python 在一个范围内,寻找另一个数字的所有整数倍数,并计算一共有多少个倍数
 念念忘返2022-10-04 11:39:541条回答
念念忘返2022-10-04 11:39:541条回答这个是问题,真心不会做.我用的是python 2.7.要用 for loop
1) 建立程序 count_multiples() which takes 三个非负整数:base,start and stop,prints each integer multiple of base which
occurs between start and stop (including start but not including stop) on a separate line,
and returns the number of multiples found.假如 base = 3,那在start = 9 和stop = 15之间就有2个整倍数,9 和 12,但不包括15.the easiest way to test whether one number is an integer multiple of another is with the % operator.
x05x05x05x05x05x05
x05x05x05x05x05
x05x05x05x05
x05x05x05
x05x05
x05x05x05
x05x05x05x05
x05x05x05x05x05
x05x05x05x05x05x05
x05x05x05x05x05x05x05
2).Write a function user_input_multiples() which takes a single integer input base.This
function will get start and stop values from the user with two calls to raw_input(),call
count_multiples() to determine the number of integer multiples of base between the user
specified start and stop,and then ask again for new start and stop values.The function will
continue asking for new start and stop values until at least one of the following cases occurs:
x05x05x05x05x05x05x05
x05x05x05x05x05x05
x05x05x05x05x05x05x05x05
x05x05x05x05x05x05x05x05x05
The user enters a negative value for start or stop.
x05x05x05x05x05x05x05x05
x05x05x05x05x05x05x05x05
x05x05x05x05x05x05x05x05x05
The user enters a value for stop which is less than the value for start.
x05x05x05x05x05x05x05x05
x05x05x05x05x05x05x05x05
x05x05x05x05x05x05x05x05x05
The function count_multiples() returns zero (eg:there were no multiples between start and stop).
Once the function stops asking for input,it will return the total number of multiples found (the total
over all calls to count_multiples()).Hint:You will
want to use a while loop for this function.
英语有点多,看着有点烦,请见谅.第一部分我已经尽量翻译最主要的举例了.
如果没有时间,给我一个详细的思路或者方向也行.:)
已提交,审核后显示!提交回复
共1条回复
 娃哈哈b315 共回答了11个问题
娃哈哈b315 共回答了11个问题 |采纳率81.8%- def count_multiples(base, start, stop):
result=[]
for item in range(start,stop):
if item % base ==0:
result.append(item) - 1年前
相关推荐
- 能帮我解释下这个PYTHON怎么运算的么
kk乐1年前1
-
zhouyang710 共回答了17个问题
|采纳率100%就是统计频度,los是一个tuple或者list类的对象,unique是去除了重复的,frequency是对应于unique的频度统计.
遍历los,如果当前元素不在unique中,unique和frequency都添加一位,前者添加0,后者添加当前元素. 对于当前元素,由于不管第一次遇到或者第n次遇到,都找出在unique中的索引.然后把frequency中加1
最后result中每个元素就是无重复的los中的元素和其频度的二元list1年前查看全部
- Python3.4 编程问题求帮助啊!!!!!
Python3.4 编程问题求帮助啊!!!!!
求大神告诉下下面这个问题要怎么写啊!!!大感谢啊!!!刚学python的表示头发都要掉光了啊!!!
Every rational number between 0 and 1 can be written in decimal form either as a fixed decimal or as a decimal which repeats after some number of digits. For example:
1/2 = 0.5 (terminates)
1/8 = 0.125 (terminates)
1/3=0.333333333.... (ie just repeating 3's after the decimal)
1/6=0.166666666.....(ie a 1 followed by repeating 6's after the decimal)
1/7=0.142857142857.... (ie 142857 repeating after the decimal)
1/17=0.058823529411764705882352941176470588235294117647...
(ie 0588235294117647 repeating after the decimal).
Define a function called get_digits(n,d) which computes the digits of the decimal representation of the proper fraction n/d where you can assume that the numerator n is less than the denominator d.
The function should return a list consisting of two lists of digits. The first list is of all the digits that come after the decimal point which are NOT repeated (if any). The second list contains the digits that ARE repeated (if any).
For example:
get_digits(1,2) --> [[5],[]]
get_digits(1,3) --> [[],[3]]
get_digits(1,8) --> [[1,2,5],[]]
get_digits(1,6) --> [[1],[6]]
get_digits(1,17) --> [[],[0,5,8,8,2,3,5,2,9,4,1,1,7,6,4,7]]
snail62261年前0 -
共回答了个问题
|采纳率
- python练习题This question is about Fibonacci number.For your in
python练习题
This question is about Fibonacci number.For your information,the Fibonacci sequence is as follows:
0,1,1,2,3,5,8,13,21,34,55,89,144,233,...
x05x05x05x05x05
That is,the first two Fibonacci numbers are 0 and 1,each Fibonacci number after that is equal to the sum of the
two numbers that precede it.For example,the third Fibonacci number is equal to the sum of the first and
second number,the fourth number is equal to the sum of the second and third number,and so on ...
x05x05x05x05x05
Write a program that asks the user to enter a positive integer n,then your program should print/output in one
line the Fibonacci sequence up to n.
For example,if n is 100,your program should output 0,1,1,2,3,5,8,13,21,34,55,89,
If n is 8,your program should output 0,1,1,2,3,5,8,
不好意思因为才学只能用 条件命令和loop郝振江1年前1 -
永远忘记xy 共回答了27个问题
|采纳率85.2%up_limit = int(input("please enter a positive integer:"))
print(" the Fibonacci sequence up to %d:" %(up_limit))
t1,t2=0,1
a=[t1,t2]
while 1:
t1,t2=t2,t1+t2
if t2<=up_limit:
a.append(t2)
else:
break
print(','.join(str(i) for i in a))1年前查看全部
- 想问下python字典排序 怎么才能先按照值大小降序排列 若值相同 再按照键的字母顺序排呢?
dm3151年前1
-
风霖心 共回答了17个问题
|采纳率88.2%暂时只能想到这样的,结果是排序后的键列表.
d = {'a':3,'c':4,'b':3,'d':2,'f':4,'e':2}
result = []
keys = sorted(d,key=lambda k:d[k])
for k in keys:
if not result:
result.append(k)
elif d[k] == d[result[-1]] and k < result[-1]:
result.insert(len(result) - 1,k)
else:
result.append(k)
print result1年前查看全部
- python编程题目要求:Write a program to read through the mbox-short.
python编程
题目要求:Write a program to read through the mbox-short.txt and figure out the distribution by hour of the day for each of the messages. You can pull the hour out from the 'From ' line by finding the time and then splitting the string a second time using a colon.
From stephen.marquard@uct.ac.za Sat Jan 5 09:14:16 2008
Once you have accumulated the counts for each hour, print out the counts, sorted by hour as shown below. Note that the autograder does not have support for the sorted() function.

追上你啦抱抱1年前1 -
baoweizuguo 共回答了20个问题
|采纳率95%我晕.....编译软件 都不会自己搜索下载 还学P的编程啊?? python 最新是3.X 3.X和2.X 有一些语法区别1年前查看全部
- python 如何判断整除
wellge11年前1
-
yeguozi5 共回答了22个问题
|采纳率77.3%x = 5
y = 2
if x%y == 0:
pass # 当x能够整除y时,执行xx操作1年前查看全部
- 求python大神帮我做下面几道题
求python大神帮我做下面几道题
2 Write aprogram with
a graphical user interface that approximates the value of p by summing the terms of
this series: 4/1-4/3+4/5-4/7+4/9-4/11+… The program should prompt the user for
n, the number of terms to sum and then output the sum of the first n terms of
this series.
3 Word count: The program should accept afile name as input and then print three numbers showing the count of lines,
words, and characters in the file.
7 A certain CSprofessor gives 100-point exams that are graded on the scale 90–100:A, 80–89:B,
70–79:C, 60–69:D,<60:F. Write a program that accepts exam scores from a file
and outputs the corresponding grade to
another file. The format of the input file should be “name: score” and the
format of the output file is “name: score grade”. Decision structures can not be used here.
4 Write a length conversion program with a graphicaluser interface (from inch(寸) to cm)telepathies1年前1 -
羽田輪回 共回答了23个问题
|采纳率100%def Q_2(): n = input("Enter n:") term = input("Enter number of terms to sum: ") s = 0 for i in range(term): s += n/(2.0*i+1) print s def Q_3(): name = input("Enter a file name:") f = open(name,'r') lines = 0 char = 0 words = 0 for line in f: line = line.strip().split() lines += 1 for word in line: words += 1 chars +=len(word) f.close() print lines print words print chars def Q_4(): n = input("Enter length in inch: ") print n,"inches = ",n * 2.54,"cm" def Q_7(): name = input("Enter a file name:") f = open(name,'r') w = open("anotherFile.txt",'w') for line in f: line = line.strip().split() name = line[0][:-1] score = int(line[1]) if score >= 90: g = "A" elif score >=80: g = "B" elif score >=70: g = "C" elif score >=60: g = "D" else: g = "F" w.write(name+":",g) w.write("n") f.close() w.close() 写了半天,多给点分吧1年前查看全部
- python英文题目求解答!~~~~
python英文题目求解答!~~~~
Given dictionaries, d1 and d2, create a new dictionary with the following property: for each entry (a, b) in d1, if a is not a key of d2 (i.e., not a in d2) then add (a,b) to the new dictionary for each entry (a, b) in d2, if a is not a key of d1 (i.e., not a in d1) then add (a,b) to the new dictionary
For example, if d1 is {2:3, 8:19, 6:4, 5:12} and d2 is {2:5, 4:3, 3:9}, then the new dictionary should be {8:19, 6:4, 5:12, 4:3, 3:9}
Associate the new dictionary with the variable d3
帅到空前绝后1年前1 -
把卷临风 共回答了11个问题
|采纳率100%def new_dict(dict1, dict2):
newdict = {}
newdict.update(dict1)
newdict.update(dict2)
d = newdict.copy()
for i in d.iterkeys():
if dict1.has_key(i) and dict2.has_key(i):
newdict.pop(i)
return newdict1年前查看全部
- python 输入一个正整数后,判断含有几个奇数数字和偶数数字
Colorlean1年前1
-
Aineen 共回答了21个问题
|采纳率95.2%con = { }
data = raw_input( 'input:' )
con[ 'singular' ] = len( [ x for x in data if int( x ) % 2 ] )
con[ 'even' ] = len( data ) - con[ 'singular' ]
print( con )1年前查看全部
- 求python3问题完成啊class Rectangle: """ A rectangle with a width a
求python3问题完成啊
class Rectangle:
""" A rectangle with a width and height. """
def __init__(self, w, h):
""" (Rectangle, number, number)
Create a new rectangle of width w and height h.
>>> r = Rectangle(1, 2)
>>> r.width
1
>>> r.height
2
"""
self.width = w
self.height = h
def area(self):
""" (Rectangle) -> number
Return the area of this rectangle.
>>> r = Rectangle(10, 20)
>>> r.area()
200
"""
tonycycu1年前1 -
ll杏 共回答了23个问题
|采纳率82.6%太简单,我都差点不好意思回答了。def area(self):
""" (Rectangle) -> number
Return the area of this rectangle.
>>> r = Rectangle(10, 20)
>>> r.area()
200
"""
return self.width * self.height1年前查看全部
- 有关PYTHON的计算问题>>>a=3>>>b=4>>>b/(2+a)>>>0>>>b/(2.0+a)>>>5只要是除法
有关PYTHON的计算问题
>>>a=3
>>>b=4
>>>b/(2+a)
>>>0
>>>b/(2.0+a)
>>>5
只要是除法必须得是浮点数?vivan20081年前1 -
四月_软语 共回答了16个问题
|采纳率87.5%你最后那个b/(2.0+a)结果怎么是5啊?正确的应该是如下:
>>> a = 3
>>> b = 4
>>> b/(2+a)
0
>>> b/(2.0+a)
0.80000000000000004
之所以b/(2+a)的结果是0,是因为b是整数,(2+a)也是整数,所以整数除整数结果还是整数,自然就把小数点给去掉了;而b/(2.0+a)的结果是0.80000000000000004,是因为(2.0+a)是浮点数,当整数遇到浮点数时,最后结果就要是浮点数,这是规定,所以结果是0.80000000000000004.1年前查看全部
- 懂Python的朋友麻烦过来看看! 嗯……这个是要写一个函数,要求算出购物清单里东西的价钱(这个函数要适用于所有的lis
懂Python的朋友麻烦过来看看!
嗯……这个是要写一个函数,要求算出购物清单里东西的价钱(这个函数要适用于所有的list,而不仅仅是上面那个list)大概就是这样的,我英语不太好,可能对题目理解不到位,左边栏是题目,有需要可以看看.希望哪位大神能帮我解决下,谢谢!

附上原码:(注释后面是我自己写的,注释前面是题目给的)
shopping_list = ["banana", "orange", "apple","pear"]
stock = {
"banana": 6,
"apple": 0,
"orange": 32,
"pear": 15
}
prices = {
"banana": 4,
"apple": 2,
"orange": 1.5,
"pear": 3
}# Write your code below!
def compute_bill(food):
total = 0
for food in shopping_list:
total = total + prices[food]
return totaljerry1341年前1 -
wenchangjuanke 共回答了21个问题
|采纳率90.5%你好:
你自己已经写好了;
只不过再加一些,判断语句就行了:
像try.except;等
或者说我没理解好.1年前查看全部
- 英语翻译本文主要对蟒蛇(Python molurus Linnaeus)的消化、呼吸、循环和尿殖系统的形态结构特征作初步
英语翻译
本文主要对蟒蛇(Python molurus Linnaeus)的消化、呼吸、循环和尿殖系统的形态结构特征作初步报道.发现蟒蛇的胰脏、肝脏、肺脏的形态结构具有一定的特殊性,如蟒蛇的胰脏呈三角形并有分节小叶,肝脏为一叶,右肺比左肺长,这与有关学者的相关报道不尽一致.艾克斯卡力巴1年前1 -
天若有缘 共回答了20个问题
|采纳率95%This paper,the python (Python molurus Linnaeus) of the digestive,respiratory,circulatory and urogenital systems form a preliminary structure report.Python found in the pancreas,liver,lung morphology has some special.A serpent's the dirty triangular in section and section,the lobules,Liver as a leaf,right lung than the left lung long ,This with the relevant reports are not unanimous1年前查看全部
- python 的问题 >>>t = (1,2,3,4,5,4,6,4,4)
python 的问题 >>>t = (1,2,3,4,5,4,6,4,4)
>>>t.index(4,4)
5
其中t.index(4,4)是什么意思,为什么返回5值xxj1471年前1 -
cezz1330576 共回答了18个问题
|采纳率88.9%你好:
第一个参数是你要查找的元素,就是你想要找谁
第二个参数是:从那个位置开始(从0计数)
第三个参数是:结束的位置1年前查看全部
- python的list16. all_pairs(xs,ys). Create and return a list of
python的list
16. all_pairs(xs,ys). Create and return a list of all possible pairs from values in xs and values in ys. The
order of elements is important – all of the pairs of xs's first element must appear before all pairs
involving xs's second element; similarly, when pairing with a specific element from xs, these pairs must
include ys's elements in the same order as original. An example probably shows this best:
• allowed assumptions:
i. xs is a list of values. It might be empty.
ii. ys is a list of values. It might be empty.
• example: all_pairs([1,2,3], ['a','b']) ===> [(1,'a'),(1,'b'),(2,'a'),(2,'b'),(3,'a'),(3,'b')]
→ note all the (1,…) pairs are first, and that they include (1,'a'( before (1,'b'). There's only one
correct answer for this function as defined.
• The original lists must not be modified.
• Note – this is not the same as zip! zip([1,2,3], ['a','b']) ===> [(1,'a'),(2,'b')].
17.stringify_pairs(pairs). Given a list of pairs, construct and return a new list by calling str() on each of
the two values in a pair, concatenating those results together, and adding into your new list at the same
index as the original pair from the original list.
• allowed assumptions:
i. pairs will be a list of 2-tuples. It might be empty.
• example: stringify_pairs([(1,"hi"),(True,False),(3,4)]) ===> ['1hi', 'TrueFalse', '34']
• The original list passed in must not be modified.
lusie02301年前1 -
00点点 共回答了19个问题
|采纳率94.7%16.
def all_pairs(xs,ys):
xy_list=[]
for x in xs:
for y in ys:
xy=(x,y)
xy_list.append(xy)
return(xy_list)
all_pairs([1,2,3], ['a','b'])
17.
def stringify_pairs(pairs):
xystr_list=[]
for xy in pairs:
(x, y)=xy
xystr=str(x)+str(y)
xystr_list.append(xystr)
return(xystr_list)
stringify_pairs([(1,"hi"),(True,False),(3,4)])1年前查看全部
- python3问题求完成class Circle: """ A circle with a radius. """ de
python3问题求完成
class Circle:
""" A circle with a radius. """
def __init__(self, r):
""" (Circle, number)
Create a circle with a radius r.
>>> c = Circle(10)
>>> c.radius
10
"""
for_here1年前1 -
10jb 共回答了15个问题
|采纳率86.7%class Circle:
""" A circle with a radius. """
def __init__(self, r):
""" (Circle, number)
Create a circle with a radius r.
>>> c = Circle(10)
>>> c.radius
10
"""
self.radius = r
def tester():
c = Circle(10)
print c.radius
if __name__ == "__main__":
tester()1年前查看全部
- python中 a = '%-*s%*s'
python中 a = '%-*s%*s'
我是问中间的*是什么意思?e_jerry1年前1 -
yobboy1 共回答了24个问题
|采纳率87.5%*表示输出时字符所占的宽度.在'%.*s%*.s'%(2, "abce", 3, "324223")这个例子中,第一个*表示输出的字符所占的宽度为2,输出的字符对象是‘abcd’,但由于宽度制定为2,所以只会输出‘ab’.同理,第二个*表示输出的字符所占宽度为3,故而输出‘324’.1年前查看全部
- PYTHON round Forthis problem,we'll round an int value up to
PYTHON round
For
this problem,we'll round an int value up to the next multiple of 10 if
its rightmost digit is 5 or more,so 15 rounds up to 20.Alternately,
round down to the previous multiple of 10 if its rightmost digit is less
than 5,so 12 rounds down to 10.Given 3 ints,a b c,return the sum of
their rounded values.To avoid code repetition,write a separate helper
"def round10(num):" and call it 3 times.
Example Output:round_sum(16,17,18) → 60round_sum(12,13,14) → 30round_sum(6,4,4) → 10g0co1年前1 -
在那个地方 共回答了13个问题
|采纳率92.3%$ python
Python 2.7.3 (default, Jan2 2013, 16:53:07)
[GCC 4.7.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> def round_sum(*args):
...return sum(map(lambda x: round(x, -1), args))
...
>>> round_sum(16, 17, 18)
60.0
>>> round_sum(12, 13, 14)
30.0
>>> round_sum(6, 4, 4)
10.0
>>>1年前查看全部
- python2.6中的os.path.walk() 对应 python3.2里哪个函数
xcvkoaisdufoapsi1年前1
-
zg5700 共回答了28个问题
|采纳率89.3%os.walk1年前查看全部
- python import 和 from XX import * 的区别
python import 和 from XX import * 的区别
我import了一个socket模块,运行的时候说是没有AF_INET 这个族.于是 把import socket改成了 from socket import * 于是就运行成功了.这两者有区别吗?Deloitte_hero1年前1 -
lianghao 共回答了18个问题
|采纳率94.4%import socket的话
要用socket.AF_INET
因为AF_INET这个值在socket的名称空间下
from socket import*
是把socket下的所有名字引入当前名称空间1年前查看全部
- python字典列表和列表字典本人python新手想问下:a=[]b={'name':'fokil'}a.append(
python字典列表和列表字典
本人python新手想问下:
a=[]
b={'name':'fokil'}
a.append(b.copy())
和
a={'name':[]}
a['name'].append('fokil')
这两种方式的不同和各自的适用范围,举例说明
我知道两种的不同但不懂的怎么用语言表达,另外不太清楚它们的适用面,本话题纯技术讨论nancy_li_21年前1 -
五合堂 共回答了13个问题
|采纳率84.6%最本质的区别:第一种方法得出的a是列表,而第二种的a是字典
用python语句表达来看就是:
1.type(a) == list
2.type(a) == dict
在交互式界面下显示:
第一种:
>>> a
[{'name':'fokil'}]
此时a是一个列表,他具有列表的一切方法和属性,但不具备任何字典的方法和属性.列表可以有N个元素,元素的类型是任意的,与列表本身无关.而此时的a有一个元素,该元素是一个字典——但这并不代表整个列表a带有任何字典的性质.明白?
第二种:
>>> a
{'name':['fokil']}
同上,此时a是一个字典,具有字典的一切方法和属性,但不具备任何列表的方法和属性.字典可以有N个元素,每个元素由一对key和内容的组合构成.key可以是任何单一对象的类型(不能是列表或字典——但可以是元组.当然,还可以是数字、字符/字符串,甚至是文件对象),而key对应的内容则可以是任意类型的.在此时,a中只有一个元素,key是一个字符串,而内容则是一个含有一个字符串元素的列表——同样,这不意味着a具有任何的列表性质
总而言之,严格的讲:没有“字典列表”或“列表字典”这种概念
只有一个列表,他包含的元素的类型是字典——当然,列表中的元素可以是不同类型的,譬如:
a = [1, 'test', [2,3,4], {'name':'fokil'}]
同理,只有一个字典,他包含的元素中的一部分是列表(当然,key部分不可能是列表).当然,也有可能是不同类型的元素:
a = {1:'b',(1,2,3):[4,5,6],'test':{'test2':['test3']}}1年前查看全部
- python语法分析问题,这是什么问题,怎么改啊
python语法分析问题,这是什么问题,怎么改啊
python2.7.4
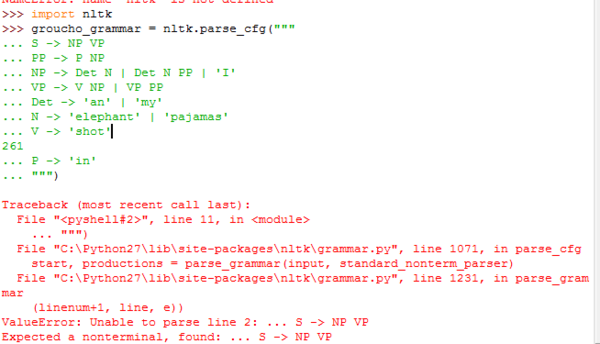
暖暖阳光83011年前1 -
折翅再飞 共回答了24个问题
|采纳率87.5%没有用过nltk这个机器学习的库.不过从语法解析上看.你的格式不对.我略略查了一下,它的语法应该是这样子S -> 'NP' | 'VP'PP -> 'P' | 'NP' 你修改一下看看.另外它的noterminals似乎是一个特殊含义.不是种换行符.下面是一个较完整的示例-def cfg_demo():
"""
A demonstration showing how C{ContextFreeGrammar}s can be created and used.
""" from nltk import nonterminals, Production, parse_cfg # Create some nonterminals
S, NP, VP, PP = nonterminals('S, NP, VP, PP')
N, V, P, Det = nonterminals('N, V, P, Det')
VP_slash_NP = VP/NP print 'Some nonterminals:', [S, NP, VP, PP, N, V, P, Det, VP/NP]
print ' S.symbol() =>', `S.symbol()`
print print Production(S, [NP]) # Create some Grammar Productions
grammar = parse_cfg("""
S -> NP VP
PP -> P NP
NP -> Det N | NP PP
VP -> V NP | VP PP
Det -> 'a' | 'the'
N -> 'dog' | 'cat'
V -> 'chased' | 'sat'
P -> 'on' | 'in'
""") print 'A Grammar:', `grammar`
print ' grammar.start() =>', `grammar.start()`
print ' grammar.productions() =>',
# Use string.replace(...) is to line-wrap the output.
print `grammar.productions()`.replace(',', ',n'+' '*25)
print print 'Coverage of input words by a grammar:'-def cfg_demo():
"""
A demonstration showing how C{ContextFreeGrammar}s can be created and used.
"""
from nltk import nonterminals, Production, parse_cfg
# Create some nonterminals
S, NP, VP, PP = nonterminals('S, NP, VP, PP')
N, V, P, Det = nonterminals('N, V, P, Det')
VP_slash_NP = VP/NP
print 'Some nonterminals:', [S, NP, VP, PP, N, V, P, Det, VP/NP]
print ' S.symbol() =>', `S.symbol()`
print
print Production(S, [NP])
# Create some Grammar Productions
grammar = parse_cfg("""
S -> NP VP
PP -> P NP
NP -> Det N | NP PP
VP -> V NP | VP PP
Det -> 'a' | 'the'
N -> 'dog' | 'cat'
V -> 'chased' | 'sat'
P -> 'on' | 'in'
""")
print 'A Grammar:', `grammar`
print ' grammar.start() =>', `grammar.start()`
print ' grammar.productions() =>',
# Use string.replace(...) is to line-wrap the output.
print `grammar.productions()`.replace(',', ',n'+' '*25)
print
print 'Coverage of input words by a grammar:'- from nltk import nonterminals, Production, parse_cfg # Create some nonterminals S, NP, VP, PP = nonterminals('S, NP, VP, PP') N, V, P, Det = nonterminals('N, V, P, Det') VP_slash_NP = VP/NP print 'Some nonterminals:', [S, NP, VP, PP, N, V, P, Det, VP/NP] print ' S.symbol() =>', `S.symbol()` print print Production(S, [NP]) # Create some Grammar Productions grammar = parse_cfg(""" S -> NP VP PP -> P NP NP -> Det N | NP PP VP -> V NP | VP PP Det -> 'a' | 'the' N -> 'dog' | 'cat' V -> 'chased' | 'sat' P -> 'on' | 'in' """) print 'A Grammar:', `grammar` print ' grammar.start() =>', `grammar.start()` print ' grammar.productions() =>', # Use string.replace(...) is to line-wrap the output. print `grammar.productions()`.replace(',', ',n'+' '*25) print print 'Coverage of input words by a grammar:' print grammar.covers(['a','dog']) print grammar.covers(['a','toy']) toy_pcfg1 = parse_pcfg(""" S -> NP VP [1.0] NP -> Det N [0.5] | NP PP [0.25] | 'John' [0.1] | 'I' [0.15] Det -> 'the' [0.8] | 'my' [0.2] N -> 'man' [0.5] | 'telescope' [0.5] VP -> VP PP [0.1] | V NP [0.7] | V [0.2] V -> 'ate' [0.35] | 'saw' [0.65] PP -> P NP [1.0] P -> 'with' [0.61] | 'under' [0.39] """) toy_pcfg2 = parse_pcfg(""" S -> NP VP [1.0] VP -> V NP [.59] VP -> V [.40] VP -> VP PP [.01] NP -> Det N [.41] NP -> Name [.28] NP -> NP PP [.31] PP -> P NP [1.0] V -> 'saw' [.21] V -> 'ate' [.51] V -> 'ran' [.28] N -> 'boy' [.11] N -> 'cookie' [.12] N -> 'table' [.13] N -> 'telescope' [.14] N -> 'hill' [.5] Name -> 'Jack' [.52] Name -> 'Bob' [.48] P -> 'with' [.61] P -> 'under' [.39] Det -> 'the' [.41] Det -> 'a' [.31] Det -> 'my' [.28] """)1年前查看全部
- python文本处理问题有一个文本a.txt,中间有10行12345678910现在要求将中间的4-8行抽取出来存到b.
python文本处理问题
有一个文本a.txt,中间有10行
1
2
3
4
5
6
7
8
9
10
现在要求将中间的4-8行抽取出来存到b.txt中,速度尽可能快。
xueli213141年前0 -
共回答了个问题
|采纳率
- 求python大神解答def get_poem_lines(poem):r""" (str) -> list of st
求python大神解答
def get_poem_lines(poem):r""" (str) -> list of str Return the non-blank,non-empty lines of poem,with whitespace removed from the beginning and end of each line.>>> get_poem_lines('The first line leads off,nnn' ...+ 'With a gap before the next.nThen the poem ends.n') ['The first line leads off,','With a gap before the next.','Then the poem ends.'] """不会写了
def get_poem_lines(poem):
r""" (str) -> list of str
Return the non-blank,non-empty lines of poem,with whitespace removed
from the beginning and end of each line.
>>> get_poem_lines('The first line leads off,nnn'
...+ 'With a gap before the next.nThen the poem ends.n')
['The first line leads off,','With a gap before the next.','Then the poem ends.']
"""
上面那个有点乱 补个清楚的~cyllmhllysh1年前1 -
fjkfjfff 共回答了16个问题
|采纳率93.8%import re
def get_poem_lines(poem):
return re.split(r's*n+s*', poem.strip())1年前查看全部
- 老师布置Python的作业,Write the following program in python (Support
老师布置Python的作业,
Write the following program in python (Support course outcome 4)
· The program is a game of dice with the user composed
of three rounds.
· In each round,throw the pair of dice for the computer
and the user:
o Show the
value of each die and the total of both the dice.
o Display a
message that indicates who won this round.
· After the three rounds,display the winner of the
game.xiaotianlang1年前1 -
flying626 共回答了17个问题
|采纳率88.2%import random
usernum=0
computernum=0
for i in range(3):
input("----------------------------------n请按回车键投骰子")
num1=random.randint(1,6)
num2=random.randint(1,6)
tmpall1=num1+num2
print("你投的点数为"+str(num1)+"和"+str(num2)+",总数是"+str(tmpall1))
print("计算机开始投骰子...")
num3=random.randint(1,6)
num4=random.randint(1,6)
tmpall2=num3+num4
print("计算机投的点数为"+str(num3)+"和"+str(num4)+",总数是"+str(tmpall2))
if tmpall1>tmpall2:
print("你赢了本局")
elif tmpall1
else:
print("双方平局")
usernum=usernum+tmpall1
computernum=computernum+tmpall2
if usernum>computernum:
print("#########################n你赢了比赛")
elif usernum
else:
print("#########################n双方打平")看看是不是你要的1年前查看全部
- python中,{u'last_running_time': u'2014-07-01 17:22:15'}前面的u是什
python中,{u'last_running_time': u'2014-07-01 17:22:15'}前面的u是什么意思?
另外还有(0, u'', u'')是什么结构
linda_swust1年前1 -
kennyy520 共回答了28个问题
|采纳率92.9%我没记错的话 u是Unicode的意思 表面这个字符串是用Unicode编码的
{u'last_running_time':u'2014-07-01 17:22:15'}
这应该是一个 字典
key是字符串
与之对应的value也是个字符串 而且这两个字符串都是用Unicode编码1年前查看全部
- PYTHON里有没有和FORTRAN 里 NINT 函数等价的函数?
PYTHON里有没有和FORTRAN 里 NINT 函数等价的函数?
或者其他替代算法.三叶草在20061年前1 -
ofzerg 共回答了18个问题
|采纳率88.9%NINT是四舍五入取整
在python中用round直接完成.
算法上其实是加0.5后再截尾取整
3.4 +0.5得3.9 ...截尾得3
3.6 +0.5得4.1 ...截尾得41年前查看全部
- python 中的数学函数 math.exp() math.sin() math.cos() math.e() 求大虾.
python 中的数学函数 math.exp() math.sin() math.cos() math.e() 求大虾...hh的浪人1年前1
-
daokeray 共回答了19个问题
|采纳率89.5%math.exp() - 自然指数函数 e^x
math.sin() - 正弦函数 sin(x)
math.cos() - 余弦函数 cos(x)
math.e - 数学自然数 = 2.71828.1年前查看全部
- python 生成随机数据 验证算法
python 生成随机数据 验证算法
非程序员,只是想用Python随机生成数据以验证一个简单算法的可行性,算法中有p和t两个变量(比如:s=p*t),试着用for语句,但是只想到了嵌套,于是在p和t各取十个值就排列组合出了一百个结果【比如for p in (2,3)嵌套for t in (3,4),在前述方程中就有了2*3,2*4,3*3,3*4这四个答案,但是我不想要这么多相同数】,想要p和t完全随机组合的,这样较少的结果就可以获得足够的参考数.但是编程能力还不够,不知道怎么实现,求程序员大大的帮助!QQ的nn1年前1 -
逆行虫虫 共回答了15个问题
|采纳率80%这个简单.假设你要N个p t组合,p 和 t的范围是 [pmin,pmax],[tmin,tmax].:
import random
N = 100
pmin = 0
pmax = 1000
tmin = 0
tmax = 100
r = random.Random()
r.seed() #刷新随即数种子
for i in range(N)
p = r.randint(pmin,pmax)
t = r.randint(rmin,rmax)
s = p*t
print p,t,s
可以把N pmin pmax tmin tmax,设置为你需要的参数.1年前查看全部
- 如何用python的while loop来确定出一句话的前三个space的位置?
如何用python的while loop来确定出一句话的前三个space的位置?
Write a program that reports the first three occurrences of a space,using a while loop.
Sample run:
Enter a string:I am fine.How are you?
There’s a space in position 1.
There’s a space in position 4.
There’s a space in position 10.天崖人家1年前1 -
pat66 共回答了23个问题
|采纳率91.3%程序如下,使用while(i1年前查看全部
- python 计算x^n,n为正整数,要求程序执行的乘法次数尽量少
python 计算x^n,n为正整数,要求程序执行的乘法次数尽量少
这是怎么个题!x**n不就好了!=-=咔通Micky01年前1 -
headtop4 共回答了18个问题
|采纳率88.9%用加法呗 字数1年前查看全部
- Python,在一个图像中找最大的Y值并返回该值对应的X
Python,在一个图像中找最大的Y值并返回该值对应的X
Python
比如现在有一个一些点的Y值是【1,2,3,4,5,6】,他们分别对应X值为【0,1,2,3,4,5】,想用PHTHON中找出这些点中Y值最大的点并且返回给我该最大点对应的X值为好i阿附近的1年前1 -
烟灰依旧 共回答了18个问题
|采纳率100%y = [1, 2, 3, 4, 6, 7]
x = [2, 4, 6, 2, 6, 3]
print x[y.index(max(y))]1年前查看全部
- python问题,数字排列,只会简单的数字排列,题目上那个需要根据pseudocode,
python问题,数字排列,只会简单的数字排列,题目上那个需要根据pseudocode,
Write a program that sorts a list of numbers using the bubble sort algorithm.Convert
the following pseudo code into Python code.
Pseudocode
ASSIGN a list called 'values'
swapped = True
WHILE swapped
DO
swapped = False
FOR i=1 to length of values
IF values[i-1] > values[i] THEN
SWAP values[i-1] and values[i]
swapped = True
END IF
END FOR
END WHILE
DISPLAY values
这是准确的Pseudocode
 梁西皮1年前3
梁西皮1年前3 -
卖rr的老鼠 共回答了19个问题
|采纳率94.7%Pseudocode是伪代码的意思,题意是让你用Python把这段伪代码的逻辑实现出来#!/usr/bin/env pythondef swap(alist,index1,index2):tmp = alist[index1]alist[index1] = alist[index2]alist[index2] = tmpdef bubble_so...1年前查看全部
- 加了#!/usr/bin/env python2.6 为什么还是有语法错误:with open(file,'r') as
加了#!/usr/bin/env python2.6 为什么还是有语法错误:with open(file,'r') as fp:^ SyntaxError:inv
有一个叫build.py的文件中加了#!/usr/bin/env python2.6
为什么还是有语法错误:
with open(file,'r') as fp:
^ SyntaxError:invalid syntax
python --version结果是
Python 2.6.8
/usr/local/bin/python2.6 build.py 不会出现语法错误joejoeyy1年前1 -
htclo 共回答了22个问题
|采纳率100%把你的shebang改成“#!/usr/local/bin/python2.6”试试.可能你的python2.6没有在$PATH里面,所以env不知道.1年前查看全部
- 24点纸牌游戏的开发 python
24点纸牌游戏的开发 python
24点纸牌游戏的开发
1)请你根据上述游戏规则构造一个玩24点游戏的算法,编程实现.要求如下:
输入:n1,n2,n3,n4
输出:若能得到运算结果为24,则输出一个对应的运算表达式.
如:输入:11,8,3,5
输出:(11-8)*(3+5)=24
提示:
算法的设计不唯一,穷举法是最为基本的解法,分治法则会获得比较高一些的效率,请你仔细思考,设计出算法实现该问题并画出算法的流程图.
2)请为你的24点纸牌游戏开发出一个界面
例如
提示:
2.软件主要完成的功能需要以下几个:
1)提供一个功能能进行随机发牌4张(用纸牌的形状或按钮的形状均可)
2)提供功能供用户输入关于这4张牌的表达式,并进行计算,判断结果的正确与否
3)能提供给用户正确答案
实验指导:
提示1:以下给出了穷举法解24点的代码框架,但很显然这种解法并不是最好的求解方法,你还可以设计其它的算法来解决该问题.
def cal(a,b,op):if op==0:return(a+b) if op==1:return(a-b) if op==2:return(a*b) if op==3:if(b==0.0):return(999.0) else:return(int(a/b)) def D24(v0,v1,v2,v3):op=['+','-','*','/'] v=[v0,v1,v2,v3] count=0 #四重循环开始穷举四个数字的位置:=24 种 #三重循环开始穷举三个运算符:4X4X4=64 种 #未用循环,直接穷举三个运算符的优先级:-1=5种- t1=t2=t3=0 #第1种情况 ((a.b).c).d 开始计算:t1=cal(v[i1],v[i2],f1) t2=cal(t1,v[i3],f2) t3=cal(t2,v[i4],f3) if t3==24:print(v[i1],op[f1],v[i2],op[f2],v[i3],op[f3],v[i4]) count+=1 #第2种情况 (a.b).(c.d) 开始计算:#第3种情况 (a.(b.c)).d 开始计算:#第4种情况 a.((b.c).d ) 开始计算:#第5种情况 a.(b.(c.d)) 开始计算:#穷举结束:共 24*64*5=7680 种表达式 --------------------------- if (count==0):print("can not calculate 24.",v0,v1,v2,v3); else:print("has several ways to calculate",count) v0=int(input("Pls input the 1st number:"))v1=int(input("Pls input the 2nd number:"))v2=int(input("Pls input the 3rd number:"))v3=int(input("Pls input the 4th number:"))D24(v0,v1,v2,v3)
提示2:界面设计可参考GUI相关知识进行,用到的控件包括:Button,Entry,Label等.注意:内置函数eval( )可以完成把一个字符串作为参数并返回它用为一个Python表达式的结果,例如:
>>>eval("2+3*4-5")
输出结果为:
9
以上函数可能帮助到你获取用户在Entry中输入表达式的值
另外,随机数的生成请参考Python的random模块
大计基实验太无情了lin839201年前1 -
我的用户名有点长 共回答了27个问题
|采纳率88.9%很久之前自己写的了,用的就是高级一点的穷举,还挺快的.
附带一个gui
求给分啊
两个文件,cui负责算数gui是界面,亲测可运行的
")
Button(text = "计算", command = calculate).pack()
initvariable()
drawframe()1年前查看全部
- 一个python的作业 求解#color size flesh classbrown large hard safegr
一个python的作业 求解
#color size flesh class
brown large hard safe
green large hard safe
red large soft dangerous
green large soft safe
red small hard safe
red small hard safe
brown small hard safe
green small soft dangerous
green small hard dangerous
red large hard safe
brown large soft safe
green small soft dangerous
red small soft safe
red large hard dangerous
red small hard safe
green small hard dangerous
file的txt文件是这样的(animals.txt)
这是完整的问题:
Q Download the dataset animals.txt, which contains features of animals. The features : color,size,flesh and class are separated by spaces. Write a Python program that asks the user for the names of the input file (in this case animals.txt) and the output file (any name). The program reads in the lines of the input file, ignores comment lines (lines starting with #) and blank lines and computes and prints the answers to the following questions:
Total number of animals?
Total number of dangerous animals?
Number of large animals that are safe?
Number of animals that are brown and dangerous?
Number of safe animals with red color or hard flesh?
要求的display格式要是
Total animals =
Dangerous =
Brown and dangerous =
Large and safe =
Safe with red color or hard flesh =
storm82811年前1 -
yss28 共回答了21个问题
|采纳率90.5%ifile=raw_input('input:')
ofile=raw_input('output:')
tmp=[]
with open(ifile,'r') as f0:
for i in f0:
if i!='' and i[0]!='#':
tmp.append(i.split())
with open(ofile,'w') as f1:
f1.writelines(['Total animals = %d'%len(tmp),
'Dangerous = %d'%len(filter(lambda x:x[3]=='dangerous',tmp)),
'Brown and dangerous = %d'%len(filter(lambda x:x[3]=='dangerous' and x[0]=='brown',tmp)),
'Large and safe = %d'%len(filter(lambda x:x[1]=='large' and x[3]=='safe',tmp)),
'Safe with red color or hard flesh = %d'%len(filter(lambda x:x[0]=='red' or x[2]=='hard' and x[3]=='safe',tmp))])1年前查看全部
- python问题:用二分法求根(递归)
python问题:用二分法求根(递归)
def root(x,p):
low = 0
hgh = x
m = (low + high)/2
if abs(m**2 - x) >> def f(m,x,low,high):
if abs(m**2 - x) x:
high = m
m = (low + high)/2
else:
low = m, m = (low + high)/2
return f(m,x,low,high)
>>> root(2.0,0.01)
Traceback (most recent call last):
File "", line 1, in
root(2.0,0.01)
File "", line 4, in root
m = (low + high)/2
NameError: global name 'high' is not defined,哪错了,谢谢
def f(m,x,low,high,p):
if abs(m**2 - x) x:
high = m
m = (low + high)/2
else:
low = m, m = (low + high)/2
return f(m,x,low,high,p)
>>> def root(x,p):
low = 0.0
high = x
m = (low + high)/2
if abs(m**2 - x) >> root(2.0,0.01)
Traceback (most recent call last):
File "", line 1, in
root(2.0,0.01)
File "", line 7, in root
else: return f(m,x,low,high,p)
File "", line 8, in f
low = m, m = (low + high)/2
TypeError: 'float' object is not iterable李维斯gg1年前1 -
1314520888 共回答了14个问题
|采纳率85.7%拼写错误:
hgh = x
改成high = x1年前查看全部
- python两列同维度向量x,y,怎么求y对x的积分?
熟习的陌生人1年前1
-
xiaomei_s 共回答了29个问题
|采纳率96.6%题主是用的什么库?python里本身没有“向量”的数据结构,只有List.1年前查看全部
- python怎样把两个dictionary中的value相乘并相加?
python怎样把两个dictionary中的value相乘并相加?
如题,要把所有的价格和数量相乘再相加得到总价,然后再放到total中,最后面for那一段不太会写,(如果有错还望指出,
prices = {
"banana" :4,
"apple" :2,
"orange" :1.5,
"pear" :3,
}
stock = {
"banana" :6,
"apple" :0,
"orange" :32,
"pear" :15,
}
for key in prices:
print key
print "price:%s" % prices[key]
print "stock:%s" % stock[key]
total=0
for value in prices:看不下去了91年前1 -
我跑我跑-扑通 共回答了19个问题
|采纳率89.5%total = sum([prices[fruit] * stock[fruit] for fruit in prices]) 是这样吗1年前查看全部
- PYTHON:关于 dictionary
PYTHON:关于 dictionary
>>> d={'1':'','2':'','4':'','5':''}
>>> d.keys()
['1','2','5','4']
有办法让他按顺序出来么?
比如让他变成['1','2','4','5']白色芦苇1年前1 -
q1797 共回答了15个问题
|采纳率93.3%x = d.keys()
x.sort()
x1年前查看全部
- python中,关于list和string的说法,错误的是
python中,关于list和string的说法,错误的是
Alist可以存放任意类型
Blist是一个有序集合,没有固定大小
C用于统计string中字符串长度的函数是string。len()
Dstring具有不可变性,其创建后值不能改变
ykplmm1年前1 -
Egirl888 共回答了17个问题
|采纳率94.1%选 B。 list可以存放任意类型,但不是有序的,否则也不会有sort方法了。len实际上通过__len__来实现的,对string 和list都支持。string、list都可变,python不可变的是tuple1年前查看全部
- 用python将“apple苹果橘子orange”,英文和汉字区分开来输出
行者呵呵1年前1
-
艾蔻eko 共回答了18个问题
|采纳率88.9%# -*- coding:utf-8 -*-
import string
mystring = 'apple苹果橘子orange'
english = []
chinese = []
for i in mystring.decode('utf-8'):
if i in string.ascii_letters:
english.append(i)
else:
chinese.append(i)
print 'English:'+''.join(english)
print 'Chinese:'+''.join(chinese)1年前查看全部
- 如何 用 matplotlib 绘制 PYTHON 随机数 求 圆周率 函数图.Y 轴 为 π值 X 轴 为 投石次数
vnymiko1年前0
-
共回答了个问题
|采纳率
- 用python做一个判断多个数字是否为偶数或奇数的程序
用python做一个判断多个数字是否为偶数或奇数的程序
用python做一个判断4个数字是否为偶数或奇数的程序,并且在最后说出1.奇数的数目比偶数多 2.偶数比奇数多 3.奇数和偶数一样多理想变梦想1年前1 -
镜子999 共回答了21个问题
|采纳率95.2%datas = [1,2,3,4]
s = d = 0
for i in datas:
if i%2 == 0:
d+=1
else:
s+=1
if s > d:
print '奇数多'
elif s < d:
print '偶数多'
else:
print '一样多'1年前查看全部
- python:如何将一个list的第2,5,6,7,8项同时删去?
python:如何将一个list的第2,5,6,7,8项同时删去?
现在一个list叫p,p=[2,5,6,7,8],如果我写成
for i in p:
del mylist[i]
就会out of range.紫魔天无痕1年前1 -
hanerwache 共回答了19个问题
|采纳率89.5%p.sort(reverse=True)
for i in p:
del mylist[i]
这样是删掉index是2,5,6,7,8的,如果你要第2,5,6,7,8项的话,应该是del mylist[i-1]1年前查看全部
- 在Python中,我有一个字典,想在字典中删除停用词表中的单词,程序应该怎么编.
在Python中,我有一个字典,想在字典中删除停用词表中的单词,程序应该怎么编.
dict={'nations':1,'city':1,'red':1,'negros':2,'so':4,'end':2,
'citizens':1,'remind':1,'american':4,'mountain':4,'shadow':1,'force':2,
'score':1,'militancy':1,'business':1,'selfhood':1,'all':7,'slaves':2,
'inextricably':1,'spot':1,'architects':1,'walk':2,'would':2,'rise':3,
'and':39,'men':6,'believe':2,'come':10,'police':2,'heightening':1,'york':2,
'if':3,'steam':1,'molehill':1,'hands':2,'suffering':2,'basic':1,'quest':1,
'interposition':1,'vaults':1,'devotees':1,'oasis':1,'concerned':1}
英语停用词表中的词有的在字典中没有.单调日子1年前1 -
dyingman_liu 共回答了19个问题
|采纳率78.9%en_dict = {}
stop_en_dict = {}
for key in stop_en_dict.keys():
if key in en_dict:
del en_dict[key]
print en_dict1年前查看全部
- 新手python问题Write a function called digit_sumthat takes a posi
新手python问题
Write a function called digit_sumthat takes a positive integer n as input and returns the sum of all that number's digits.
For example:digit_sum(1234)should return 10 which is 1 + 2 + 3 + 4.
(Assume that the number you are given will always be positive.)
这个要怎么写啊,新手不会做了,来求教.czyjs1年前1 -
ziyuanlianyi 共回答了15个问题
|采纳率86.7%不知道你给的数据是10进还是16进的,两个都写一下好了def digit_sum_16( number ):
con = 0
while number:
con += number 0xF
number >>= 4
return con
def digit_sum_10( number ):
con = 0
while number:
con += number % 10
number /= 10
return con1年前查看全部
- Python 3 中 int代表什么 有一道题不太明白
Python 3 中 int代表什么 有一道题不太明白
这道题:
What will be printed when the following Python3 program runs?
a = "5“
b = a
c = b * 4
print(c)
c = int (c)
print ( c * 2)
答案是
5555
11110
什么原理~~~
c不应该是5 * 4 = 20吗?
kazaf0711年前1 -
棉棉pig 共回答了20个问题
|采纳率95%a = "5“ ''给a赋值,字符5
b = a ''给b赋值,b值等于a值,即字符5
c = b * 4 ’‘b*4指四个b值相加,因为是字符所以结果是5555,其结果为字符串
print(c) ’‘输出c
c = int (c) ’‘赋值c为整形,即5千5百5十5
print ( c * 2) ’‘c*2即指数值c乘以2,即5555x2的值111101年前查看全部
- PYTHON:dictionary按原来顺序输出key
PYTHON:dictionary按原来顺序输出key
怎么解决
>>> d={'sam':'','beta':'','ccc':'','abc':''}
>>> d.keys()
['beta','abc','ccc','sam']
我让他的key是
['sam','beta','ccc','abc']lvtudiandiandidi1年前1 -
nmzs1988 共回答了19个问题
|采纳率68.4%dict是一种散列表结构,就是说数据输入后按特征已经被散列了,有自己的顺序.本身不记录原输入顺序.
如果一定需要输入顺序,建议
方案1,不使用dict,使用元组的列表,比如[('sam',''),('beta',''),('ccc',''),('abc','')]
这种结构是记录输入顺序的、有序的,也能方便地转换成dict.
方案2,另用一列表记录下输入时的顺序,比如['sam','beta','ccc','abc']1年前查看全部
大家在问
- 1(2012•高淳县二模)先化简,再求值:1−a−ba÷a2−b2a2+2ab+b2,其中a=2,b=4.
- 2What's your idea about pollutions的同义句 what do you ____ _____
- 3长时间的站着可以说是什么成语
- 4一、下列说法:1.三角形的高、中线、角平分线都是线段;2.三角形的三条中线都在三角形内部.3.三角形的高有两条在三角形的
- 5下面有三个成语填空,请回答:()()炮(),()相()(),()将()()以上三个成语怎么填?
- 6小明和小红同时从A地出发,小明向西行15米,小红向东行9米,然后两人以相同的速度相向而行,当他们相遇时,摘A点的哪个方向
- 7下列各点中,在第一象限内的点是( )
- 8一个小孩推一辆车,车没动.那么摩擦力和推力二力平衡我能理解,但是推力是可以变化的,我觉得推力在一定范围内车都不会动,那么
- 9成语对对子(紧急!)成语对对子:(注意对仗要工整,意思要相对)粗茶淡饭( ) 流芳百世( )井然有序( ) 指鹿为马(
- 10求:谢绝邀请信,具体内容如下你被邀请去参加一个宴会,但是你要工作,写一封谢绝信,字数要求120字以上!
- 11walk _____the road
- 12Translation:When one loves one's art,no service seems too ha
- 13请依照表中的示例完成下表: 物理现象 能量转化 示例 电饭锅煮饭 电能转化为内能 1 ______ ______ 2 _
- 14父亲的爱的格言有哪些这是一道开放性的语文题 但是我在书上没有查到
- 15收集一些知名的有哲理的古诗文自认为好的就OK……