线性回归分析中为什么把解释变量假设为非随机变量,
 wangying980410382022-10-04 11:39:542条回答
wangying980410382022-10-04 11:39:542条回答
已提交,审核后显示!提交回复
共2条回复
 6目 共回答了16个问题
6目 共回答了16个问题 |采纳率100%- 因为是现行回归了,
比如对于两个变量的,x,y,
假设了用解释变量x的方程式表示y,
此时只有确定x,才能有对应的y预测值
因此x此时不是随机变量, - 1年前
- ccc5566 共回答了1个问题
|采纳率 - 因为是现行回归了,
比如对于两个变量的,x,y,
假设了用解释变量x的方程式表示y,
此时只有确定x,才能有对应的y预测值
因此x此时不是随机变量, - 1年前
相关推荐
- 统计学中的线性回归部分E(y|x)是什么
daobagege1年前1
-
晓看晨曦 共回答了18个问题
|采纳率88.9%这个是y在x下的条件期望.
这部分比较复杂的,一般情况下,不想做这种题目.1年前查看全部
- 下列是某厂1~4月份用水量(单位:百吨)的一组数据,由其散点图可知,用水量y与月份x之间有较好的线性相关关系,其线性回归
下列是某厂1~4月份用水量(单位:百吨)的一组数据,由其散点图可知,用水量y与月份x之间有较好的线性相关关系,其线性回归方程是
=-0.7x+
b
,则a
=______.a
月份x 1 2 3 4 用水量y 4.5 4 3 2.5 handsomehand1年前1 -
fengcloudy 共回答了23个问题
|采纳率95.7%解题思路:根据所给的数据,做出x,y的平均数,即得到样本中心点,根据所给的线性回归方程,把样本中心点代入,只有a一个变量,解方程得到结果.∵
.
x=
1+2+3+4
4=2.5
.
y=
4.5+4+3+2.5
4=3.5
∴
a=
.
y-
b
.
x=3.5+0.7×2.5=5.25.
故答案为:5.25点评:
本题考点: 线性回归方程.
考点点评: 本题考查线性回归方程,考查样本中心点的性质,考查线性回归方程系数的求法,是一个基础题,本题运算量不大,是这一部分的简单题目.1年前查看全部

- 设 , , , 是变量x和y的n个样本点,直线 是由这些样本点通过最小二乘法得到的线性回归直线(如图),以下
设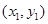 ,
,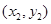 ,
, ,
,  是变量x和y的n个样本点,直线
是变量x和y的n个样本点,直线 是由这些样本点通过最小二乘法得到的线性回归直线(如图),以下结论中正确的是
是由这些样本点通过最小二乘法得到的线性回归直线(如图),以下结论中正确的是A.x和y相关系数为直线l的斜率 B.x和y的相关系数在0到1之间 C.当n为偶数时,分布在l两侧的样本点的个数一定相同 D.直线 过点
 红丝一剪疯1年前1
红丝一剪疯1年前1 -
花雨下 共回答了21个问题
|采纳率90.5%设 ,
, ,
, ,
,  是变量x和y的n个样本点,直线
是变量x和y的n个样本点,直线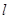 是由这些样本点通过最小二乘法得到的线性回归直线(如图),以下结论中正确的是
是由这些样本点通过最小二乘法得到的线性回归直线(如图),以下结论中正确的是
A.x和y相关系数为直线l的斜率
B.x和y的相关系数在0到1之间
C.当n为偶数时,分布在l两侧的样本点的个数一定相同
D.直线 过点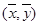
D
分析:对于所给的线性回归方程对应的直线,针对于直线的特点,回归直线一定通过这组数据的样本中心点,得到结果.
直线l是由这些样本点通过最小二乘法得到的线性回归直线,
回归直线方程一定过一遍中心点,
故选D.1年前查看全部







- 线性相关和线性回归的含义和概念(英文)统计学
线性相关和线性回归的含义和概念(英文)统计学
Explain the meanings and theoretical basis of linear correlation and regression analysis
宝贝云飞扬1年前1 -
ricane 共回答了14个问题
|采纳率85.7%http://wenku.baidu.com/view/d7c29b6825c52cc58bd6bec5.html 去这里看看。可能有你想要的答案1年前查看全部
- 散点图中绝大多数点都线性相关,个别特殊点不影响线性回归,
娜娜爱邓邓1年前1
-
主人 共回答了17个问题
|采纳率88.2%答案:有一类卑微的工作是用坚苦卓绝的精神忍受着的,最低陋的事情往往指向最崇高的目标.1年前查看全部
- 线性回归里那个符号是什么意思?
czping52014131年前1
-
MOBO箐箐 共回答了15个问题
|采纳率100%Σ表示求和,就是当 i从1取到n时,后面表达式的和.
比如分子,
就是 (x1+x平)(y1-y平) + (x2+x平)(y2-y平) + (x3+x平)(y3-y平) + …… + (xn+x平)(yn-y平)1年前查看全部
- spss 一元线性回归对一组数据(两列)进行一元线性回归,得到如下结果,请问我能得出Y=A+BX么?可靠么?Correl
spss 一元线性回归
对一组数据(两列)进行一元线性回归,得到如下结果,请问我能得出Y=A+BX么?可靠么?
Correlations
VAR00001 VAR00002
VAR00001 Pearson Correlation 1 0.601
Sig.(2-tailed) 0.000
N 238 238
VAR00002 Pearson Correlation 0.601 1
Sig.(2-tailed) 0.000
N 238 238
**.Correlation is significant at the 0.01 level (2-tailed).
Variables Entered/Removed(b)
Model Variables Entered Variables Removed Method
1 VAR00002(a) .Enter
a.All requested variables entered.
b.Dependent Variable:VAR00001
Model Summary
Model R R Square Adjusted R Square Std.Error of the Estimate
1 0.601 0.361 0.358 0.0411108
a.Predictors:(Constant),VAR00002
ANOVA(b)
Model Sum of Squares df Mean Square F Sig.
1 Regression 0.225 1 0.225 133.104 0.000
Residual 0.399 236 0.002
Total 0.624 237
a.Predictors:(Constant),VAR00002
b.Dependent Variable:VAR00001
Coefficients(a)
Model Unstandardized Coefficients Standardized Coefficients t Sig.
B Std.Error Beta
1 (Constant) 0.001 0.003 0.328 0.743
VAR00002 0.879 0.076 0.601 11.537 0.000
a.Dependent Variable:VAR00001tigerintherain1年前1 -
wanglinet 共回答了16个问题
|采纳率93.8%相关分析表(Correlations)表明两个变量的线性相关性较强(r = 0.601)较显著(p = 0.000):提示两个变量之间在较大的程度上可以进行直线回归.
Model summary表显示线性回归的决定系数Rsquare = 0.361,说明回归的不太好,一部分与回归线偏离太大.
ANOVA表显示直线回归具有很强的显著性(P = 0.000),说明用直线回归是非常合适的.
Coefficients 表显示对于公式"Y = a + bx"来说,a = 0.001,b = 0.879.但是a值的显著性系数太大(0.743 > 0.05),说明应该在这个公式里面去掉常数项a.
b值的显著性系数说明b值是合适的.
重新做一遍回归,这次去掉常数项.
去掉常数项的方法为:
Analyze - Regression - Linear - Options
然后在"Linear regression:Options" 对话框中将“Include constant in equation”项去掉即可.1年前查看全部
- 不同年份的数据可以做线性回归吗?还是属于时间序列分析?
不同年份的数据可以做线性回归吗?还是属于时间序列分析?
想要研究影响每年***数量的因素,有多个变量,都是根据时间不同发生变化的.这样的模型是属于回归模型还是时间序列模型?
单刀雪兰莪1年前1 -
行痴dashi 共回答了10个问题
|采纳率100%属于时间序列预测
如果用简单的回归模型来做 并不是很准确的
在spss中有一项是预测的菜单,其中就是考虑时间序列后的分析预测,有点类似于回归分析,但是它会考虑到时间序列的影响,同时也有自变量和因变量的1年前查看全部
- 一元线性回归的问题我做的一元线性回归方程,spss结果显示常数项值为0.27,其p值为0.68,这样的话,我还能将这个常
一元线性回归的问题
我做的一元线性回归方程,spss结果显示常数项值为0.27,其p值为0.68,这样的话,我还能将这个常数项用到我的方程例吗?如果能,依据是什么?不能的话,依据就是因为p大于0.05吗?Anemone1年前1 -
liqilin331 共回答了22个问题
|采纳率86.4%常数项用来反映剩余回归的(抛去误差) 计算机检验剩余回归的时候是没有刨去误差的,做回归一定要看三项检验P值,系数检查(除去常数) 回归检查 剩余检查(失拟检查)一定是三项P值都满足才可以 认为回归是好的 否则...1年前查看全部
- 以下关于线性回归的判断,正确的有( )个.
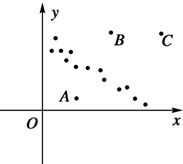 以下关于线性回归的判断,正确的有( )个.
以下关于线性回归的判断,正确的有( )个.
①若散点图中所有点都在一条直线附近,则这条直线为回归直线
②散点图中的绝大多数点都线性相关,个别特殊点不影响线性回归,如图中的A,B,C点.
③已知回归直线方程为
=0.50x-0.81,则x=25时,y的估计值为11.69
y
④回归直线方程的意义是它反映了样本整体的变化趋势.
A.0个
B.1个
C.2个
D.3个门槛11年前1 -
阚雨 共回答了23个问题
|采纳率91.3%解题思路:利用线性回归方程的概念及意义对①②③④四个选项逐一判断即可.能使所有数据点都在一条直线附近的直线不止一条,而回归方程的定义知,只有按最小二乘法求得回归系数a,b得到的直线
̂
y=ax+b才是回归方程,
∴①不对;
②散点图中的绝大多数点都线性相关,个别特殊点不会影响线性回归,是正确,故②正确;
③将x=25代入
̂
y=0.50x-0.81,解得
̂
y=11.69,
∴③正确;
④散点图中所有点都在回归直线的附近,因此回归直线方程反映了样本整体的变化趋势,故④正确;
综上所述,正确的有3个.
故选:D.点评:
本题考点: 命题的真假判断与应用;线性回归方程.
考点点评: 本题考查命题的真假判断与应用,着重考查线性回归方程的概念与应用,属于中档题.1年前查看全部
- 如何将这个函数通过变换化成线性回归形式
如何将这个函数通过变换化成线性回归形式
其中a,b,c为未知常数
因为a,b均为未知常数,所用求不出来t
线性回归有多元线性回归,这里有三个未知数,当然要用三元线性回归了。
 涧边幽草20061年前4
涧边幽草20061年前4 -
luowen401 共回答了19个问题
|采纳率94.7%令t=√(ax+b),其中ax+b>=0,x>=-b/a,y>=c,则有:
y=t+c
可以根据题意先求出关于t的结果,最后再用x=(t^2-b)/a代回即可1年前查看全部
- 线性回归中有的有的自变量sig大于0.05怎么调整
ximengyixue1年前1
-
cddk 共回答了19个问题
|采纳率100%sig>0.05 说明他的作用不明显,有以下两种最初级的方法
1.把他丢掉试一试
2.尝试加入与其相关的交互项1年前查看全部
- SAS线性回归结果中的方差分析怎么看?这张图里面的SST、SSR、SSE怎么看?
短线金股1年前1
-
lnmzzt 共回答了23个问题
|采纳率78.3%误差看平方和一列,模型一行是组间、误差一行是组内,合计是总体误差
SST=278.9475
SSR=183.24469
SSE=95.702811年前查看全部
- 二元线性回归的系数如何计算?比如说我有十个呈线性相关的数字,放在直角坐标内即(x1,y1),(x2,y2)·······
二元线性回归的系数如何计算?
比如说我有十个呈线性相关的数字,放在直角坐标内即(x1,y1),(x2,y2)·········(x10,y10),计算其系数的方法或者公式是怎样的,知道的大侠帮忙提点下,在下十分感激!834021年前1 -
sunwenchao1983 共回答了17个问题
|采纳率88.2%polyfit(X,Y,1)1年前查看全部
- 设回归函数形为y=x/(a+bx),试找出一个变换使其化为一元线性回归的形式
楼谈会1年前1
-
jjiwai 共回答了12个问题
|采纳率83.3%1/y=(a+bx)/x=a/x+b
令y'=1/y, x'=1/x
则方程化为:y'=ax'+1年前查看全部
- 为了考察两个变量x和y之间的线性相关性,甲、乙两个同学各自独立地做了10次和15次试验,并且利用线性回归方法,求得回归直
为了考察两个变量x和y之间的线性相关性,甲、乙两个同学各自独立地做了10次和15次试验,并且利用线性回归方法,求得回归直线分别为l1和l2.已知两个人在试验中发现对变量x的观测数据的平均数都为s,对变量y的观测数据的平均数都为t,那么下列说法正确的是( )
A.l1与l2有公共点(s,t)
B.l1与l2相交,但交点不是(s,t)
C.l1与l2平行
D.l1与l2重合slain1年前1 -
8317569 共回答了9个问题
|采纳率100%解题思路:由题意知,两个人在试验中发现对变量x的观测数据的平均值都是s,对变量y的观测数据的平均值都是t,所以两组数据的样本中心点是(s,t),回归直线经过样本的中心点,得到直线l1和l2都过(s,t).∵两组数据变量x的观测值的平均值都是s,对变量y的观测值的平均值都是t,
∴两组数据的样本中心点都是(s,t)
∵数据的样本中心点一定在线性回归直线上,
∴回归直线t1和t2都过点(s,t)
∴两条直线有公共点(s,t)
故选A.点评:
本题考点: 回归分析的初步应用.
考点点评: 本题考查回归分析,考查线性回归直线过样本中心点,考查学生分析解决问题的能力,属于基础题.1年前查看全部
- 一元线性回归案例中最小二乘法y=bx+a,其中的b和a的公式!
zhaohong1年前0
-
共回答了个问题
|采纳率
- 为了考察两个变量x和y之间的线性相关性,甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方法,求得回归直线
为了考察两个变量x和y之间的线性相关性,甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方法,求得回归直线分别为l1和l2,已知两个人在试验中发现对变量x的观测数据的平均值都是s,对变量y的观测数据的平均值都是t,那么下列说法正确的是( )
A. l1和l2必定平行
B. l1与l2必定重合
C. l1和l2有交点(s,t)
D. l1与l2相交,但交点不一定是(s,t)章延龙1年前1 -
decadence_ 共回答了18个问题
|采纳率94.4%解题思路:由题意知,两个人在试验中发现对变量x的观测数据的平均值都是s,对变量y的观测数据的平均值都是t,所以两组数据的样本中心点是(s,t),回归直线经过样本的中心点,得到直线l1和l2都过(s,t).∵两个人在试验中发现对变量x的观测数据的平均值都是s,对变量y的观测数据的平均值都是t,
∴两组数据的样本中心点是(s,t)
∵回归直线经过样本的中心点,
∴l1和l2都过(s,t)
故选C.点评:
本题考点: 回归分析.
考点点评: 本题考查回归分析,考查线性回归直线过样本中心点,在一组具有相关关系的变量的数据间,这样的直线可以画出许多条,而其中的一条能最好地反映x与Y之间的关系,这条直线过样本中心点.1年前查看全部
- 自回归分析法和一元线性回归有什么不同
自回归分析法和一元线性回归有什么不同
交通运输学老师提出的问题,自回归方程Y(下标t)=b(下标0)+b(下标1)Y(下标t-r
)一元线性回归方程,Y(下标i)=a+bx(下标i)39501851年前1 -
disipi 共回答了13个问题
|采纳率92.3%一般来说,一元线性回归之y=a+bx形式的回归模型,其中y叫做被解释变量(因变量),x叫做解释变量(自变量).而自回归用于时间序列分析,它把时间序列的滞后项作为解释变量,它可以看作是一元线性回归的一种特殊形式,即“自己的过去作为自己的现在解释”.在自回归中,因为自变量和因变量存在相关性,违背了经典回归分析的假设,所以得到的统计量不是最优的,但是在大样本情况下是渐进有效的,时间序列通常是大样本,所以还是可以用自小二乘方法估计方程的参数.不知道我说清楚没有.1年前查看全部
- minitab一元线性回归分析的系数T和P到底什么意思?
minitab一元线性回归分析的系数T和P到底什么意思?
为什么说T越大越好,超过三就说明其准确度高,还有为什么P这么小通常会出现0的情况,小概率事件不是应该不打好吗?zfr85041年前1 -
霹雳帕拉 共回答了8个问题
|采纳率87.5%T是统计量的值,由于T分布的特性是:取值离远点越远,取到这个值的可能性越小.而在回归分析里,我们的检验的假设是“X的系数=0(当此时,X和Y无关)”,所以T值(的绝对值)越大越好,因为越大,就说明检验的假设越不可能发生,这样,X和Y的关系就越显著(系数越不可能为0).
T值对应的P值,一般在一元回归的报告里是做的双边检验:也就是说,你回归的检验里,T分布取值大于你求出的T统计值的可能性(加绝对值的),如果P值很大,说明这个T值很靠近原点,而P值很小,则说明这个T值远离原点(T的绝对值越大,P越小),根据上面的分析,P越小越好.1年前查看全部
- 计量经济学简单线性回归中答案的意思
计量经济学简单线性回归中答案的意思
对回归模型的参数进行估计,根据回归结果得:
= 6.017832 - 0.070414
(1.052260)(0.014176)
t = (5.718961)(-4.967254)
=0.778996 F=24.67361 S.E.=0.160818 DW=2.526971
答案中(1.052260)(0.014176) DW=2.5269712007阳历12月1年前1 -
喜欢绿豆沙 共回答了19个问题
|采纳率94.7%第一行括号是标准差,对应上面的参数(下同),standard error,第二行括号是t统计量,DW是杜宾-沃特森检验统计值.1年前查看全部
- 怎样求解线性回归中的正规方程组(手算)
便冒出1年前1
-
悍马11 共回答了21个问题
|采纳率85.7%那我就慢慢跟你说吧
先说二个不等式的的...
举个例子
x+2y≤2
x+5y≤3
求z=5x+19y的最大值
先把5x+19y化成2(x+2y)+3(x+5y) ≤13
仅当x+2y=2 x+5y=3 取等号
这样的x和y是存在的..注意要化成含有两个不等式的情况才能用
至于前面那个系数怎么样得出
就是这样的.
设z=a(x+2y)+b(x+5y)=(a+b)x+(2a+5b)y
然后对应那个系数就有a+b=5 2a+5b=19
解出a=2 b=3 就是这样
那么三个不等式的怎么办呢
例如
x+2y≤2
-x+3y≤3
x≥2
求z=-2x+14y的最大.最小值
-2x+14y=2(x+2y)+4(-x+3y)≤16 最大值为16
-2x+14y=14/3(-x+3y)+(8/3)x 这个无不等关系
-2x+14y=6x-7(x+2y)≥12-14=-2 最小值为-2
要每条式子都要组合一次进行计算,再比较.这样就可以了...不用画图...方程越多就越麻烦的...1年前查看全部
- 统计学 这一题怎么求 判定系数 相关系数 一元线性回归
jasonyama19861年前0
-
共回答了个问题
|采纳率
- 已知x,y之间的数据如下表所示,则Y与x之间的线性回归直线一定过点______.
已知x,y之间的数据如下表所示,则Y与x之间的线性回归直线一定过点______.
x 1.13 1.17 1.24 1.26 y 2.25 2.37 2.40 2.58 帅不到掉渣1年前1 -
匿名乖宝宝 共回答了15个问题
|采纳率86.7%解题思路:由线性回归直线一定过样本点的中心可知,求出样本点的中心坐标即可.由题意,
.
x=[1.13+1.17+1.24+1.26/4]=1.2,
.
y=[2.25+2.37+2.40+2.58/4]=2.4;
故由线性回归直线一定过样本点的中心可知,
线性回归直线一定过点(1.2,2.4);
故答案为:(1.2,2.4).点评:
本题考点: 线性回归方程.
考点点评: 本题考查了线性回归直线一定过样本点的中心,属于基础题.1年前查看全部
- 以下有关线性回归分析的说法不正确的是 A.通过最小二乘法得到的线性回归直线经过样本的中心 B.用最小二乘法求回归直线方程
以下有关线性回归分析的说法不正确的是
A.通过最小二乘法得到的线性回归直线经过样本的中心 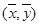
B.用最小二乘法求回归直线方程,是寻求使  最小的 a , b 的值
最小的 a , b 的值C.相关系数r越小,表明两个变量相关性越弱 D.  越接近1,表明回归的效果越好suaihui1231年前1
越接近1,表明回归的效果越好suaihui1231年前1 -
63221841 共回答了20个问题
|采纳率90%解题思路:对于A.通过最小二乘法得到的线性回归直线经过样本的中心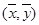 ,显然成立。
,显然成立。
对于B.用最小二乘法求回归直线方程,是寻求使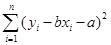 最小的 a , b 的值,符合定义。
最小的 a , b 的值,符合定义。
对于C.相关系数r越小,表明两个变量相关性越弱,应该是绝对值越小,相关性越弱,故错误。
对于D. 越接近1,表明回归的效果越好,成立,故选C.
C
<>1年前查看全部



- (2012•云南模拟)为研究变量x和y的线性相关性,甲、乙二人分别作了研究,利用线性回归方法得到回归直线方程l1和l2,
(2012•云南模拟)为研究变量x和y的线性相关性,甲、乙二人分别作了研究,利用线性回归方法得到回归直线方程l1和l2,两人计算知
相同,.x
也相同,下列正确的是( ).y
A.l1与l2一定重合
B.l1与l2一定平行
C.l1与l2相交于点(
,.x
).y
D.无法判断l1和l2是否相交rain20561年前0 -
共回答了个问题
|采纳率
- 线性回归问题有一道线性回归的题,让找出汽车价格于车的使用年龄的关系.X=1,2,3,4,5年,Y每年分别有10个价格,现
线性回归问题
有一道线性回归的题,让找出汽车价格于车的使用年龄的关系.X=1,2,3,4,5年,Y每年分别有10个价格,现在让我求回归方程,那我怎么确定Y的值呢,可以取这10个价格的平均数吗?李智5211年前2 -
妇女mmmm 共回答了19个问题
|采纳率78.9%确定每一年的价格可以直接将这10个价格取平均,也可以去掉最高和最低价然后取平均,只要合情合理就行了.
确定每一年的价格后代入回归方程,求出回归系数就行了1年前查看全部
- 大学化学里的吸光度分析以及线性回归的一个小小的疑问
大学化学里的吸光度分析以及线性回归的一个小小的疑问

这是测量直链淀粉含量的一个实验(楼主是学食品的),在得到所有数据并制作线性回归直线计算样品中直链淀粉含量时候,吸光度和直链淀粉在不同的坐标轴中,最后所得出来的结果就不同(右上角样品的两个数据:25.9%和26.1%),虽然差别不大,但总归觉得哪里不对,教科书上是叫我们以吸光度为纵坐标,直链淀粉含量为横坐标图(1),但是图二就是错的么?.喜剧片1年前1 -
Toread 共回答了21个问题
|采纳率90.5%简单的线性回归中,x 轴和 y 轴的地位是不等价的,一定要按照正确的坐标轴画图回归,否则得到的结果是不可靠的.
这是回归理论决定的.在线性回归时,认为 x 是没有测量误差的(或者说测量误差可以忽略),只有 y 有测量误差的,在这个基础上导出的拟合公式.所以一定要选测量误差误差小的作为 x 轴.这也导致交换 xy 轴回归结果不一样.1年前查看全部
- spss线性回归结果分析F 统计量值为 15.916,F 统计量伴随的 P 值小于 0.001,在 0.001 的显著性
spss线性回归结果分析

F 统计量值为 15.916,F 统计量伴随的 P 值小于 0.001,在 0.001 的显著性水平下通过了检验

表中常数在 0.005 水平下显著,X1在 0.001 水平下显著相关
.
(1)中F伴随的p值小于0.001,是怎么看出来的?
(2)常数在0.005下显著,以及x1在0.001下显著是怎么看出来的?
(3)x2,x3 的sig 值不是大于0.00,系数还显著的么?
spss菜鸟一枚,最近做论文需要用到这方面的分析.请大神指教下.caoyang84481年前1 -
梦仙子 共回答了14个问题
|采纳率92.9%(1)中F伴随的p值小于0.001,是怎么看出来的?
(2)常数在0.005下显著,以及x1在0.001下显著是怎么看出来的?
就是看最后一列的sig值,就是P值.它小于显著性水平,比如0.05,就显著.否则就不显著.
3,sig值大于0.05,就不显著了.
统计人刘得意1年前查看全部
- 已知x,Y之间的数据如下表所示,则Y与x之间的线性回归直线一定过点________.
已知x,Y之间的数据如下表所示,则Y与x之间的线性回归直线一定过点________.
x 1.08 1.12 1.19 1.28 Y 2.25 2.37 2.40 2.55 黎布1年前1 -
-哦- 共回答了22个问题
|采纳率86.4%(1.167 5,2.392 5)
回归直线一定过样本中心点( ,
,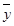 ),由已知数据得, =1.167 5, =2.392 5.
1年前查看全部
),由已知数据得, =1.167 5, =2.392 5.
1年前查看全部


- 用eviews软件做一元线性回归,如果不加常数项,结果就出现负值,请问这是为什么?
用eviews软件做一元线性回归,如果不加常数项,结果就出现负值,请问这是为什么?
不要跟我说加上常数项就没事了,请阐述原因
victorwang251年前1 -
月满西楼abc 共回答了22个问题
|采纳率86.4%加不加常数项影响的是回归系数计算矩阵的结构
所以不加常数项就出现负值
这是一个计算过程,没有什么特殊原因1年前查看全部
- 在一元线性回归中随机误差存在异方差是什么意思?该怎么办?
lxninglove1年前1
-
jane3025 共回答了15个问题
|采纳率80%随机误差项满足同方差性,即它们都有相同的方差.如果不同,就为异方差.在一元线性回归中是假设ε满足E(ε)=0,Var(ε)=σ²的.1年前查看全部
- 最小二乘法(线性回归)的误差最小二乘法(线性回归)的误差怎么求:Y=A×X+B,有一组Xi,Yi可以求出最佳A,B然而X
最小二乘法(线性回归)的误差
最小二乘法(线性回归)的误差怎么求:
Y=A×X+B,有一组Xi,Yi可以求出最佳A,B
然而Xi,Yi都有误差,则A,B都有误差
我确定在《金牌之路》(张大同)上有,只是书手边没有.zuyue11221年前1 -
fairystory 共回答了21个问题
|采纳率90.5%Xi = Xio(1±Δxi)
Yi = Yio(1±Δyi)
Δ是相对误差
用Xio和Yio算得A,B,再用Xi,Yi算A',B'
相减不就是误差了么,期间还可以根据需要略去Δ的二阶量
不过我还是觉得算期望和方差更好1年前查看全部
- 50分一道计量经济学题目假设已经得到简单线性回归模型的最小二乘估计,若把解释变量单位扩大十倍,对原回归模型的斜率和截距有
50分一道计量经济学题目
假设已经得到简单线性回归模型的最小二乘估计,若把解释变量单位扩大十倍,对原回归模型的斜率和截距有什么样影响hobluE1年前2 -
深秋的zz城 共回答了15个问题
|采纳率100%斜率缩小10倍,截距没影响1年前查看全部
- 请教SPSS进行一元线性回归分析的一般步骤
请教SPSS进行一元线性回归分析的一般步骤
还有,应该对哪些指标进行判断来确定相关性、拟合的好坏等
我这儿有个例子,请结合例子讲解,
分析广告费与销售额的关系
(由于字数限制,略去原始数据)
输入/移去的变量(b)
模型 输入的变量 移去的变量 方法
1 广告费a .输入
a.已输入所有请求的变量.
b.因变量:销售额
模型汇总
模型 R R 方 调整 R 方 标准 估计的误差
1 .786a .618 .570 42.35795
a.预测变量:(常量),广告费.
Anova(b)
模型 平方和 df 均方 F Sig.
1 回归 23206.435 1 23206.435 12.934 .007a
残差 14353.565 8 1794.196
总计 37560.000 9
a.预测变量:(常量),广告费.
b.因变量:销售额
系数(a)
非标准化系数 标准系数
模型 B 标准 误差 试用版 t Sig.
1 (常量) 309.528 43.402 7.132 .000
广告费 4.068 1.131 .786 3.596 .007
a.因变量:销售额
相关性
广告费 销售额
广告费 Pearson 相关性 1 .786**
显著性(双侧) .007
N 10 10
销售额 Pearson 相关性 .786** 1
显著性(双侧) .007
N 10 10封情十月1年前1 -
我是无怨无 共回答了16个问题
|采纳率93.8%一个自变量 一个因变量
如果要进行线性回归,无论是一元还是多元,第一步首先应该先画下散点图,看是否有线性趋势,如果有线性趋势了,再使用线性回归.这个是前提,现在很多人都忽略这一点 直接使用的.
至于判断线性方程 拟合的好坏,看R方和调整的R方就可以了,R方越接近1,说明拟合的效果越好.你这个里面 R方为0.618,调整的R方为0.570,说明这个自变量可以解释因变量57%左右的变异,不能说好,也不能说坏.看具体情况而定
Anova(b)这个表格是检验 回归方程是否显著的,sig的值=0.007 小于0.05,说明回归模型有意义,可以使用.
下面一个标准化回归系数 和非标准化回归系数 则是回归方程自变量的系数,非标准化的系数用来拟合方程使用,标准化的系数是剔除了不同自变量的不同计量单位影响的,用于比较多个自变量的影响大小1年前查看全部
- 数学线性回归中的significance level of entry and removal是
数学线性回归中的significance level of entry and removal是
么
椰风学子1年前1 -
巴黎圣日尔曼 共回答了17个问题
|采纳率94.1%significance level 显著性水平1年前查看全部
- 知道一组数据,如何用matlab的线性回归和线性拟合求出两者的关系函数,求代码?
知道一组数据,如何用matlab的线性回归和线性拟合求出两者的关系函数,求代码?
t=[1999 2000 2001 2002 2003 2004 2005 2006 2007 2008]
c=[399.72 506.97 754.98 989.4 1202.48 1473.29 1525 1717.87 1911.45 2004.25]
求t表达c.gg的西瓜1年前1 -
solosama 共回答了18个问题
|采纳率88.9%figure;
t=[1999 2000 2001 2002 2003 2004 2005 2006 2007 2008];
c=[399.72 506.97 754.98 989.4 1202.48 1473.29 1525 1717.87 1911.45 2004.25];
a=polyfit(t,c,2);
ti=1999:1:2008;
ci=polyval(a,ti);
plot(t,c,'go','MarkerEdgeColor','k','MarkerFaceColor','g','MarkerSize',6);
xlabel('年份');
ylabel('相关数据');
axis([1999 2008 350 2100])
hold on
plot(ti,ci,'linewidth',2,'markersize',16)
legend('原始数据点','拟合曲线')
plot(t,c,'-r.')
sprintf('曲线方程:C=%0.5g*T^2+(%0.5g)*T+(%0.5g)',a(1),a(2),a(3))
曲线方程:C=-5.5245*T^2+(22324)*T+(-2.255e+007)
这是2次线性相关
figure;
t=[1999 2000 2001 2002 2003 2004 2005 2006 2007 2008];
c=[399.72 506.97 754.98 989.4 1202.48 1473.29 1525 1717.87 1911.45 2004.25];
a=polyfit(t,c,1);
ti=1999:1:2008;
ci=polyval(a,ti);
plot(t,c,'go','MarkerEdgeColor','k','MarkerFaceColor','g','MarkerSize',6);
xlabel('年份');
ylabel('相关数据');
axis([1999 2008 350 2100])
hold on
plot(ti,ci,'linewidth',2,'markersize',16)
legend('原始数据点','拟合曲线')
plot(t,c,'-r.')
sprintf('曲线方程:C=+(%0.5g)*T+(%0.5g)',a(1),a(2),)
曲线方程:C=+(187.66)*T+(-3.7473e+005)
这是一次的线性相关1年前查看全部
- 如何对两变量进行一元线性回归分析
qiushuirm1年前1
-
林熙830524 共回答了18个问题
|采纳率88.9%一个变量,做自变量x,一个是因变量y.导入
eviews,点击esimate,y= c x,结果就出来了.1年前查看全部
- 一元线性回归分析中,对回归方程要做哪些检验?若判定细数等于22%意味着什么?(统计学问题)
laomaozi1年前1
-
a0602206 共回答了14个问题
|采纳率100%在一元回归情形,检验的话,相关系数检验、F检验、T检验的检验结果是一样的,所以只做简单的相关检验r 就可以了.r=22%,(01年前查看全部
- 统计学中线性相关和线性回归的区别.
宝贝疙瘩丹1年前2
-
咫尺多一点 共回答了17个问题
|采纳率100%主要区别有三点:
1.线性相关分析涉及到变量之间的呈线性关系的密切程度,线性回归分析是在变量存在线性相关关系的基础上建立变量之间的线性模型;
2.线性回归分析可以通过回归方程进行控制和预测,而线性相关分析则无法完成;
3.线性相关分析中的变量地位平等,都是随机变量,线性回归分析中的变量有自变量和因变量之分,而自变量一般属确定性变量,因变量是随机变量.1年前查看全部
- 线性回归分析自变量p值必须小于0.05才能入选回归方程式吗
winning2171年前1
-
dragon_c 共回答了13个问题
|采纳率69.2%范围一般可扩大到1年前查看全部
- 一元线性回归分析中待定系数a为什么是负数
zhang1c1年前1
-
sammiyuan0320 共回答了22个问题
|采纳率90.9%不一定是负数 吧1年前查看全部
- x+y=1 y≥0 求x+y最值.求如何利用线性回归解决这道题.
美好回忆11年前1
-
北方的大雪 共回答了22个问题
|采纳率90.9%在坐标系画个半圆 圆心是原点 半径是1 取x轴上方的部分 然后画斜率是-1的直线 最大值是与圆相切时直线与y轴交点 最小值是过(-1,0)时直线与y轴交点1年前查看全部
- 统计学中,一元线性回归的字母问题,
统计学中,一元线性回归的字母问题,
一元线性回归的结果中,Significance F的回归分析为 7.22962E-12 如何计算这个数值?如何把它和显著性水平阿尔法=0.05比较?lyyx91年前1 -
lhzh2000 共回答了20个问题
|采纳率90%这还怎么计算,都用软件的,你regress出来的output里就有F的probability的数值,用那个数值直接和0.05比较就行.如果用的stata,直接输入命令也会在窗口算好给你的(别问我command是什么,我也记不得了)1年前查看全部
- 用MATLAB求二元线性回归方程系数
用MATLAB求二元线性回归方程系数
Y=a0+a1x1+a2x2,假设有10组关于Y,x1,x2的数据,怎么求a1,a2,a3的系数呢爱上天是1年前1 -
mrq1983 共回答了18个问题
|采纳率83.3%可以不用拟合工具箱,直接用矩阵除法即可!因为为线性
求a1,a2即把a1,a2当成未知数,x1,x2,Y-a0当成已知量
则x1*a1+x2*a2=Y-a0,即[x1,x2]*[a1;a2]=Y-a0
令矩阵A=[x1,x2]=[x1(0),x2(0);
x1(1),x2(1);
.,.
x1(10),x2(10)]
B=y-a0=[y(0)-a0;
y(1)-a0;
.;
y(10)-a0]
则[a1,a2]=AB
即求出a,a2值,实质也是利用最小二乘法!
希望我的回答能帮助你!1年前查看全部
- 为什么伍德里奇计量经济学简单线性回归模型中没有ui和uj不相关的假定
眼黄金41年前1
-
ljhstar 共回答了18个问题
|采纳率88.9%ui和uj是否相关并不影响参数估计的无偏性.即使存在序列相关,参数估计仍是无偏的,只不过显著性会有所下降.
在实际应用中,如果结果是显著的,完全可以不考虑序列是否相关.当然如果结果是不显著的,就要看原因了.如果你认为结果应该显著,可是由于数据上的自相关导致显著性下降,就要对序列相关进行处理了.1年前查看全部
- 在一元线性回归中,t检验与f检验是一致的.证明过程。 在线等。超级急啊啊啊啊啊
lsw0071年前1
-
inoshigacho 共回答了13个问题
|采纳率92.3%完全一致的
纯数学推导
统计专业研究生工作室为您服务1年前查看全部
- 为了考察两个变量x和y之间的线性相关性,甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方法,求得回归直线
为了考察两个变量x和y之间的线性相关性,甲、乙两位同学各自独立地做10次和15次试验,并且利用线性回归方法,求得回归直线分别为l1和l2.已知两个人在试验中发现对变量x的观测数据的平均数都为s,对变量y的观测数据的平均数都为t,则下列说法正确的是( )
A.l1和l2必重合
B.l1和l2必关于点(s,t)对称
C.l1和l2相交,但交点不一定是(s,t)
D.l1和l2相交旁观者飘过1年前1 -
shen14225 共回答了17个问题
|采纳率94.1%解题思路:由题意知,两个人在试验中发现对变量x的观测数据的平均值都是s,对变量y的观测数据的平均值都是t,所以两组数据的样本中心点是(s,t),回归直线经过样本的中心点,得到直线l1和l2都过(s,t).∵两组数据变量x的观测值的平均值都是s,
对变量y的观测值的平均值都是t,
∴两组数据的样本中心点都是(s,t)
∵数据的样本中心点一定在线性回归直线上,
∴回归直线t1和t2都过点(s,t)
∴两条直线有公共点(s,t)
故选D.点评:
本题考点: 回归分析.
考点点评: 本题考查回归分析,考查线性回归直线过样本中心点,在一组具有相关关系的变量的数据间,这样的直线可以画出许多条,而其中的一条能最好地反映x与Y之间的关系,这条直线过样本中心点.1年前查看全部
- 线性回归中的 F 定义 大小说明什么?
ninna猫1年前1
-
lyn_19871015 共回答了19个问题
|采纳率84.2%F=[SSR-(SSR1+SSR2)]/(SSR1+SSR2)
F值越大,说明回归方程线性关系越强1年前查看全部
大家在问
- 1两根木条,一根60cm,另一根100cm,将它们的一端重合,放在同一条直线上,此时两根木条的中点距离是多少?
- 2英语翻译100个单词左右.1.鸟巢体育馆 2.水立方体育馆
- 3英语翻译13981 Industry AveBecker,MN 55308一个美国地址,不知道那个Becker,MN 是
- 4Lake Ponkapog什么意思?
- 5关于进制转换,原码补码反码等的转换
- 6任意画出四个点(其中任意,三点不在同一条直线上),经过每点用直尺画条直线,一共可以画几条?试画出来
- 7英文单词的过去式,怎么读?加了d 或ed后怎么读?有什麽规律?2、e+d liked wasted 怎么读?
- 8完全相同的两个容器内分别装初温相同、质量相等的酒精和水(有关性质如下表),若吸收相等的热量后,则容器中( ) 物质密度
- 9一块草坪的喷灌设计,如果喷头射程是2.5米,管径应该是多少啊?
- 10水浒传41—50回主要内容介绍(200字)
- 11如图所示,质量分别为m1和m2的两个小球A、B带有等量异种电荷,通过绝缘轻弹簧相连接,置于绝缘光滑的水平面上.当突然加一
- 121.一个物体的俯视图是圆,试说出该物体的可能的形状
- 13帮我检查英语作文【1】 TomorrowTomorrow,i will get up at 7:00.Then i wi
- 14按照如图所示的实物电路,在虚线方框内画出对应的电路图.
- 15求证 等边三角形内任意一点到三遍的距离之和等于该三角形的高