统计量和随机变量是同一概念么?
 llmanbuzhe2022-10-04 11:39:541条回答
llmanbuzhe2022-10-04 11:39:541条回答
已提交,审核后显示!提交回复
共1条回复
 张儆心 共回答了23个问题
张儆心 共回答了23个问题 |采纳率91.3%- no
- 1年前
相关推荐
- (2007•湖州)要比较两位同学在五次数学测验中谁的成绩比较稳定,应选用的统计量是( )
(2007•湖州)要比较两位同学在五次数学测验中谁的成绩比较稳定,应选用的统计量是( )
A.平均数
B.中位数
C.众数
D.方差紫露精灵1年前1 -
bule_xu 共回答了26个问题
|采纳率96.2%解题思路:根据方差的意义:体现数据的稳定性,集中程度,波动性大小;方差越小,数据越稳定.要比较两位同学在五次数学测验中谁的成绩比较稳定,应选用的统计量是方差.由于方差反映数据的波动情况,应知道数据的方差.
故选D.点评:
本题考点: 统计量的选择.
考点点评: 此题主要考查统计的有关知识,主要包括平均数、中位数、众数、方差的意义.反映数据集中程度的统计量有平均数、中位数、众数方差等,各有局限性,因此要对统计量进行合理的选择和恰当的运用.1年前查看全部
- (2010•静安区二模)下列统计量中,表示一组数据波动情况的量是( )
(2010•静安区二模)下列统计量中,表示一组数据波动情况的量是( )
A.平均数
B.中位数
C.众数
D.标准差BooOoOooM1年前1 -
漫画小生 共回答了19个问题
|采纳率89.5%解题思路:根据方差和标准差的意义:体现数据的稳定性,集中程度;方差越小,数据越稳定.由于方差和标准差反映数据的波动情况.
故选D.点评:
本题考点: 统计量的选择.
考点点评: 此题主要考查统计的有关知识,主要包括平均数、中位数、众数、方差的意义.反映数据集中程度的统计量有平均数、中位数、众数、方差等,各有局限性,因此要对统计量进行合理的选择和恰当的运用.1年前查看全部
- 统计学 spss 中 相关系数的检验 t检验统计量的p值是指图中的显著性(双侧)吗?
统计学 spss 中 相关系数的检验 t检验统计量的p值是指图中的显著性(双侧)吗?
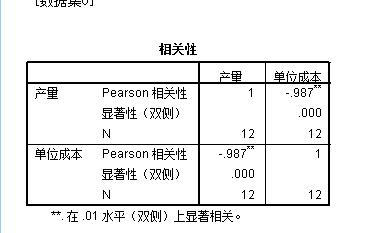
假如(α=0.05)的话,那么我们得知0.05>P=0 是不是就可以拒绝原假设(H:相关系数=0)石山方弘1年前1 -
timyen 共回答了21个问题
|采纳率95.2%你学统计学的 不是有条件吗?应该是这样的 可以拒绝原假设1年前查看全部
- 在独立性检验中,统计量x2有两个临界值:3.841和6.635;当x2>3.841时,有95%的把握说明两个事件有关,当
在独立性检验中,统计量x2有两个临界值:3.841和6.635;当x2>3.841时,有95%的把握说明两个事件有关,当x2>6.635时,有99%的把握说明两个事件相关,当x2≤3.841时,认为两个事件无关.在一项调查某种药是否对心脏病有治疗作用时,共调查了3000人,经计算的x2=4.56,根据这一数据分析,认为此药物与心脏病之间( )
A.有95%的把握认为两者相关
B.约有95%的心脏病患者使用药物有作用
C.有99%的把握认为两者相关
D.约有99%的心脏病患者使用药物有作用iguana5551年前1 -
ahnlwq 共回答了20个问题
|采纳率95%解题思路:由独立性检验直接可得.∵4.56>3.841,
且当x2>3.841时,有95%的把握说明两个事件有关,
故选A.点评:
本题考点: 独立性检验.
考点点评: 本题考查了独立性检验,属于基础题.1年前查看全部
- 用什么统计量表示上面两组数据的一般水平比较合适
用什么统计量表示上面两组数据的一般水平比较合适
2.六(1)班同学身高、体重情况如下表.
身高 1.40 1.43 1.46 1.49 1.52 1.55 1.58
人数 1 3 5 10 12 6 3
体重 30 33 36 39 42 45 48
人数 2 4 5 12 10 4 3我就想看贴1年前2 -
碧绿幽子 共回答了25个问题
|采纳率96%众数1年前查看全部
- ( )、( )、( )三种数都是统计量,这三种量都是反映数据集中程度的统计量.空怎么填?
nanazuidiao1年前1
-
皮皮鲁ZL 共回答了14个问题
|采纳率92.9%( 平均数)、(中位数 )、( 众数)三种数量都是统计量,这三种数量都是反映数据集中程度的统计量1年前查看全部
- 数学问题 急~ :判断下列三组数据是用平均数、中位数和众数三种统计量中哪种表示集中趋势最好?
数学问题 急~ :判断下列三组数据是用平均数、中位数和众数三种统计量中哪种表示集中趋势最好?
1、60 50 40 45 55 61 58 2、70 92 63 76 81 74 63 200 3、80 90 80 70 80 91 80 73 80 80 最好说下怎么做的 求高手速度解决
1、60 50 40 45 55 61 58
2、70 92 63 76 81 74 63 200
3、80 90 80 70 80 91 80 73 80 80改正归邪吧1年前1 -
大kk 共回答了25个问题
|采纳率88%第一组,数据都比较接近,可选用平均数,算出结果是:52.857
第二组,有一个200特别大,用中位数,先由小到大排列,63 63 70 74 76 81 92 200 ,中位数应该是75
第三组,数据相差不大,且80特别多,应选用众数,为801年前查看全部
- 我们进入中学以来,已经学习过不少有关数据的统计量,例如______等,它们分别从不同的侧面描述了一组数据的特征.
powerzjw1年前1
-
irismeme 共回答了20个问题
|采纳率85%解题思路:根据统计的知识,可得出所学的统计量共有6个.所学的统计量:平均数、众数、中位数、极差、方差、标准差共有6个.
故填平均数、众数、中位数、极差、方差、标准差.点评:
本题考点: 统计量的选择.
考点点评: 要熟练掌握所学的统计量的定义及其运用.1年前查看全部
- 怎样判别10%置信水平下的CUSUMSQ统计量的显著性?
gonghj1年前1
-
wangruobing 共回答了23个问题
|采纳率87%如果检验统计量的值位于10%水平下的置信带以外,就认为参数非平稳的1年前查看全部
- 概率论四题为何选c 其余分别是什么统计量
wucz1年前1
-
天地璎珞 共回答了23个问题
|采纳率69.6%因为 σ 是未知的,所以 (C) 那个式子算不出来.
其它几个是什么统计量不重要,它们至少都能算出来,可以叫统计量(不管有意义、还是没意义的统计量).
BTW:我不得不抱怨提问者一下.你知道为什么这么久没回答么?因为你在 (C) 选项上画了个对勾,正好挡住最重要的文字.我这个回答也是猜的,我看着像是 σ.1年前查看全部
- 当较大数和较小数相差太大时,用什么统计量表示这组数据的一般水平比较合适
tmq19861年前1
-
daijiale 共回答了19个问题
|采纳率89.5%用中位数比较合适.1年前查看全部
- 表示一组数据波动大小的统计量有?
表示一组数据波动大小的统计量有?
有3个alda05091年前2 -
hihiwindy 共回答了15个问题
|采纳率100%极差 方差 标准差
可能还有1年前查看全部
- 一些不会的统计学题目检验回归系数是否为零的统计量是( )A. F统计量 B. t统计量 C. 开方统计量 D. 方差统计
一些不会的统计学题目
检验回归系数是否为零的统计量是( )
A. F统计量
B. t统计量
C. 开方统计量
D. 方差统计量
设200件产品零件中有20个次品,现从中抽取20个,则正好抽到一个不合格品的概率是( )
A. 0.2572
B. 0.5254
C. 0.2702
D. 0.6538
累计增长量是( ).
A. 相应的各个逐期增长量之和
B. 报告期水平与前一期水平之差
C. 各期水平与最初水平之差
D. 报告期水平与最初水平之差加报告期水平与前一期水平之差
7、累计增长量是( ).
A. 相应的各个逐期增长量之和
B. 报告期水平与前一期水平之差
C. 各期水平与最初水平之差
D. 报告期水平与最初水平之差加报告期水平与前一期水平之差yjc7251年前2 -
jjswj2000 共回答了17个问题
|采纳率88.2%1.A
2.C
3.D
4.D
这些题挺难的!1年前查看全部
- 到目前为止我们已经认识的统计量有( )、( )、( ),它们各有特点在解决问题的过程中,需要根据问题解决的需要进行选择。
wyyhyz20071年前2
-
fangaa007008 共回答了9个问题
|采纳率11.1%统计图吧1年前查看全部
- 概率与数理统计中的统计量问题`~
hkkcjl1年前0
-
共回答了个问题
|采纳率
- 平均数、中位数和众数都是反映一组数据______的统计量.
mxh02161年前4
-
千百代 共回答了21个问题
|采纳率76.2%解题思路:(1)平均数:平均数的计算中要用到每一个数据,因而它反映的是一组数据的总体水平.
(2)中位数:中位数是一组数据的中间量,代表了中等水平.
(3)众数代表的是一组数据的多数水平,众数反映了一组数据的集中趋势,当众数出现的次数越多,它就越能代表这组数据的整体状况,并且它能比较直观地了解到一组数据的大致情况;由此可知:平均数、中位数和众数都是反映一组数据集中趋势的统计量.平均数、中位数和众数都是反映一组数据集中趋势的统计量.
故答案为:集中趋势.点评:
本题考点: 众数的意义及求解方法;平均数的含义及求平均数的方法;中位数的意义及求解方法.
考点点评: 本题考查了众数与中位数平均数在一组数据中的作用.它们都是反映一组数据集中趋势的统计量.1年前查看全部
- 2.已知模型的DW统计量为0.6时,普通最小二乘估计的一阶自相关系数为?
2.已知模型的DW统计量为0.6时,普通最小二乘估计的一阶自相关系数为?
为什么选(D)啊?看不懂
A.0.3 B.0.4 C.0.5 D.0.7JGAMGWG1年前1 -
维洛索 共回答了23个问题
|采纳率100%DW近似等于2(1-r^2)
所以2×(1-r^2)=0.6
r^2=0.7
估计你问的应该是这个把.1年前查看全部
- 什么是反映一组数据的离散程度的统计量,它的算术平方根称为
CMLX_20051年前1
-
topwan 共回答了12个问题
|采纳率91.7%标准差(Standard Deviation) ,也称均方差(mean square error),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用σ表示.标准差是方差的算术平方根.标准差能反映一个数据集的离散程度.平均数相同的,标准差未必相同.1年前查看全部
- 条形统计图通过______来看统计量的变化;折线统计图通过______来表示统计量变化的情况.
条形统计图通过______来看统计量的变化;折线统计图通过______来表示统计量变化的情况.
A.折线的长短 B.直条的粗细 C.直条的长度 D.折线的升降.ggdi1年前1 -
linsy1306 共回答了19个问题
|采纳率94.7%解题思路:条形统计图能很容易看出数量的多少;折线统计图不仅容易看出数量的多少,而且能反映数量的增减变化情况;扇形统计图能反映部分与整体的关系;由此根据情况选择即可.根据统计图的特点可知:条形统计图通过直条的长度来看统计量的变化;
折线统计图通过折线的升降来表示统计量变化的情况.
故选:C,D.点评:
本题考点: 统计图的特点.
考点点评: 此题应根据条形统计图、折线统计图、扇形统计图各自的特点进行解答.1年前查看全部
- 5统计量的选择与应用答案找不到
想不到ID1年前2
-
这个西瓜有点苦 共回答了24个问题
|采纳率95.8%方差 400 X拔=15X1.6+15X2+1.8X15分之15X3 =1.8KG (2):2000X1.8X7.5=27000元 给我1年前查看全部
- 抽样检验国家标准体系下质量统计量的意思是?
jc8881年前2
-
dsyelber 共回答了19个问题
|采纳率89.5%可以到文库搜索 :GB2828-2003抽样标准
抽样统计量我理解应该是样本数量,抽取的总数量.1年前查看全部
- 能够刻画一组数据离散程度的统计量是 [ ] A.平均数
能够刻画一组数据离散程度的统计量是 [ ]A.平均数
B.众数
C.中位数
D.方差jojowong1年前1 -
无事生菲 共回答了17个问题
|采纳率100%D1年前查看全部
- 下列统计量中,不能反映一名学生在第一学期的数学学习成绩稳定程度的是 [
下列统计量中,不能反映一名学生在第一学期的数学学习成绩稳定程度的是 [ ]A.中位数
B.方差
C.标准差
D.极差sunjian2581年前1 -
着惊讶 共回答了19个问题
|采纳率100%A1年前查看全部
- 下列统计量中哪个是简单线性回归方程统计检验的统计量( )
下列统计量中哪个是简单线性回归方程统计检验的统计量( )
A.uα 2
B.tα 2
C.Fα(r-1,n-r)
D.Fα(1,n-2)84116721年前0 -
共回答了个问题
|采纳率
- 非标准检验中秩和统计量如何理解呢'跪求解答
非标准检验中秩和统计量如何理解呢'跪求解答
那个非标准检验中的秩统计量定义如何理解啊'有个小例子:一组观测值x1=5,x2=3,x3=8,x4=6,x5=2,x6=4.由小到大排列'它的顺序统计量为x5=2,x2=3,x6=4,x1=5,x4=6,x3=8.秩统计量为:r1=4,r2=2,r3=6,r4=5,r5=1,r6=3'这个秩统计量是怎么得来的啊lxzzcyc1年前1 -
末日llF 共回答了24个问题
|采纳率83.3%你首先将数据排序,A: 2,3,4,5,6,8然后与原始数据的序列比较B: 5,3,8,6,2,4,可以看到,第一个B5,在A中的排序为第4,第二个B3在A中的排序为第2,第二个B8在A总的排序是6……这些在A中的排序就是B中各值的“秩”,用这些秩与1,2,3,4,5,6作比较,就可以得出一个检验的概率了.这就是对之和检验的一个简单解释.1年前查看全部
- 怎么证明样本方差是一致统计量?
长春小崽儿1年前2
-
1hjd 共回答了25个问题
|采纳率100%要证样本方差是总体方差的一致估计量,即要证样本方差Sn依概率收敛于总体方差
首先我们知道样本方差是总体方差的无偏估计量:ESn=σ^2
然后根据切比雪夫不等式,有P(|Sn-ESn|>=ε)=ε)趋向于0,对任意ε.将ESn=σ^2代入即得结论.1年前查看全部
- DW统计量的含义是关于计量经济学的
楸树1年前1
-
kjkfjkjgjb 共回答了19个问题
|采纳率94.7%用于杜宾沃森检验.是检验序列相关性问题的.先通过公式计算出DW值,再根据样本容量n和解释变量数目k查分布表,得到临界值dl和du,然后判断模型的自相关状态.01年前查看全部
- 测度数据分布形状的统计量有哪些
hahahaha3211年前1
-
coolhawks 共回答了18个问题
|采纳率100%偏态系数
峰态系数1年前查看全部
- 20、14、19、20、6、18、14、10、20、19这组数据,用哪个统计量表示比较合适?
20、14、19、20、6、18、14、10、20、19这组数据,用哪个统计量表示比较合适?
平均数 众数 中位数.
三选一.zhwei19841年前1 -
duanhailin 共回答了16个问题
|采纳率100%平均数好一些.1年前查看全部
- (2005•淮安)下列统计量中,能反映一个学生在7~9年级学段的学习成绩稳定程度的是( )
(2005•淮安)下列统计量中,能反映一个学生在7~9年级学段的学习成绩稳定程度的是( )
A.平均数
B.中位数
C.方差
D.众数程晟1年前1 -
igrowheart 共回答了17个问题
|采纳率82.4%解题思路:方差反映数据的稳定性,集中程度,波动性;方差越小,数据越稳定,波动性越小.由此可判断能反映一个学生在7~9年级学段的学习成绩稳定程度的量.由于方差反映数据的波动大小,则能反映学生的成绩稳定程度的是方差.
故选C.点评:
本题考点: 统计量的选择;方差.
考点点评: 此题主要考查统计的有关知识,主要包括平均数、中位数、众数、方差的意义.反映数据集中程度的统计量有平均数、中位数、众数方差等,各有局限性,因此要对统计量进行合理的选择和恰当的运用.1年前查看全部
- 在独立性检验中,统计量 有两个临界值:3.841和6.635;当 >3.841时,有95%的把握说明两个事件有关,当 >
在独立性检验中,统计量
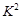 有两个临界值:3.841和6.635;当 >3.841时,有95%的把握说明两个事件有关,当 >6.635时,有99%的把握说明两个事件有关,当
有两个临界值:3.841和6.635;当 >3.841时,有95%的把握说明两个事件有关,当 >6.635时,有99%的把握说明两个事件有关,当 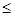 3.841时,认为两个事件无关.在一项打鼾与患心脏病的调查中,共调查了2000人,经计算的 ="20." 87,根据这一数据分析,认为打鼾与患心脏病之间
3.841时,认为两个事件无关.在一项打鼾与患心脏病的调查中,共调查了2000人,经计算的 ="20." 87,根据这一数据分析,认为打鼾与患心脏病之间 A.有95%的把握认为两者有关 B.约有95%的打鼾者患心脏病 C.有99%的把握认为两者有关 D.约有99%的打鼾者患心脏病 comoneon1年前1 -
luktiy 共回答了18个问题
|采纳率94.4%解题思路:∵ 计算Χ2=20.87. 有20.87>6.635 ,∵ 当Χ2>6.635 时,有99% 的把握说明两个事件有关,故选C.C
1年前查看全部
- 统计量 方差S 的问题 :S 为什么会等于 后面那个式子啊 ? 过程求解 有追加分!
统计量 方差S 的问题 :S 为什么会等于 后面那个式子啊 ? 过程求解 有追加分!
感觉 不相等啊 但是 乐励华 江西高校出版社 第四版 概率论与数理统计 165页 有个这样的等式 也没解释的.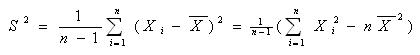 呆挂之王1年前1
呆挂之王1年前1 -
srq726 共回答了17个问题
|采纳率88.2%sum(Xi-X拔)^2=sum(Xi^2-2XiX拔+X拔^2)=sumXi^2-2*X拔*sumXi+n*X拔^2
其中sumXi=n*X拔
所以sumXi^2-2*X拔*sumXi+n*X拔^2=sumXi^2-2n*X拔^2+n*X拔^2=sumXi^2-n*X拔^2
就是这样!希望您能明白1年前查看全部
- 概率密度题1.N(u,o2),u,o2未知,(X1,X2)为e的样本,则可以成为统计量的是( ) A) X1+u B)
概率密度题
1.N(u,o2),u,o2未知,(X1,X2)为e的样本,则可以成为统计量的是( )
A) X1+u
B) X1+O2
C) uX1
D) 2X1X2
判断题:
2.已知随机变量e服从于[1,4]的均匀分布,则X2+eX+1=0有实根的概率为2/3.
3.设e~u(0,6),n=1,e4 ,则n的数学期望Dn=1
4.随机变量e的概率密度为Q(X)=re^-rx x>0
=0 其他 ,
其中r>0是未知常数,(X1,X2,...,Xn)是e的样本,则r的极大似然估计量为1/-x(-在x上面) ( )b8310041年前1 -
v端坐霜天v 共回答了28个问题
|采纳率89.3%1.N(u,o2),u,o2未知,(X1,X2)为e的样本,则可以成为统计量的是 D) 2X1X2
A) X1+u
B) X1+O2
C) uX1
D) 2X1X2
判断题:
2.已知随机变量e服从于[1,4]的均匀分布,则X2+eX+1=0有实根的概率为2/3.对
3.设e~u(0,6),n=1,e4 ,则n的数学期望Dn=1 没看明白
4.随机变量e的概率密度为Q(X)=re^-rx x>0
=0 其他 ,
其中r>0是未知常数,(X1,X2,...,Xn)是e的样本,则r的极大似然估计量为1/-x(-在x上面) (对 )1年前查看全部
- ______都是衡量一个样本一组数据波动大小的统计量.
8yyyy81年前1
-
怀鱼 共回答了18个问题
|采纳率88.9%极差、方差和标准差都是衡量一个样本一组数据波动大小的统计量.
故填:极差、方差、标准差.1年前查看全部
- 参数与统计量的联系与区别是什么
真水无香之上1年前1
-
sdlksj 共回答了30个问题
|采纳率90%平均数、众数、中位数这三个统计量的各自特点是:
平均数的大小与一组数据里的每个数据均有关系,其中任何数据的变动都会相应引起平均数的变动;众数则着眼于对各数据出现的次数的考察,其大小只与这组数据中的部分数据有关,当一组数据中有不少数据多次重复出现时,其众数往往是我们关心的一种统计量;中位数则仅与数据排列位置有关,当一组数据从小到大排列后,最中间的数据为中位数(偶数个数据的最中间两个的平均数).因此某些数据的变动对它的中位数影响不大.
在同一组数据中,众数、中位数和平均数也各有其特性:
(1)中位数与平均数是唯一存在的,而众数是不唯一的;
(2)众数、中位数和平均数在一般情况下是各不相等,但在特殊情况下也可能相等.
具体来说,平均数、众数和中位数都是描述一组数据的集中趋势的特征数,但描述的角度和适用范围有所不同.平均数的大小与一组数据里的每个数据均有关系,其中任何数据的变动都会引起平均数的相应变动;众数着眼于对各数据出现的频数的考察,其大小只与这组数据中的部分数据有关;中位数则仅与数据的排列位置有关,某些数据的变动对中位数没有影响,当一组数据中的个别数据变动较大时,可用它来描述其集中趋势.
一般来说,平均数、中位数和钟书都是一组数据的代表,分别代表这组数据的“一般水平”、“中等水平”和“多数水平”.平均数涉及所有的数据,中位数和众数只涉及部分数据.它们互相之间可以相等也可以不相等,没有固定的大小关系.
其实,它们三者有关联也有区别.在一组数据中出现次数最多的数就是这组数据众数,众数和平均数一样,也是描述一组数据集中趋势的统计量,但它和平均数有以下两点不同:一是平均数只是一个“虚拟”的数,即一组数据的和除以该组数据的个数所得的商,而众数不是“虚拟”的数,是一组数据中出现次数最多的那个数据,是这组数据中真实存在的一个数据;二是平均数的大小与一组数据里的每个数据都有关系,任何一个数据的变动都会引起平均数大小的改变,而众数则仅与一组数据的出现的次数有关,某些数据的变动对众数没有影响,所以在一组数据中,如果个别数据变动较大,但某个数据出现的次数最多,此时用该数据(即众数)表示这组数据的“集中趋势”比较合适.
中位数和平均数一样,也是反映一组数据集中趋势的一个统计量.平均数主要反映一组数据的一般水平,中位数则更好地反映了一组数据的中等水平.它和平均数有以下不同:一是平均数只是一个“虚拟”的数,而中位数并不完全是“虚拟”数,当一组数据有奇数个时,它就是该组数据顺序排列后中间的那个数据,是这组数据中真实存在的一个数据;二是平均数的大小与一组数据里的每个数据都有关系,任何一个数据的变动都会引起平均数大小的改变,而中位数则仅与一组数据的排列位置有关,某些数据的变动对中位数没有影响,所以当一组数据的个别数据偏大或偏小时,用中位数来描述该组数据的集中趋势就比较合适.1年前查看全部
- 表示样本精密度的统计量有哪些
zhoubinjady1年前1
-
刘老虎 共回答了16个问题
|采纳率87.5%1
第
二
章
误
差
和
分
析
数
据
处
理
思
考
题
和
习
题
1
.
指
出
下
列
各
种
误
差
是
系
统
误
差
还
是
偶
然
误
差
?
如
果
是
系
统
误
差
,请
区
别
方
法
误
差
、仪
器
和
试
剂
误
差
或
操
作
误
差
,并
给
出
它
们
的
减
免
办
法
.
(1
)
砝
码
受
腐
蚀
;
(2
)
天
平
的
两
臂
不
等
长
;
(3
)
容
量
瓶
与
移
液
管
未
经
校
准
;
(4
)
在
重
量
分
析
中
,
试
样
的
非
被
测
组
分
被
共
沉
淀
;
(5
)
试
剂
含
被
测
组
分
;
(6
)
试
样
在
称
量
过
程
中
吸
湿
;
(7
)
化
学
计
量
点
不
在
指
示
剂
的
变
色
范
围
内
;
(8
)
读
取
滴
定
管
读
数
时
,
最
后
一
位
数
字
估
计
不
准
;
(9
)
在
分
光
光
度
法
测
定
中
,
波
长
指
示
器
所
示
波
长
与
实
际
波
长
不
符
.
2
.
表
示
样
本
精
密
度
的
统
计
量
有
哪
些
?
与
平
均
偏
差
相
比
,
标
准
偏
差
能
更
好
地
表
示
一
组
数
据
的
离
散
程
度
,
为
什
么
?
3
.
说
明
误
差
与
偏
差
、
准
确
度
与
精
密
度
的
区
别
和
联
系
.
4
.
什
么
叫
误
差
传
递
?
为
什
么
在
测
量
过
程
中
要
尽
量
避
免
大
误
差
环
节
?
5
.
何
谓
t
分
布
?
它
与
正
态
分
布
有
何
关
系
?
6
.
在
进
行
有
限
量
实
验
数
据
的
统
计
检
验
时
,
如
何
正
确
选
择
置
信
水
平
?
7
.
为
什
么
统
计
检
验
的
正
确
顺
序
是
:
先
进
行
可
疑
数
据
的
取
舍
,
再
进
行
F
检
验
,
在
F
检
验
通
过
后
,
才
能
进
行
t
检
验
?
8
.
说
明
双
侧
检
验
与
单
侧
检
验
的
区
别
,
什
么
情
况
用
前
者
或
后
者
?
9
.
何
谓
线
性
回
归
?
相
关
系
数
的
意
义
是
什
么
?
10
.
进
行
下
述
运
算
,
并
给
出
适
当
位
数
的
有
效
数
字
.
(1
)
4
10
16
.
6
14
.
15
10
.
4
52
.
2
(2
)
0001120
.
0
10
.
5
14
.
21
01
.
3
(3
)
002034
.
0
512
.
2
10
03
.
4
0
.
51
4
(4
)
050
.
1
10
12
.
2
1
.
8
0324
.
0
2
(5
)
5462
.
3
10
50
.
7
8940
.
1
42
.
5
51
.
2
2856
.
2
3
(6
)
p
H
=
2.1
0
,
求
[H
+
]
=
?
(
2.
54
×
1
0
3
;
2.9
8
×
1
0
6
;
4.
02
;
5
3.
0
;
3.
14
4
;
7.
9
×
1
0
3
mo
l/L
)
2
11
.
两
人
测
定
同
一
标
准
试
样
,
各
得
一
组
数
据
的
偏
差
如
下
:
(1)0.3
-
0.
2
-
0.
4
0.
2
0.
1
0.
4
0.
0
-
0.
3
0.
2
-
0.
3
(2)0.1
0.
1
-
0.
6
0.
2
-
0.
1
-
0.
2
0.
5
-
0.
2
0.
3
0.
1
①
求
两
组
数
据
的
平
均
偏
差
和
标
准
偏
差
;
②
为
什
么
两
组
数
据
计
算
出
的
平
均
偏
差
相
等
,
而
标
准
偏
差
不
等
?
③
哪
组
数
据
的
精
密
度
高
?
(
①
1
d
=
0.2
4
,
2
d
=
0.
2
4
,
S
l
=
0.
2
8
,
S
2
=
0.3
1
.
②
因
为
标
准
偏
差
能
突
出
大
偏
差
.
③
第
一
组
数
据
的
精
密
度
高
)
12
.一
位
气
相
色
谱
工
作
新
手
,要
确
定
自
己
注
射
样
品
的
精
密
度
.同
一
样
品
注
射
了
1
0
次
,
每
次
0.5
µ
1
,
量
得
色
谱
峰
高
分
别
为
:
1
4
2.1
、
1
47.
0
、
14
6.
2
、
14
5.2
、
1
43.8
、
1
46.2
、
1
47.
3
、
1
5
0.
3
、
14
5.
9
及
1
5
1.
8
mm
.
求
标
准
偏
差
与
相
对
标
准
偏
差
,并
作
出
结
论(
有
经
验
的
色
谱
工
作
者
,很
容
易
达
到
RS
D
≤
1
%
)
.
(
S
=
2.8
mm
,
RS
D
=
1.
9
%
)
13
.
测
定
碳
的
相
对
原
子
质
量
所
得
数
据
:
1
2.0
08
0
、
1
2.
00
9
5
、
12.
00
99
、
12.0
1
01
、
12.0
1
02
、
12.0
1
06
、
12.0
111
、
1
2.0
113
、
12.
0
11
8
及
1
2.
01
2
0
.
求
算
:
①
平
均
值
;
②
标
准
偏
差
;
③
平
均
值
的
标
准
偏
差
;
④
平
均
值
在
99
%
置
信
水
平
的
置
信
限
.
(
①
1
2.
01
0
4
;
②
0.
00
1
2
;
③
0.
00
03
8
;
④
±
0.
00
1
2
)
14
.
用
重
量
法
测
定
试
样
中
F
e
含
量
时
,
六
次
测
定
结
果
的
平
均
值
为
46.2
0
%
;
用
滴
定
分
析
法
四
次
测
定
结
果
的
平
均
值
为
4
6.
02
%
;
两
者
的
标
准
偏
差
都
是
0.
08
%
.
这
两
种
方
法
所
得
的
结
果
是
否
存
在
显
著
性
差
别
?
(
是
,
t
=
3.
5
)
15
.在
用
氯
丁
二
烯
氯
化
生
产
二
氯
丁
二
烯
时
,产
品
中
总
有
少
量
的
三
氯
丁
二
烯
杂
质
存
在
.分
析
表
明
,
杂
质
的
平
均
含
量
为
1.6
0
%
.改
变
反
应
条
件
进
行
试
生
产
,每
5
小
时
取
样
一
次
,共
取
六
次
,测
定
杂
质
含
量
分
别
为
:
1.
46
%
、
1.
6
2
%
、
1.3
7
%
、
1.7
1
%
、
1.5
2
%
及
1.
40
%
.
问
改
变
反
应
条
件
后
,
产
品
中
杂
质
含
量
与
改
变
前
相
比
,
有
明
显
差
别
吗
(
α
=
0.
0
5
时
)
?
(
无
,
t
=
1.
6
)
16
.
用
化
学
法
与
高
效
液
相
色
谱
法
(
HP
LC
)
测
定
同
一
复
方
乙
酰
水
杨
酸
(
AP
C
)
片
剂
中
乙
酰
水
杨
酸
的
含
量
,
测
得
的
标
示
量
含
量
如
下
:
HP
LC
(
3
次
进
样
的
均
值
)
:
9
7.
2
%
、
9
8.
1
%
、
9
9.
9
%
、
9
9.3
%
、
97.2
%
及
9
8.
1
%
;
3
化
学
法
:
9
7.
8
%
、
97.7
%
、
9
8.
1
%
、
9
6.7
%
及
97.3
%
.
问
:
①
两
种
方
法
分
析
结
果
的
精
密
度
与
平
均
值
是
否
存
在
显
著
性
差
别
?
②
在
该
项
分
析
中
HP
LC
法
可
否
替
代
化
学
法
?
(
①
F
=
4.
15
,
t
=
1.
6
,皆
小
于
α
=
0.
05
时
的
临
界
值
,说
明
两
种
方
法
的
精
密
度
与
平
均
值
均
不
存
在
显
著
性
差
别
;②
HP
LC
法
可
以
替
代
化
学
法
.
)
17
.用
HP
LC
分
析
某
复
方
制
剂
中
氯
原
酸
的
含
量
,共
测
定
6
次
,其
平
均
值
x
=
2.
74
%
,
S
x
=
0.
5
6%
.试
求
置
信
水
平
分
别
为
9
5
%
和
9
9
%
时
平
均
值
的
置
信
区
间
.
(
P
=
9
5
%
:
2.
74
±
0.
59
;
P
=
99
%
:
2.7
4
±
0.9
0
)
18
.
用
巯
基
乙
酸
法
进
行
亚
铁
离
子
的
分
光
光
度
法
测
定
.
在
波
长
60
5
nm
测
定
试
样
溶
液
的
吸
光
度
(
A
)
,
所
得
数
据
如
下
:
x
(
µ
g F
e/10
0
m1
)
:
0
10
2
0
30
4
0
5
0
y
(
A
=
lg
I
0
/
I
)
:
0.
00
9
0.
03
5
0.
0
61
0.0
83
0.
10
9
0.
1
33
试
求
:
①
吸
光
度
-
浓
度
(
A
-C
)
的
回
归
方
程
式
;
②
相
关
系
数
;
③
A
=
0.
05
0
时
,
试
样
溶
液
中
亚
铁
离
子
的
浓
度
.
(
①
y
=
0.
0
10
+
0.0
02
4
7
C
;②
r
=
0.9
99
7
;③
16.2
µ
g/1
0
0
m1
)1年前查看全部
- 怎么理解统计量T=T(x1,x2,.xn)中不含有任何未知参数,则称T为统计量.
wudijojo1年前2
-
花露水mm 共回答了20个问题
|采纳率100%如正态分布N(μ,σ²),其中μ已知而σ未知
则 x1+x2 是统计量 x1+x2-2μ 是统计量,这两者均不含未知参数
但 (x1+x2)/σ 就不是统计量,它含未知参数σ.1年前查看全部
- 下列说法中正确的有______①刻画一组数据集中趋势的统计量有极差、方差、标准差等;刻画一组数据离散程度统计量有平均数、
下列说法中正确的有______
①刻画一组数据集中趋势的统计量有极差、方差、标准差等;刻画一组数据离散程度统计量有平均数、中位数、众数等.
②抛掷两枚硬币,出现“两枚都是正面朝上”、“两枚都是反面朝上”、“恰好一枚硬币正面朝上”的概率一样大.
③有10个阄,其中一个代表奖品,10个人按顺序依次抓阄来决定奖品的归属,则摸奖的顺序对中奖率没有影响.
④向一个圆面内随机地投一个点,如果该点落在圆内任意一点都是等可能的,则该随机试验的数学模型是几何概型.第二只想飞的乌龟1年前1 -
红色镁光 共回答了14个问题
|采纳率92.9%①刻画一组数据集中趋势的统计量有平均数、中位数、众数等;刻画一组数据离散程度统计量有极差、方差、标准差等,故①不正确;
②抛掷两枚硬币,出现“两枚都是正面朝上”、“两枚都是反面朝上”的概率分别为
1
4 ,“恰好一枚硬币正面朝上”的概率
1
2 ,故②不正确;
③抽签有先后,摸奖的顺序对中奖率没有影响,故③正确;
④由于基本事件的无限性,且该点落在圆内任意一点都是等可能的,则该随机试验的数学模型是几何概型,故④正确
故答案为:③④1年前查看全部
- 关于“统计量”“抽样分布”和“X2分布、t分布、F分布”的关系~
关于“统计量”“抽样分布”和“X2分布、t分布、F分布”的关系~
我知道统计量是样本的函数,是对原始数据的整理.
抽样分布是统计量的概率分布.
课本上说卡方分布、t分布和F分布是在正态总体条件下求出的精确的抽样分布,可是我就是不理解,他们三个到底是哪个统计量的概率分布?还是有某个统计量被镶入到了这三个分布中?
为什么要构建三个这种形式的抽样分布?
他们分别所具有的直观意义是什么?彬彬的故事1年前2 -
yaofafeng 共回答了19个问题
|采纳率100%以X^2分布为例子吧
x1,x2..xn都遵守N(0,1)的正态分布,则
x1^2+x2^2+...遵守X^2(n)分布
相当于形成了一个新统计量Y=x1^2+x2^2+...
是新的统计量!
而t分布,F分布也都是新统计量的分布
只不过他们都是正态总体中的抽样x1,x2,x3...组成的函数
就好象你知道x,y独立,且其分布你也知道,让你求x^2+y^2的分布一个道理,只不过抽样都是独立同分布而已1年前查看全部
- 以下数据中,求出平均数和众数,你认为用那个统计量来表示武术小组的年龄情况更合适?
以下数据中,求出平均数和众数,你认为用那个统计量来表示武术小组的年龄情况更合适?
5 9 10 5 9 9 12 6 9 9 9 8 7 9恨孔1年前1 -
长翅膀的兔子 共回答了15个问题
|采纳率73.3%平均数:(5 + 9 + 10 +5+ 9 + 9 + 12 + 6+ 9 + 9 +9 + 8+ 7 + 9)/14=8又2/7
众数:9
众数更合适1年前查看全部
- 方差已知的正太总体均值的检验要计算Z统计量.这句话是对事错
minmao1年前1
-
追寻光的轨迹 共回答了31个问题
|采纳率96.8%1.如果检验问题是看平均值是否随机来自同一正态母体,这句话就不对;
2.如果检验问题是比较两个母体间是否存在差异,这句话不算错;
但你给的这个句子本身就有毛病:“正太”?再就是光凭本句子还看不出你要解决的确切问题是什么?
请参考.1年前查看全部
- 常用的统计量有()数、()数和()数
rhkepssz1年前1
-
xierljy 共回答了20个问题
|采纳率85%众数,平均数,中位数1年前查看全部
- 常用的统计量有( )数、( )数、和( )数.
babyfishkelvin1年前1
-
avgirl520 共回答了14个问题
|采纳率85.7%常用的统计量有(平均 )数、( 中位)数、和( 众)数1年前查看全部
- 平均数、中位数和众数都是反映一组数据______的统计量.
qjl7121年前2
-
tkksy1997 共回答了12个问题
|采纳率91.7%解题思路:(1)平均数:平均数的计算中要用到每一个数据,因而它反映的是一组数据的总体水平.
(2)中位数:中位数是一组数据的中间量,代表了中等水平.
(3)众数代表的是一组数据的多数水平,众数反映了一组数据的集中趋势,当众数出现的次数越多,它就越能代表这组数据的整体状况,并且它能比较直观地了解到一组数据的大致情况;由此可知:平均数、中位数和众数都是反映一组数据集中趋势的统计量.平均数、中位数和众数都是反映一组数据集中趋势的统计量.
故答案为:集中趋势.点评:
本题考点: 众数的意义及求解方法;平均数的含义及求平均数的方法;中位数的意义及求解方法.
考点点评: 本题考查了众数与中位数平均数在一组数据中的作用.它们都是反映一组数据集中趋势的统计量.1年前查看全部
- 能够刻画一组数据离散程度的统计量是( )
能够刻画一组数据离散程度的统计量是( )
A. 平均数
B. 众数
C. 中位数
D. 方差蓝蛛蛛1年前1 -
微笑通过 共回答了20个问题
|采纳率100%解题思路:根据方差的意义可得答案.方差反映数据的波动大小,即数据离散程度.由于方差反映数据的波动情况,所以能够刻画一组数据离散程度的统计量是方差.
故选D.点评:
本题考点: 统计量的选择.
考点点评: 此题主要考查统计的有关知识,主要包括平均数、中位数、众数、方差的意义.反映数据集中程度的统计量有平均数、中位数、众数方差等,各有局限性,因此要对统计量进行合理的选择和恰当的运用.1年前查看全部
- 卡方拟合优度检验统计量的公式
BMW_7601年前1
-
醉倚望江楼 共回答了16个问题
|采纳率100%χ²=∑(Oi-Ei)/Ei~χ²(k-1)
i=1~k
Oi是观测值
Ei是期望值
统计量大于临界值时,拒绝原假设1年前查看全部
- spss主成分分析是否要做KMO和卡方统计量的检验?
spss主成分分析是否要做KMO和卡方统计量的检验?
生态学中在应用spss进行数据分析时,点击了 KMO and bartlette’s test选项,没有出现相应的KMO值和卡方统计量的值,出现了this matrix is not positive definite提示,但是还可以出现数据分析的结果,请问,这个数据的结果还可以使用吗?这个分析结果是否具有使用价值?能否能在科技论文中使用这些数据结果?飞机看来1年前3 -
ware03 共回答了20个问题
|采纳率90%是说这个矩阵不是正定的,我知道你可能还是不明白,我帮你查了很多资料,正定矩阵意思是说数据特征的特征值不是都大于0的,因此我推测你数据中可能存在问题,有负的特征值,怎么改数据,我还不清楚,我还得学习学习1年前查看全部
- 用独立性检验来考察两个分类变量x与y是否有关系,当统计量K2的观测值( )
用独立性检验来考察两个分类变量x与y是否有关系,当统计量K2的观测值( )
A.越大,“x与y有关系”成立的可能性越小
B.越大,“x与y有关系”成立的可能性越大
C.越小,“x与y没有关系”成立的可能性越小
D.与“x与y有关系”成立的可能性无关gand11年前1 -
zzd0627 共回答了14个问题
|采纳率85.7%解题思路:根据相关指数K2的观测值越大,“两个分类变量x与y是否有关系”,成立的可能性越大,可得答案.根据相关指数K2的观测值越大,“两个分类变量x与y是否有关系”,成立的可能性越大,
判定B正确.
故选:B.点评:
本题考点: 独立性检验.
考点点评: 本题考查了独立性检验的基础知识,熟练掌握相关指数K2的观测值的含义是关键.1年前查看全部
- 举例说明总体、样本、参数、统计量、变量这几个概念
no0131年前1
-
和阿超私奔 共回答了16个问题
|采纳率93.8%总体(population)是包含所研究的全部个体(数据)的集合.样本是从总体中抽取的一部分元素的集合.参数是用来描述总体特征的概括性数字度量.统计量是用来描述样本特征的概括性数字度量.变量是说明现象某种特征的概念.比如我们欲了解某市的中学教育情况,那么该市的所有中学则构成一个总体,其中的每一所中学都是一个个体.我们若从全市中学中按某种抽样规则抽出了10所中学,则这10所中学就构成了一个样本.在这项调查中我们可能会对升学率感兴趣,那么升学率就是一个变量.我们通常关心的是全市的平均升学率,这里这个平均值就是一个参数.而此时我们只有样本的有关升学率的数据,用此样本计算的平均值就是统计量.1年前查看全部
大家在问
- 1【求助】英语S后的音标变化规则如sports中s后的p要变成b、stand后的t要变成d等.但好像有些s在中间的单词不变
- 2写出下列反应的化学方程式:①钠投入水中______②二氧化碳通到过氧化钠中______③铁在氯气中燃烧2Fe+3Cl2&
- 31.已知三角形ABC的三边分别为A.B.C,且满足a2(平方)+b2(平方)+c2(平方)=ab+bc+ac.请判断三角
- 4将正方形ABCD沿对角线BD折成直二面角A-BD-C,有如下四个结论:
- 5爱·不爱 作文
- 6在标准状况下,m升二氧化碳中含有n个氧原子,则阿伏加得罗常数为.
- 7一堆煤,第一次运走它的1/4,第二次又运走120吨,这时余下的煤的吨数与运走的吨数的比是2/3.这堆煤.
- 8把一张长方形纸ABCD沿对角线对折,重叠部分为三角形FBD
- 9AMS2750D标准中仪表类型是什么意思?A、B、C、D型仪表表示含义
- 10酒精度是12.
- 11A与B互质,且A+B=2008,A大于B,问(A,B)共有多少对?
- 12生命之歌这篇课文想到了哪些成语
- 131.是否存在大于1的正整m数使得f(n)=n^3+5n对任意正整数n都能被m整除?
- 14在方格中画一个面积为6平方厘米的平行四边形、一个三角形、一个梯形.
- 15(2011•淄博)化学是在原子、分子的水平上对物质进行研究的基础自然学科.请你运用分子的性质判断,以下事实的解释错误的是