮助,请及时采纳,谢谢!
统计人刘得意1年前查看全部
- Eviews7.2做WLS时weight type应该如何选择,None,std.deviation ,inverse
Eviews7.2做WLS时weight type应该如何选择,None,std.deviation ,inverse variance,
 裤子1791年前1
裤子1791年前1 -
海棠朵朵 共回答了11个问题
|采纳率90.9%none就是退化为一般的ls回归,inverse var和std.dev都是不同的加权方法,就是标准差和方差倒数的意思
我替别人做这类的数据分析蛮多的1年前查看全部
- 谁能帮我看下eviews的检验结果,把每个值的合理取值范围和意义说下,
22781111年前1
-
qingmingc 共回答了15个问题
|采纳率73.3%估计值的标准差是衡量回归系数的稳定性和可靠性的,如果较小说明系数的稳定性较好;
估计值的T值是检验系数是否为零,可查表得到相应的临界值,如果T值大于临界值则系数在对应的显著水平(1%.5%.10%)上是可靠的;
估计值显著性概率值表示在t分布下,t统计量的概率值.在5%显著水平下,如果该概率值低于0.05则说明系数值在统计上是显著的.
R方表示回归的拟合成都.取值范围在0-1之间,越接近1则拟合程度越好;
调整的R方:随着解释变量的增加,R方只会增加不会减少.为了对增加的解释变量进行惩罚,要对R方调整
D-W:衡量回归误差是不是序列相关,该统计量如果严重偏离2,则说明存在序列相关
F统计量用于衡量回归方程整体显著性的假设检验1年前查看全部
- eviews建模型obs Y Y1 Y2 Y3 FDI2002 197.07 56.16 92.28 48.62 444
eviews建模型
obs Y Y1 Y2 Y3 FDI
2002 197.07 56.16 92.28 48.62 44435
2003 200.2 49.29 100.36 50.55 79683
2004 202.02 44.15 98.14 59.72 102187
2005 240.83 42.4 144.45 59.38 115666
2006 274.04 41.53 166.56 65.95 122178
2007 288.8 39.46 180.64 68.7 166228
2008 294.45 36.88 177.38 80.19 135975
这个的最小二乘法为什么哈想不对啊,因果检验也不行的先知的交界1年前1 -
空灵nh 共回答了17个问题
|采纳率94.1%一般序列都是非平稳的,你应该先给他们取个LN吧.这个做可能会对你接下来的建模型有帮助1年前查看全部
- eviews进行残差正态性检验两种方式正态分布怎么不一样?
eviews进行残差正态性检验两种方式正态分布怎么不一样?
Eviews进行残差正态性检验时,一种方法是在回归后的结果页面上点击左上角的view-residual tests-histogragram normal test,得到残差的分布直方图.我试了另一种方式,就是双击resid打开其数据界面,再观察其分布,为什么两者图形分布是不一样的?
 这是view-residual tests-histogragram normal test,得到残差的分布直方图.
这是view-residual tests-histogragram normal test,得到残差的分布直方图.
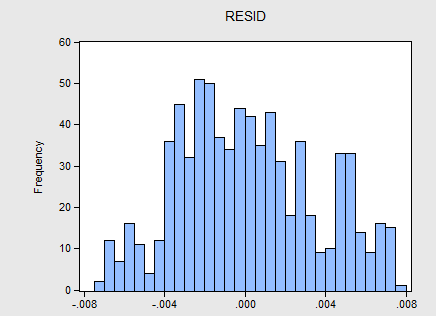 这是我双击resid打开其数据界面,再观察其频率分布的图形.
这是我双击resid打开其数据界面,再观察其频率分布的图形.
两者为何有这样的差别?凌胭1年前1 -
娃哈哈be 共回答了21个问题
|采纳率95.2%你回归后要保存为新的残差序列,然后在做正态检验,不能直接用原始的”resid"序列直接正态检验,这样当然和在回归页面上做不一样1年前查看全部
- 在eviews6中 多元异方差如何修正?
lswwlq1年前1
-
weekley_li 共回答了19个问题
|采纳率78.9%white检验确定确实存在异方差后,使用加权最小二乘法解决.权重,可以是自变量某一个,也可以是额外指定权重变量,也可是自变量的函数.1年前查看全部
- 求高人分析下eviews这张图,紧急!
晓熊宝宝1年前1
-
yq4588 共回答了21个问题
|采纳率95.2%模型中三个解释变量的估计值分别为0.132750,0.746915,0.129291,标准差分别是0.033748,0.049699,0.046890,标准差是衡量回归系数值的稳定性和可靠性的,越小越稳定,三个解释变量的估计值的T值是用于检验系数是否为零的,若值大于临界值则可靠.估计值的显著性概率值(prob)都小于5%水平,说明系数是显著的.R方是表示回归的拟合程度,越接近1说明拟合得越完美.调整的R方是随着变量的增加,对增加的变量进行的“惩罚”.D-W值是衡量回归残差是否序列自相关,如果严重偏离2,则认为存在序列相关问题.F统计值是衡量回归方程整体显著性的假设检验,越大越显著1年前查看全部
- eviews平稳性检验相关问题ADF Test Statistic\x05-2.331191\x05 1% Critic
eviews平稳性检验相关问题
ADF Test Statisticx05-2.331191x05
1% Critical Value*x05-2.6968
x05x05 5% Critical Valuex05x05-1.9602
x05x05 10% Critical Valuex05x05-1.6251
这样t值没有在三个显著性水平下都小于临界值可以吗,黑色早退1年前1 -
乙烯 共回答了27个问题
|采纳率88.9%ADF统计量的值-2.33小于5%水平下的-1.96
我们可以说,在置信水平5%的水平下,拒绝原假设,而在1%水平下接受原假设.1年前查看全部
- eviews中做ADF检验统计值为正数:2.99,而5%显著水平值为负数:-1.97,请问是否通过单位根检验?
eviews中做ADF检验统计值为正数:2.99,而5%显著水平值为负数:-1.97,请问是否通过单位根检验?
ADF检验中比较绝对值大小来判断是否拒绝假设,但是,统计值和显著水平值要同为正数或同为负数吗?aoo07051年前3 -
全心爱COCO 共回答了20个问题
|采纳率90%看ADF检验的伴随概率,如果小于0.05,就拒绝原假设,说明序列是平稳的.否则,无法拒绝原假设,序列非平稳.
如果ADF检验统计值大于各显著水平下的临界值,则序列非平稳.
如果ADF检验统计值小于各显著水平下的临界值,则序列平稳.1年前查看全部
- 在eviews回归分析中Durbin-Watson stat,是检验是否存在自相关?那多少才存在自相关的?结果又有什么作
在eviews回归分析中Durbin-Watson stat,是检验是否存在自相关?那多少才存在自相关的?结果又有什么作用努力发育1年前1
-
tyorz 共回答了23个问题
|采纳率91.3%1.5-2.5之间的话一般不存在自相关1年前查看全部
- 计量经济学中,用eviews回归得系数1.47E-07中E是什么意思
guozhong121年前1
-
怎么会忘了id 共回答了10个问题
|采纳率90%表示1.45×10^-7,这个E表示位置不够,用科学计数法表示数据.1年前查看全部
- eviews自相关系数图 怎样判断拖尾截尾
eviews自相关系数图 怎样判断拖尾截尾
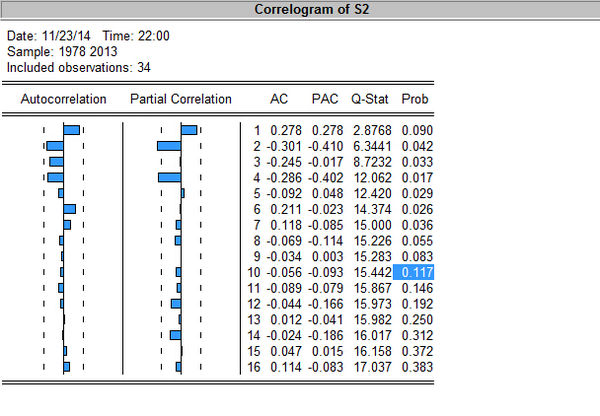
这是做完二阶差分的数据 求大神帮看看拖尾截尾 AR MA 分别作几阶叶子远航1年前1 -
瑶瑶雨 共回答了14个问题
|采纳率92.9%看后面的显著性水平1年前查看全部
- eviews估计结果怎么分析F-statistic值解释什么?以及其他
eviews估计结果怎么分析

F-statistic值解释什么?
以及其他hanbinglengxue1年前1 -
singosong 共回答了14个问题
|采纳率85.7%F值,是模型总体显著性检验的指标,它越大,模型越好.本例中,它下面对应的P值小于0.01,通过了0.01水平的显著性检验,说明模型总体显著.
至于其它,主要的是回归系数的P值,CITYINCOME回归系数对应的P值为0.009,小于0.01,拒绝原假设,说明该回归系数与零的差异显著,即,这个自变量对因变量有显著的影响.
CITYCONS(-1)的系数的P值为0.45,大于0.01,也大于0.05,没有通过检验,说明这个自变量对因变量的影响在统计学意义上不显著.
另一个较重要的是R方,为0.99,接近1,表明拟合优度相当好.1年前查看全部
- 用eviews软件做一元线性回归,如果不加常数项,结果就出现负值,请问这是为什么?
用eviews软件做一元线性回归,如果不加常数项,结果就出现负值,请问这是为什么?
不要跟我说加上常数项就没事了,请阐述原因
victorwang251年前1 -
月满西楼abc 共回答了22个问题
|采纳率86.4%加不加常数项影响的是回归系数计算矩阵的结构
所以不加常数项就出现负值
这是一个计算过程,没有什么特殊原因1年前查看全部
- eviews ARMA(p,q) 模型建立与预测
eviews ARMA(p,q) 模型建立与预测
如果x是一个平稳时间序列ARMA(p,q),用Eviews软件估计ARMA(2,2)的参数,variable 分别为AR(1),AR(2),MA(1),MA(2),对应的Coefficient分别为2,3,4,5,请问这个模型如何书写?写出模型之后又如何预测呢?Sweety珊珊1年前1 -
我很行 共回答了17个问题
|采纳率88.2%p和q阶是代表数列的阶数,也即“εt2 = a0+a1εt-12 +a2εt-22 + …… + aqεt-q2 +ηt t ”数列中类似“a0+a1εt-12”的个数.1年前查看全部
- eviews如何做单位根检验,误差修正模型,蒙特卡洛模拟实验
lwy10111年前1
-
juziedelweiss 共回答了15个问题
|采纳率86.7%先说单位根检验:打开需要检验的序列,在窗口左上角,依次view-unit root test,然后设定检验的参数,确定.
误差修正模型:理论上讲它是VAR模型的特例,在主菜单中quick-estimate var在弹出的对话框中选择vecter error correct设定参数,确定.
蒙特卡罗模拟试验的话,使用交互式操作很难完成,最好使用编程方法,现将我前段时间和朋友交流的一个程序写在下面,它用以模拟线性回归系数的分布:
'Simulation of OLS estimators using MC method
'Objective equation is y=0.3+12*x
'Disturbance N(0,2)
'Repeat 100 times
'(c)2012 by sinxlg1,all rights reserved
wfcreate MC_OLSestimators u 100
scalar rp=1000
scalar c0=0.3
scalar b0=12
scalar dst_var=2
matrix(rp,2) coef_mtx
for !k0=1 to rp
series x_smlt=@runif(20,100)
series dst=dst_var*@rnorm
series y_smlt=c0+b0*x_smlt+dst
equation rg.ls y_smlt=c(1)+c(2)*x_smlt
coef_mtx(!k0,1)=@coefs(1)
coef_mtx(!k0,2)=@coefs(2)
next
freeze(coef_grph) coef_mtx.distplot
freeze(coef_stats) coef_mtx.stats
show coef_grph
show coef_stats
得到效果如下

1年前查看全部

- 求eviews分析,用动态分布滞后模型检验两个序列是否存在协整关系并建立误差修正模型 长期关系是什么?
求eviews分析,用动态分布滞后模型检验两个序列是否存在协整关系并建立误差修正模型 长期关系是什么?

用动态分布滞后模型估计的如上图,
ZC = 112.5857 + 0.2145ZC(-1) + 0.6706SR - 0.21SR(-1) +u
所以ZC与SR的长期关系为ZC = 143.33 + 0.85SR 是这个么?
如果是这个,继续对残差进行单位根检验,得出残差是平稳的,建立误差修正模型,如下结果
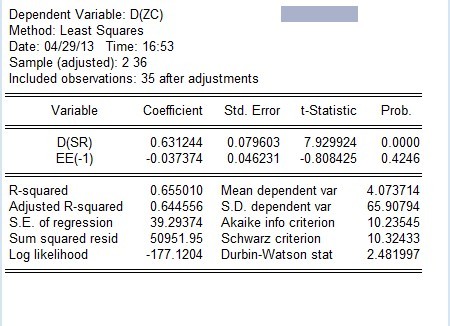
所以误差修正模型为:ΔZC = 0.63ΔSR - 0.04ee(-1)
是这样的么?这个里面ee的P值没有通过检验,这样可以么?
请说明一下其中的长期关系,和最终的误差修正模型湮梦宁1年前1 -
anba010 共回答了14个问题
|采纳率92.9%这个可以做的,但是你需要提供数据
我经常帮别人做这类的数据分析的1年前查看全部
- 计量经济学 用Eviews软件进行回归分析输出结果的意思?
计量经济学 用Eviews软件进行回归分析输出结果的意思?
Dependent Variable:Y
Method:Least Squares
Date:04/20/10 Time:21:59
Sample:2004 2008
Included observations:5
Variable Coefficient Std.Error t-Statistic Prob.
X 6.008856 1.913835 3.139695 0.0517
C -383.3042 408.1060 -0.939227 0.4169
R-squared 0.766676 Mean dependent var 888.3380
Adjusted R-squared 0.688902 S.D.dependent var 200.7918
S.E.of regression 111.9940 Akaike info criterion 12.56394
Sum squared resid 37627.95 Schwarz criterion 12.40772
Log likelihood -29.40985 Hannan-Quinn criter.12.14465
F-statistic 9.857682 Durbin-Watson stat 1.560963
Prob(F-statistic) 0.051676
房地产投资与GDP关系 X表示房 Y表示GDP 急用
不好意思 我问的就是后面这些拟合度什么的含义和合理范围db1891nihao1年前1 -
singing711 共回答了16个问题
|采纳率81.3%1、R-squared与Adjusted R-squared是方程拟合程度的度量,达到0.7已经可以了;
2、Akaike info criterion和Schwarz criterion等位信息量值,用来比较不同的模型,一般值越小越好;
3、Durbin-Watson stat是检验残差自相关的DW经验,一般值在2附件比较理想,你可以再查询具体的DW检验表,得到精确的检验结果;
4、F-statistic和Prob(F-statistic)用来判断你方程的整体显著性,由于是一元回归,和前面X系数的显著性检验是等价的,在10%的显著性水平下,可以认为你的方程是整体显著的.1年前查看全部
- eviews最小二乘法有没有银知道,用eviews做最小二乘法,自变量有多个因素的话要怎么算,直接输入ls 因变量 c
eviews最小二乘法
有没有银知道,用eviews做最小二乘法,自变量有多个因素的话要怎么算,直接输入ls 因变量 c 自变量1 自变量2 自变量3这样的格式么?
还有为啥做单个自变量的时候T统计量是正数,多个一起做了的话这个自变量的T统计量就负了……寻闲行1年前1 -
fwbpkt 共回答了23个问题
|采纳率91.3%是的,可以这样做的
各个因素之间有干扰啊
我替别人做这类的数据分析蛮多的1年前查看全部
- 图来自于eviews中的OLS回归结果,请问应该怎样分析
图来自于eviews中的OLS回归结果,请问应该怎样分析
Dependent Variable:GDP
Method:Least Squares
Date:07/05/13 Time:08:38
Sample:2004 2012
Included observations:9
Variable
Coefficient
Std.Error
t-Statistic
Prob.
C
3.835394
130.9404
0.029291
0.9775
JINCHUKOU
14.94631
2.696153
5.543567
0.0009
R-squared
0.814477
Mean dependent var
687.6456
Adjusted R-squared
0.787974
S.D.dependent var
286.1984
S.E.of regression
131.7839
Akaike info criterion
12.79333
Sum squared resid
121568.9
Schwarz criterion
12.83716
Log likelihood
-55.57000
F-statistic
30.73114
Durbin-Watson stat
1.190546
Prob(F-statistic)
0.000866
 nn寒光1年前1
nn寒光1年前1 -
楚梦泽 共回答了14个问题
|采纳率92.9%R2=0.81,拟合优度不低,说明解释变量可以对被解释变量解释
系数的p值,进出口显著,但是常数项不显著
DW值显示,你这个可能存在一阶自相关1年前查看全部
- eviews求助,garch模型的问题
eviews求助,garch模型的问题

我是要用garch来做股票收益率,但是garch(1.1)或者garch(1.2)得出来的结果P值都有一个大于0.05,
AIC这些都是正数,请问是哪里出错了?要异方差检验吗?fl86231年前1 -
郁闷的mm 共回答了22个问题
|采纳率81.8%ls r c
不用取对1年前查看全部
- eviews结果就解释能否帮忙详细解释下这个结果还行么,t-statistic,F-statistic怎样才算好,好的再
eviews结果就解释
能否帮忙详细解释下这个结果还行么,t-statistic,F-statistic怎样才算好,好的再送50分
看图
 jin苹果1年前1
jin苹果1年前1 -
双差生 共回答了17个问题
|采纳率88.2%结果在哪?T F 统计量 只用测算值 比理论值大就可以了.你把结果写出来才能帮你看呀 用过你用eviews的话 也可以直接观察prop值.这个值越小 说明置信越好.一般小于0.05就可以了.超过0.15 就属于不显著了1年前查看全部
- Eviews中的怀特检验.结果如图,x4,x5,x6,x7为虚拟变量.x1,x2为普通的解释变量.这个结果我需要做加权吗
Eviews中的怀特检验.结果如图,x4,x5,x6,x7为虚拟变量.x1,x2为普通的解释变量.这个结果我需要做加权吗
若做权数是什么怎么做,如果不需要为什么.希望前辈解答加权最小二乘法
 guanshan6151年前1
guanshan6151年前1 -
liufukang 共回答了17个问题
|采纳率88.2%格式:根据检验,nR^2为179.2259 , 自由度为21的 、显著性为5%的临界值 XX (你需要查表看下)
(但是根据你的结果来看) nR^2大,拒绝原假设 ,所以存在异方差.
用加权最小二乘法加权
权重常用的是1/e 1/X X^-1/2
加权重的时候就是一般的回归套路(后两个),不过要在
在工作文件窗口中点QuickEstimate Equation,
选择Options
Weighted LS/TLS 复选框,在Weight 框中输
入分次输入权重
第一个要先输入以下内容,在进行上面的
直接在工作文件窗口中按Genr,在弹
出的窗口中, 在主窗口键入命令如下 e = resid1年前查看全部
- eviews回归结果应该怎样详细分析啊
eviews回归结果应该怎样详细分析啊
y=760.0819+0.316395x+Ut R^2=0.95
T:(10.44) (12.41329) DW=1.233
F统计量约为154(Y表示租金,X表示房价)求大神搭救啊feng29951年前1 -
一曲新词 共回答了25个问题
|采纳率100%变量是显著的
房价对rent有影响的
我替别人做这类的数据分析蛮多的1年前查看全部
- 如何在eviews中检验时间序列数据的平稳性
空中幻想1年前1
-
1943echo 共回答了15个问题
|采纳率93.3%平稳
看PROB值,小于0.05就是平稳1年前查看全部
- 谁能帮我用Eviews做格兰杰因果检验?
谁能帮我用Eviews做格兰杰因果检验?
A是以1993年为基期,而B是具体数值
数据如下:x05
年份 Bx05A
1993x05211.99x05100
1994x05516.2x05124.1
1995x05735.97x05145.32
1996x051050.29x05157.38
1997x051398.9x05170.44
1998x051449.59x05175.21
1999x051546.75x05173.81
2000x051655.74x05171.38
2001x052121.65x05172.07
2002x052864.07x05173.27
2003x054032.51x05171.88
2004x056099.32x05173.94
2005x058188.72x05180.7
2006x0510663.44x05183.95
2007x0515282.49x05186.71
2008x0519460.3x05195.67
2009x0523991.52x05207.21
2010x0528473.38x05205.76aix20042121年前1 -
erttry544 共回答了14个问题
|采纳率100%单位根检验和协整检验要一起做不1年前查看全部
- EVIEWS6.0自相关检验DW2.73,查DW分布表负相关该如何处理?
EVIEWS6.0自相关检验DW2.73,查DW分布表负相关该如何处理?
我采用逐步回归法,有5个自变量,前4个自变量加入都是显著的,第五个自变量加入时前4个都不显著了,只有第五个显著,而第五个自变量加入后DW=2.73,查DW分布表是负相关,由于变量数比较多,使用ar(1)来消除自相关会提示Near singular matrix,用EVIEWS6.0该如何处理呢洱海琥珀1年前1 -
醉血 共回答了22个问题
|采纳率100%共线性可以用逐步回归来消除1年前查看全部
- 利用Eviews回归分析,自变量有8个怎么处理,得到每个的系数、标准差,并进行T检验、F检验和拟合度检验?
肖洒5111年前1
-
心情Frank 共回答了17个问题
|采纳率100%自变量太多啦
控制在5个以内回归结果会比较理想1年前查看全部
- 帮忙分析下eviews中的自相关图
帮忙分析下eviews中的自相关图
请告之下序列自相关显著程度怎么看,序列平稳与否怎么看,Q统计量P值怎么看,是否白噪声怎么看.偏自相关、自相关拖尾、截尾怎么看,应该建立ARIMA(p,1,q)模型参数pq如何确定,
 Baby儿1年前1
Baby儿1年前1 -
桃花眼 共回答了20个问题
|采纳率95%第一列 一阶截尾,q=1
第二列 二阶截尾,p=2
平稳性:在序列中,view——unit root test——可以检查原序列、一阶序列;貌似只有差分平稳后才可以建立ARIMA,就是你p,q中间的1表示1阶差分吧
若你的图是一阶差分的,那么建立方程LS D(X) C AR(2) MA(1),试试
在方程窗口,view——residual test ——Q检验和LM自相关检验,至于P值判断可以搜一下检验的原假设,你设定一个显著性水平,如0.05,P1年前查看全部
- eviews7.2如何做多元线性回归模型的区间预测?
eviews7.2如何做多元线性回归模型的区间预测?
RT,不知道如何算置信区间,求教~·janiffer1年前1 -
青城布衣_小满 共回答了17个问题
|采纳率100%任何一个模型的区间模型都是在单点预测的基础上加上(或减去)置信水平的分位数乘以估计方差,你明白这个思路的话,预测就不难了.eviews中,在得到的回归模型输出窗口上部有“forecast”,点击进去输入你要预测的时间段就能得到最后的结果.1年前查看全部
- 请高手用EViews做一下名义汇率(兑1美元) 8.2783 8.2784 8.277 8.277 8.277 8.27
请高手用EViews做一下
名义汇率(兑1美元)
8.2783
8.2784
8.277
8.277
8.277
8.2768
8.1917
7.9718
7.604
"1999年价格计算的出口值(亿美元)
"
1949.3
2407.77
2498.297
3008.31
3957
5213.84
6468.7
7959.42
9718.44
"1999年价格计算的进口值(亿美元)
"
1657
2174.82
2286.59
2727.16
3727.04
4931.84
5602.75
6501.53
7628.95
检验汇率和出口,汇率与进口的相关性,并说明理由蛤蟆夯1年前1 -
落妖精 共回答了14个问题
|采纳率92.9%分别用 ER 表示名义汇率;EX 表示出口值;IM 表示进口值
下表为EVIEWS计算出的相关系数矩阵
ER ,EX ,IM
ER | 1.000000 ,-0.871707 ,-0.813919
EX | -0.871707 ,1.000000 ,0.992905
IM | -0.813919 ,0.992905 ,1.000000
汇率和出口的相关系数为 -0.871707,即汇率和出口有较强的负相关;
汇率和进口的相关系数为0.992905,即汇率和进口有很强的正相关.
下面是ER关于EX和IM的线性回归结果:
ER = 8.33467522 - 0.000379187592*EX + 0.0003972764046*IM
EX和IM 的t 值 分别为 -5.753858(prob=0.0012);4.671291(prob=0.0034)
括号内是小概率,说明出口和进口对汇率都很显著的影响,只不过影响的方向相反.1年前查看全部
- eviews分析中,时间序列中有大量负数,在对这一时间序列做ADF平稳性检验的时候要对这些负数进行处理吗?
ssx00321年前1
-
hdpagain 共回答了24个问题
|采纳率91.7%不需要做特殊的处理
我替别人做这类的数据分析蛮多的1年前查看全部
- eviews 分析中各个变量间的计算关系
心只有你11251年前1
-
xinyu52115 共回答了14个问题
|采纳率92.9%估计值的标准差是衡量回归系数的稳定性和可靠性的,如果较小说明系数的稳定性较好;
估计值的T值是检验系数是否为零,可查表得到相应的临界值,如果T值大于临界值则系数在对应的显著水平(1%.5%.10%)上是可靠的;
估计值显著性概率值表示在t分布下,t统计量的概率值.在5%显著水平下,如果该概率值低于0.05则说明系数值在统计上是显著的.
R方表示回归的拟合成都.取值范围在0-1之间,越接近1则拟合程度越好;
调整的R方:随着解释变量的增加,R方只会增加不会减少.为了对增加的解释变量进行惩罚,要对R方调整
D-W:衡量回归误差是不是序列相关,该统计量如果严重偏离2,则说明存在序列相关
F统计量用于衡量回归方程整体显著性的假设检验1年前查看全部
大家在问
- 1形容自然环境恶劣的词越多越好,
- 2l'll draw the pictures .l'll write the reports.
- 3the girl is hard to get along with的句式用法
- 4观察下列按顺序排列的等式:a1=1−13,a2=12−14,a3=13−15,a4=14−16,…,试猜想第n个等式(n
- 5以元音音标开头的字母如A,E 一共13个
- 6一幅地图,图上15厘米表示实际距离60千米,这幅地图的比例尺是______,用线段比例尺表示是______.
- 7拔苗助长从表达方式上看,第一层以什么为主,第二层呢?
- 8在签发支票时,5200.50元的汉字大写金额应写成“伍仟贰佰元伍角”为什么错的…不是说中文大写金额以角...
- 9氢氧化铝的加热分解方程式
- 10Her friend Daniel is ____honest boy and he never___lies A.a,
- 1117.18.(17) A (18) D
- 12我们在同一所学校上学译成英语wegoto()
- 13电子商务安全需满足什么条件
- 14画角时要先画一条()线,使量角器的()和射线的()重合,()线和射线重合
- 15(2011•江西)能正确表示下列反应的离子方程式为( )