SPSS数据,请求解答多元方差分析
 x63015982022-10-04 11:39:541条回答
x63015982022-10-04 11:39:541条回答
SPSS数据,请求解答多元方差分析
请帮我解释一下这个表格
多元方差分析

请帮我解释一下这个表格
多元方差分析
已提交,审核后显示!提交回复
共1条回复
 aliang1970 共回答了18个问题
aliang1970 共回答了18个问题 |采纳率83.3%- 第一个表 主体因子 是对数据的描述,没有大的意义,只是看一下你需要检验的变量的基本情况
第二个表和第三个表 是关键的
第二个表多变量检验 是用来比较主因子是否显著的,从表中可以看出,性别变量在你的因变量中存在显著的差异.至于第二个表中有四行的检验,是统计学中的不同的检验方法,可以看出,无论使用哪种检验,都说明性别变量在因变量上存在显著差异,但是到底在哪些因变量上存在显著的差异,则需要用到第三个表.
第三个表 是详细检验性别在哪些因变量上存在显著的差异.我们只需要看性别那一栏就可以了,至于截距、校正模型、误差这些,说句实话,在应用中并没有什么大的意义.
因此从表三可以看出 性别在情绪稳定性和 人格责任性上存在显著的差异
看是否显著的 关键是sig的值 是否小于0.05,如果小于0.05则说明差异显著,如果大于0.05则不显著 - 1年前
相关推荐
- 关于 NMR 数据 读法 基础知识
关于 NMR 数据 读法 基础知识
做到这么一道题 分子式 C5H10O(这是10和氧O)
1H NMR(σ)结果
1.07(triplet,6H)
2.43(quartet,4H)
请问这个6H和4H
不好意思我没分了王华民1年前1 -
清狂浪子 共回答了25个问题
|采纳率92%波锋面积值
6H就是有6个H处於相同的化学位移
6H三重峰 表示应该是两个CH3 连著CH2 被裂成三重
4H四重峰 旁边应该有CH3
这是个对称酮类化合物
CH3CH2C=OCH2CH31年前查看全部
- 数据流量单位m.mb.
mininghjy1年前1
-
lovetoswim 共回答了14个问题
|采纳率100%一个英文字母=1Byte,一个汉字=2Byte .
1TB=1024GB,1GB=1024MB,1MB=1024KB,1KB=1024B,1KB=1024Byte1年前查看全部
- oracle数据怎么分组排序提取?
oracle数据怎么分组排序提取?
比如有很多坐标(1,2)(3,4)(2,3)(1,2)(3,5)(2,6)(3,1)在数据表中是以(x,y)的形式存储的,要让他分组成:(1,2)(1,2);(2,3)(2,6);(3,4)(3,5)(3,1)这三组,并一次从里面提取重新分组为:(1,2)(2,3)(3,4);(1,2)(2,6);(3,5);(3,1).这样一个过程怎么实现啊?
请求大神解决,谢谢!
表结构就是
x y
1 2
3 4
2 3
1 2
3 5
2 6
3 1
需要的结果是这样:
x y
1 2
2 3
3 4
x y
1 2
2 6
3 5
x y
3 1注定ee1年前1 -
妖妖妖妖妖 共回答了18个问题
|采纳率88.9%select a.(坐标),b.(坐标) from 表名 a,表名 b
其实就是一个笛卡儿积1年前查看全部
- 跪求高手分析正交设计助手数据结果
跪求高手分析正交设计助手数据结果
我在做毕业论文实验,是研究鲜切菠萝护色的.以下的实验结果是测定鲜切菠萝经不同的护色剂处理后,用测色仪测得的L值在一定时间后的减少值.我用正交设计助手做一个四因素三水品的正交实验找出最好的组合,以下是实验结果.(实验结果数值变化越少,表明护色效果越好)
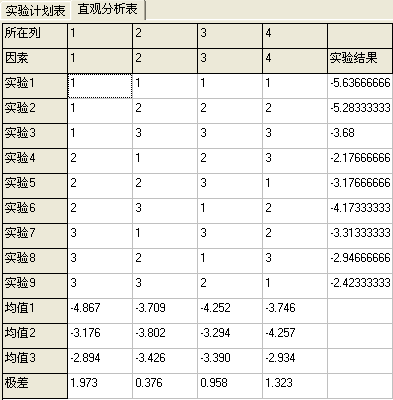
其中因素1.2.3.4分别代表氯化钠,EDTA二钠,异抗坏血酸钠和草酸.
请问根据上面的表格,能否看出最佳的组合?另外,麻烦帮忙看一下方差分析的结果,里面有几项是在一定水平上具有显著性,但我不会看,
另外,下面是有关方差分析的图片,求大神告诉我那个显著性差异是表示什么和什么有显著性差异?
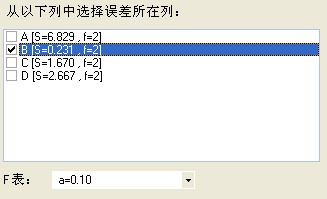
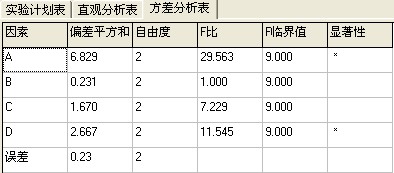
以上是单选一列时,有两个有显著性差异.但是...


选两列的话又是表示什么意思呢?nixy1年前1 -
双月孤鸿 共回答了16个问题
|采纳率93.8%首先你水平数叫1,2,3,因素也用容易混淆,改一下,因素用字母,A(氯化钠),B(EDTA二钠),C(异抗坏血酸钠)和D(草酸)
Rj为第j列因素的极差,它越大说明对实验影响越大,所以按照它的大小判断因素的主次顺序.A(氯化钠)D(草酸)C(异抗坏血酸钠)B(EDTA二钠)
Kjm第j列因素M水平所对应的试验指标和,Kjm的平均值大小可以判断第j列因素优水平和优组合.
因为你的上述数据表中的均值1-3,是不是A-D因素1-3水平所对应的试验均值,如果是,那么最优化组合明显是A3B3C2D3.
如果不是,那需要你计算一下每个因素时1-3水平所对应的试验均值,大的为最优水平.另外你这个正交试验是没有考虑各个因素之间的交互作用的.
你的补充回答:
方差分析又称“变异数分析”,用于两个及两个以上样本均数差别的显著性检验. 由于各种因素的影响,研究所得的数据波动的原因可分成两类,一是随机误差,另一是研究中施加的因素对结果的影响.
怎么判别呢?统计学家想出来几个办法,F检验法,t 检验等
F检验法是英国统计学家Fisher提出的,主要通过比较几组数据的方差 S^2,以确定他们的精密度是否有显著性差异.至于两组数据之间是否存在系统误差,则在进行F检验并确定它们的精密度没有显著性差异之后,再进行t 检验. 样本标准偏差的平方,即(“^2”是表示平方):
S^2=∑(X-X平均)^2/(n-1)
两组数据就能得到两个S^2值,S大^2和S小^2
F=S大^2/S小^2
由表中f大和f小(f为自由度n-1),查得F表(按照置信度90%,95%,99%三种情况,一般用95%置信度),
然后计算的F值与查表得到的F表值比较,如果
F < F表 表明两组数据没有显著差异;
F ≥ F表 表明两组数据存在显著差异
说明A、D两因素造成的差异不是误差造成的,很显著呀.
选两列的时候发现只有A因素是显著的,可能是这列数据的误差比较大或者因素间有交互作用造成D因素不显著.1年前查看全部
- 怎样通过实验数据判定是否恰好完全反应?
怎样通过实验数据判定是否恰好完全反应?
RT,比如有一道题:
某兴趣小组分别用100g稀硫酸与不同质量的锌粒(含杂质且杂质不与稀硫酸反应)反应,三次试验数据见下表
试验次数 1 2 3
加入锌粒的质量/g 4 8 12
充分反应后剩余物质的总质量/g 103.9 107.8 111.8
问第几次实验锌粒与稀硫酸恰好完全反应?
我们老师曾补充过一种通过数据推算的方法,我忘记了,暮禽相与还1年前1 -
cgcgcgcg2004 共回答了12个问题
|采纳率91.7%我们老师也曾经讲过此类题的解法,就是算各次总质量的差,然后进行比较.
对于本题,硫酸与锌反应生成硫酸锌与氢气,第一次剩余物质质量为103.91年前查看全部
- matlab 导入数据出错Data=load('capm.dat');A=data(:,1);B=data(:,2);C
matlab 导入数据出错
Data=load('capm.dat');
A=data(:,1);
B=data(:,2);
C=data(:,3);
D=data(:,4);
执行结果是 Error using ==> load
Unable to read file capm.dat:No such file or directory.
capm.dat文件里面是这样一个矩阵
-4.59 0.87 -6.84 -6.99 0.33 1
2.62 3.46 2.78 0.99 0.29 0
-1.67 -2.28 -0.48 -1.46 0.35 0
0.86 2.41 -2.02 -1.7 0.19 0
7.34 6.33 3.69 3.08 0.27 0
4.99 -1.26 2.05 2.09 0.24 0
-1.52 -5.09 -3.79 -2.23 0.13 0
3.96 4.38 -1.08 2.85 0.17 0
-3.98 -4.23 -4.71 -6 0.16 0
0.99 1.17 -1.44 -0.7 0.22 0
9.22 10.58 6.53 4.72 0.13 0
4.12 6.79 3.42 4.68 0.16 0
4.75 0.26 6.08 6.23 0.19 1阿完1年前1 -
赤扬 共回答了15个问题
|采纳率93.3%文件的路径找不到
试试在文件名前加上文件的路径
Unable to read file capm.dat:No such file or directory.
是说文件找不到1年前查看全部
- 解释下列概念 模拟数据 数字数据 模拟信号 数字信号 模拟传输 数字传输
解释下列概念 模拟数据 数字数据 模拟信号 数字信号 模拟传输 数字传输
解释下列概念:模拟数据、数字数据;模拟信号、数字信号;模拟传输、数字传输.abc123_456def1年前1 -
lllttthhh 共回答了13个问题
|采纳率100%(1)抗干扰能力强、无噪声积累.在模拟通信中,为了提高信噪比,需要在信号传输过程中及时对衰减的传输信号进行放大,信号在传输过程中不可避免地叠加上的噪声也被同时放大.随着传输距离的增加,噪声累积越来越多,以致使传输质量严重恶化.
对于数字通信,由于数字信号的幅值为有限个离散值(通常取两个幅值),在传输过程中虽然也受到噪声的干扰,但当信噪比恶化到一定程度时,即在适当的距离采用判决再生的方法,再生成没有噪声干扰的和原发送端一样的数字信号,所以可实现长距离高质量的传输.1年前查看全部
- 根据下面实验数据求解拟合曲线 P(x)=a+bx+cx^2
根据下面实验数据求解拟合曲线 P(x)=a+bx+cx^2
x=[1,2,3,4,6,7,8]
y=[2,3,6,7,5,3,2]
用matlab求,我对matlab知之甚少,bobylife1年前0 -
共回答了个问题
|采纳率
- ysz电机铭牌数据 功率15/15/4.
愿为你错1年前1
-
haoyunqi 共回答了20个问题
|采纳率100%前面两个应该是星型和三角型接法的功率,后面看看是不是改变了极对数或者说转速以后的功率.这个你要配合前面的看.1年前查看全部
- spss问卷调查数据分析!成绩 X1 X23 21 125 25 294 21 184 17 143 15 164 13
spss问卷调查数据分析!
成绩 X1 X2
3 21 12
5 25 29
4 21 18
4 17 14
3 15 16
4 13 17
2 13 14
3 21 17
3 20 15
2 7 6
3 17 14
2 12 14
3 22 22
2 13 13
3 17 13
4 13 20
3 13 14
4 16 20
5 25 21
1 13 14
2 17 14
3 16 17
4 22 19
4 14 16
4 30 28
4 28 27
2 7 10
4 30 30
4 22 22
5 24 24
4 20 18
3 16 20
2 18 17
3 15 15
3 16 17
5 21 19
3 12 14
4 22 17
5 21 23
4 19 21
3 21 18
2 7 8
4 16 15
3 7 10
2 10 12
4 13 15
4 19 19
3 16 14
5 17 16
4 21 23
3 15 16
1 14 9
4 18 18
3 15 12 ,
我把成绩分成1,2,3,4,5档次了,现在怎么用X1,X2和成绩的关系?散点图不方便啊,没办法用什么方程拟合了,
一般问卷调查分析出了得出回归方程,是不是要显著性检验?残差什么的?哎,老师没教过,这个都是自学的,悲催的,蜀中听雨1年前1 -
merry_cong 共回答了14个问题
|采纳率85.7%有序多分类的因变量,需要使用logistic回归的,方法是这个,但详细操作复杂,可以先找一下这一方法的spss教程 边做边学就可以了,关键是最后的解释1年前查看全部
- 遥感数据特征
巴蜀之子1年前1
-
ggcai 共回答了16个问题
|采纳率75%感数据的特征
x05 1 、空间分辨率:图像上能识别的最小地面距离或最小目标的大小.分辨率的表示:⑴瞬时现场:传感器探测元件的观测视野; ⑵像元:用像元所对应的地面范围的大小; ⑶线对数:影响的最小单元,用 1mm 间隔内包含的线对数 .
x052 、光谱分辨率 :传感器在接受目标辐射的光谱时能分辨的最小波长间隔.高光谱分辨率遥感是在电磁波谱的可见光、近红外、中红外和热红外波段范围内,获取许多非常窄的光谱连续 的影响数据技术.1年前查看全部
- 已知数据0,1,4,2,5,4,6,2,
已知数据0,1,4,2,5,4,6,2,
那么这组数据的平均数是——中位数是——截尾平均数是——方差是——标准差是——yongyuan431年前3 -
实践红 共回答了22个问题
|采纳率81.8%平均数: (0+1+4+2+5+4+6+2)/8=3
中位数: 排序 0,1,2,2,4,4,5,6 取中间两数求平均 (2+4)/2=3
截尾平均数: 去掉一个最大值和一个最小值,然后求平均 (1+4+2+5+4+2)/6=3
方差: [ (0-3)^2+(1-3)^2+(4-3)^2+(2-3)^2+(5-3)^2+(4-3)^2+(6-3)^2+(2-3)^2]/8=15/4
标准差: 方差的算术平方根√(15/4)=√15/21年前查看全部
- 数据结构L->next=p,q=p,s=q
数据结构L->next=p,q=p,s=q
q,s,p是什么关系,L->next==?vngf1年前1 -
825731 共回答了15个问题
|采纳率80%p==q,p==s,q==s,L->next == p1年前查看全部
- origin拟合对数曲线,如何理解这些数据?
origin拟合对数曲线,如何理解这些数据?
Equation y = ln(x-A)
Adj.R-Square 0
Value Standard Error
C1 A 8.59278E176 --烤白薯与地瓜1年前1 -
天马行空0088 共回答了14个问题
|采纳率92.9%拟合方程是:y = ln(x-A)
校正的决定系数r2是:0
标准误差:
C1 A 8.59278E1761年前查看全部
- INDIRECT函数问题ABA B1 数据 数据2 B2 1.3333 B3 454 George 10 =INDIRE
INDIRECT函数问题
AB
A B
1 数据 数据
2 B2 1.333
3 B3 45
4 George 10 =INDIRECT($A$4) 显示为错花舞残梦love仔1年前1 -
黄亚玲 共回答了14个问题
|采纳率100%indirect($A$4)---如$A$4栏结果是文本地址,如B4,则正确,结果为10;如为其它非地址文本,则错误
你的=INDIRECT($A$4)中,$A$4的结果是George,非文本地址1年前查看全部
- 地球环境污染数据
kkwsclb1年前1
-
电光火石间 共回答了15个问题
|采纳率86.7%地球一天的污染帐
--------------------------------------------------------------------------------
2006-07-12
地球上城市居民约有70%(15亿人)呼吸受污染的空气,每天至少有800人因此过早死 亡.每天有1.5万人死于饮用污染的水,其中大部分是儿童.工业、各种喷雾罐、冰箱、空 调机等每天把1500多吨氯氟烃排入大气层,它们是造成臭氧层空洞的罪魁祸首.每天进入 大气层的二氧化碳为5600万吨,“温室效应”与此有关.
每天有5.5万公顷森林被毁,161 平方公里土地荒漠化.每天有14万辆新汽车驶上公路,各国400多座核电站产生26吨核废料,还有1.2万桶石油泻入海洋.1年前查看全部
- 数学数据离散程度
数学数据离散程度
 viviv12121年前1
viviv12121年前1 -
luerluer 共回答了18个问题
|采纳率94.4%(1)不正确.乙班平均成绩高于甲班,因为中位数(即平均数)甲班低于乙班.(2)正确.方差大证明统计数据离差大,也就是甲斑学生成绩(跳绳次数)波动比乙斑成绩波动大;(3)正确.方差大、中位数低均说明了这点.1年前查看全部
- Here is a statistic(数据) that will surprise you.More young pe
Here is a statistic(数据) that will surprise you.More young people are killed each year by slee...
Here is a statistic(数据) that will surprise you.More young people are killed each year by sleepy drivers than by drunk drivers.This proves one thing.Getting enough sleep can be a big problem.How are we dealing with the problem?Sleep clinics are popping up all over the United States.They are always working to find out more about sleep.Driving when tired can be very dangerous.During the daytime,over half of drivers report feeling sleepy at some point.At night,over 80 percent of drivers sometimes get drowsy.And here is the most frightening of all.Almost one-quarter of all drivers have fallen asleep at the wheel.
What is going on here?One thing is that people are not getting enough sleep.One person out of three gets by on less than six hours a night._______________________.Others fall asleep easily,but then wake up time after time.Few people get enough of the deep sleep they need to feel really rested.
Here are some facts to remember.Believe it or not,people need seven to nine hours of nighttime sleep to remain healthy.During that sleep,a person's immune system is built up.This helps fight off diseases and infections.And taking a nap in the daytime does not really help.It will make a person feel “““refresh”””ed.But it cannot make up for the lack of nighttime sleep.
What if you are a person with real sleeping problems?What if you have tried all the home remedies like hot milk?You might consider going to a sleep clinic.Many such clinics look for volunteers.They will study your sleep problems,and you will not have to pay anything.
(1)what is the best title of the passage(no more than 5 words)
(2)complete the following statement with proper words(no more than 4 words) if you have sleep clinic where yov could get help ————
(3)fill inthe blank (para.3) with proper wordr or phrases (no more than 10 words)
(4)why do people need seven to nine hours of nighttime sleep(no more than 10 words)
(5)what does the word “it”(linef,para.4)probably refer to (no more than 6 words)toxbeckham1年前4 -
大吊炮 共回答了32个问题
|采纳率90.6%1.Sleep Problems.
2.from volunteers.
3.Some fall asleep difficultily.
4.Because the established immune system avoid diseases and infections then.1年前查看全部
- 已知数据25,21,23,27,29,24,22,26,27,26,25,26,25,28,30,28,29,26,24
已知数据25,21,23,27,29,24,22,26,27,26,25,26,25,28,30,28,29,26,24,25,在画频数分布直方图时,
如果组距为2,那么应该分成( )组,24.26.5这一组的频数为( ),频率是( )不上线221年前2 -
junefaye 共回答了23个问题
|采纳率87%如果组距为2,那么应该分成( 5 )组,24.26.5这一组的频数为(8 ),频率是( 0.4 )1年前查看全部
- 地球数据.
61264281年前1
-
hongshao2 共回答了17个问题
|采纳率100%轨道长半径(天文距离单位) 1.000 轨道长半径(百万公里) 149.6 公转的恒星周期(日) 365.26 公转的会合周期(日) 无 轨道偏心率 0.0167 轨道倾角(度) 0.0 升交点黄经(度) 0.0 近日点黄经(度) 102.3 平均轨道速度(公里) 29.79 赤道半径(公里) 6371 (此数据为最新数据,此前数据为6,378) 极半径(公里)6350 (此数据为最新数据,此前数据为6,357) 地球周长(公里)40030 扁率 0.0034 质量(地球质量=1) 1.000 密度(克/立方厘米) 5.52 赤道引力(地球=1) 1.00 逃逸速度(公里/秒) 11.2 自转周期(日) 0.9973 黄赤交角(度) 23.44 反照率 0.30 最大亮度 - 卫星(已确认的)1年前查看全部
- 求助mathematic离散数据{d,y}作图问题:For[i=1,i
求助mathematic离散数据{d,y}作图问题:For[i=1,i
For循环中可以算出10对d和y的值,怎样用离散序列画出来水鱼情1年前1 -
ncszw 共回答了15个问题
|采纳率93.3%当然要在循环里面画了,如果在外面,只画出结果图.1年前查看全部
- 数据收集过程填空明确调查问题,确定调查( ),选择调查( ),( )调查,记录( )得出( )
朱利叶斯欧文1年前1
-
蝶儿落 共回答了21个问题
|采纳率71.4%范围,对象,认真,数据,结论1年前查看全部
- excel 2010 数据统计分析
excel 2010 数据统计分析
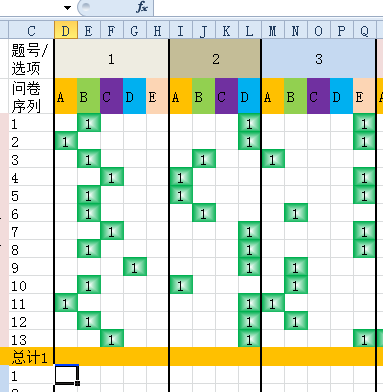 如图我想在总计1那一行统计一下每一列所标注的个数所占行数的百分比,即分母是13,分子是各列标着1的格数. fzhawl1年前1
如图我想在总计1那一行统计一下每一列所标注的个数所占行数的百分比,即分母是13,分子是各列标着1的格数. fzhawl1年前1 -
57073374 共回答了12个问题
|采纳率91.7%在D列和“总计1交叉的单元格(假定在D16)写公式:
=COUNTIF(D3:D15,">0")/13
然后将D16向右边拉/填充或拷贝粘贴到邮编的范围……
最后选定D16到后面的区域/单元格,设置其为 百分比样式 即可.1年前查看全部
- 数据结构题目,(1)INDEX('DATASTRUCTURE','STR')=__
数据结构题目,(1)INDEX('DATASTRUCTURE','STR')=__
(1)INDEX('DATASTRUCTURE','STR')=___?零日记1年前1 -
lalaxx 共回答了18个问题
|采纳率88.9%INDEX('DATASTRUCTURE','STR')= 51年前查看全部
- 数据包括文字,符号,声音,图像?
gongyefeiye1年前1
-
冰cappuccino 共回答了22个问题
|采纳率90.9%包括1年前查看全部
- 怎样处理原子吸收数据
vs101年前1
-
凤凰磐涅 共回答了16个问题
|采纳率75%一般的原子吸收软件,都具备直接处理数据的能力
多数软件在输入相应的浓度和称样量后就会自动计算结果
建议您可以到行业内专业的网站进行交流学习!
分析测试百科网乐意为你解答实验中碰到的各种问题,基本上问题都能得到解答,有问题可去那提问,百度上搜下就有.1年前查看全部
- 请问 IF(C11="Y",VLOOKUP(D11,数据!AB6:数据!AD72,3),0.17)
请问 IF(C11="Y",VLOOKUP(D11,数据!AB6:数据!AD72,3),0.17)
如题~lhs10191年前1 -
robby兔 共回答了15个问题
|采纳率93.3%如果C11="Y",返回VLOOKUP(D11,数据!AB6:数据!AD72,3),否则返回0.17
再解释VLOOKUP(D11,数据!AB6:数据!AD72,3):
在取名“数据”的工作表的AB6:AB72中查找D11,AB6:AB72必须是以升序排列的.如能精确找到,假定AB10=D11,则返回AD10;如不能精确找到,假定AB12是AB6:AB72中小于D11的最大值,则返回AD12.1年前查看全部
- stata 数据 save as scarlars,save as global
海脚uu1年前1
-
娃哈哈fl23 共回答了15个问题
|采纳率86.7%都是宏
前者只能是numbers,而global更宽泛,是全局的
建议你学习stata program1年前查看全部
- 地震影响数据根据哪些参数确定
caiian1年前1
-
lavender1207 共回答了6个问题
|采纳率100%不知道你所谓的影响数据是指哪方面,我就普通的理解来说,看一个地震影响的大小,首先看震级,震级越大,一般影响也越大;然后看震源深度,震源深度越浅,对地面的破坏就越大,地面的破坏情况称为地震烈度,汶川地震中心烈度约为11~12级,即地表破坏相当严重;当然,不同类型的地震破坏性也不同,一般来说张性正断层引起的地震多会对底面造成塌陷,压型逆断层发生的地震多会造成底面的抬起和隆升,走滑性的断裂多会造成底面的错动,当然同一个地震也可能包含上述情况中的多种.
评价地震的参数还有b值、P值和Q值等.
总之地震的情况是多种多样相当复杂的,所以是很难量化的,现在多采用地震释放的能量的方法来量化.1年前查看全部
- excle 公式奇数偶数公式数据 结果 2 1 3 1 1 5 5 7 7 1 1 14 3 17 3 3 2 2 2
excle 公式奇数偶数公式
数据
结果
2
1
3
1
1
5
5
7
7
1
1
14
3
17
3
3
2
2
2
1
7
2
4
9
15
第一列,如果是奇数,直接写在第二列.第一列如果是偶数就加在下面一行的奇数上,下面一行还是偶数就一直往下一行加,加到出现奇数为止.数据是1~99的随机数
上面排版有问题,看下面
数据 结果
2
1 3
1 1
5 5
7 7
1 1
14
3 17
3 3
2
2
2
1 7
2
4
9 15dd咖啡1年前0 -
共回答了个问题
|采纳率
- SQL server QQ数据查询 部分题目 求解
SQL server QQ数据查询 部分题目 求解

(1)查询QQ号码为54789625的用户的好友中每个省份的总人数,并且总人数按由大到小
(2)查询至少有150天未登录QQ账号的用户信息,包括QQ号码,最后一次登录时间、等级、昵称、年龄,并按时间的降序排列。
(3) 查询好友超过20个的用户号码及其好友总数。
(4)查询QQ号为88662753的用户的所有 好友 的信息
ljjixi1年前1 -
wilsonn321 共回答了16个问题
|采纳率93.8%--***** 查询至少有150天未登陆QQ账号的用户信息,包括QQ号码,最好一次登陆时间,等级,昵称,年龄,并按时间进行排序--
select * from BaseInfo s
inner join QQUser m on s.QQID=m.QQID
where DATEDIFF (DD ,m.lastLogTime,GETDATE())>=150
order by LastLogTime DESC
--查询QQ号为54789625的用户的好友信息每个省份的人数,并且按总人数从大到小--
select COUNT(*),m.Province from Relation s inner join BaseInfo m on s.RelationQQID=m.QQID
where(s.QQID=54789625) group by m.Province
select COUNT(m.Province),m.Province from Relation s,BaseInfo m where(s.QQID=54789625 and s.RelationStatus=0 and s.RelationQQID=m.QQID)
group by m.Province order by COUNT(m.Province) DESC1年前查看全部
- 近年地球平均气温准确数据
xuganghnll1年前1
-
勇敢的情 共回答了17个问题
|采纳率82.4%答:地球上最热的地方在撒哈拉大沙漠,那里的实测最高气温达到57.9°C.而在最冷的两极地区,曾经测量得到89.2°C的最低温.地球的平均气温约为11.2°C.但近年来,由于温室效应的影响,年平均气温政逐年升高. 地球平均气温上升了0.6度(全球平均气温最底线为2度).地球气温在未来100年里会上升多少,一般的估计是上升2.5至10.4摄氏度,造成这一差距的原因是看人类能在多大程度上控制温室气体排放.1年前查看全部
- python 生成随机数据 验证算法
python 生成随机数据 验证算法
非程序员,只是想用Python随机生成数据以验证一个简单算法的可行性,算法中有p和t两个变量(比如:s=p*t),试着用for语句,但是只想到了嵌套,于是在p和t各取十个值就排列组合出了一百个结果【比如for p in (2,3)嵌套for t in (3,4),在前述方程中就有了2*3,2*4,3*3,3*4这四个答案,但是我不想要这么多相同数】,想要p和t完全随机组合的,这样较少的结果就可以获得足够的参考数.但是编程能力还不够,不知道怎么实现,求程序员大大的帮助!QQ的nn1年前1 -
逆行虫虫 共回答了15个问题
|采纳率80%这个简单.假设你要N个p t组合,p 和 t的范围是 [pmin,pmax],[tmin,tmax].:
import random
N = 100
pmin = 0
pmax = 1000
tmin = 0
tmax = 100
r = random.Random()
r.seed() #刷新随即数种子
for i in range(N)
p = r.randint(pmin,pmax)
t = r.randint(rmin,rmax)
s = p*t
print p,t,s
可以把N pmin pmax tmin tmax,设置为你需要的参数.1年前查看全部
- 数据结构课程设计 关于数制转换问题
数据结构课程设计 关于数制转换问题
任意给定一个M进制的数x ,请实现如下要求
1)求出此数x的10进制值(用MD表示)
2)实现对x向任意的一个非M进制的数的转换。
3)至少用两种或两种以上的方法实现上述要求(用栈解决,用数组解决,其它方法解决)。
雨过留痕1311年前1 -
光在 共回答了16个问题
|采纳率87.5%//给你一个十进制转换为八进制的,其他类似的改一下就是了
#include"stdio.h"
#include"malloc.h"
#include"util.h"
#define STACK_INIT_SIZE 100
#define STACKINCREMENT 10
#define OVERFLOW -2
#define OK 1
#define TRUE 1
#define FALSE 0
#define ERROR 0
typedef int SElemType;
typedef int Status;
typedef struct{
SElemType *base;
SElemType *top;
int stacksize;
}SqStack;
Status InitStack(SqStack & S)//栈的初始化
{
S.base = (SElemType *)malloc(STACK_INIT_SIZE * sizeof(SElemType));
if(!S.base)
exit(OVERFLOW);
S.top = S.base;
S.stacksize = 100;
return OK;
}
/*Status GetTop(SqStack S,SElemType &e)
{
if(S.top==S.base)
return ERROR;
e = *(S.top-1);
printf("获得栈顶元素:");
printf("%3dn",e);
return OK;
}*/
Status Push(SqStack &S,SElemType e)
{
if(S.top-S.base>=S.stacksize)
{
S.base = (SElemType *)realloc(S.base,(S.stacksize+STACKINCREMENT)*sizeof(SElemType));
if(!S.base)
exit(OVERFLOW);
S.top = S.base + S.stacksize;
S.stacksize+=STACKINCREMENT;
}
*S.top++=e;
return OK;
}
Status Pop(SqStack &S,SElemType &e)
{
//若栈不为空,则删除s的栈顶元素,用e返回其值
if(S.top==S.base)
return ERROR;
--S.top;
e = *S.top;
return OK;
}
bool StackEmpty(SqStack &S)
{
if(S.top=S.base)
return TRUE;
else
return FALSE;
}
void main()
{
SqStack S;
int N,t;
printf("请输入要转换的十进制数:");
scanf("%d",&N);
InitStack(S);
while(N)
{
Push(S,N%8);
N=N/8;
}
printf("转换后的八进制数:");
while(!StackEmpty(S))
{
Pop(S,t);
printf("%2d",t);
}
printf("n");
}1年前查看全部
- c++ 数据结构隧道(Tunel)
c++ 数据结构隧道(Tunel)
现有一条单向单车道隧道,每一辆车从隧道的一端驶入,另一端驶出,不允许超车
该隧道对车辆的高度有一定限制,在任意时刻,管理员希望知道此时隧道中最高车辆的高度是多少 现在请你维护这条隧道的车辆进出记录,并支持查询最高车辆的功能
输入
第一行仅含一个整数,即高度查询和车辆出入操作的总次数n 以下n行,依次这n次操作.各行的格式为以下几种之一:
E x //有一辆高度为x的车进入隧道(x为整数)
D //有一辆车离开隧道
M //查询此时隧道中车辆的最大高度
输出
若D和M操作共计m次,则输出m行 对于每次D操作,输出离开隧道车辆的高度 对于每次M操作,输出所查询到的最大高度
输入
第一行仅含一个整数,即高度查询和车辆出入操作的总次数n
以下n行,依次这n次操作.各行的格式为以下几种之一:
1. E xx09x09//有一辆高度为x的车进入隧道(x为整数)
2. Dx09x09//有一辆车离开隧道
3. Mx09x09//查询此时隧道中车辆的最大高度
输出
若D和M操作共计m次,则输出m行
对于每次D操作,输出离开隧道车辆的高度
对于每次M操作,输出所查询到的最大高度
输入样例
9
E 5
E 6
M
E 2
M
D
M
D
M
输出样例
6
6
5
6
6
2
ptall1年前1 -
喜灵儿 共回答了21个问题
|采纳率95.2%#include#include using namespace std;class Tunnel{x09queue cars;x09deque Mcars;x09x09public:x09x09... 1年前查看全部
- EXCEL2010 数据自动排序,
EXCEL2010 数据自动排序,
假如我有A 和B 两列,
怎样能让B列根据A列的数字排序,并且A列的数据改变,B列也能自动生成1,2,3,4的序列,如下:
A B
300 3
500 1
200 4
400 2
A列中数量最大500的对应B列中的1.紫色常青藤1年前1 -
天凡期 共回答了24个问题
|采纳率100%在B1中输入公式:
=RANK(A1,A:A)
下拉填充公式.1年前查看全部
- 已知数据10,8,6,10,8,13,11,10,12,7,9,8,12,9,11,12,9,10,11,10,那么频数
已知数据10,8,6,10,8,13,11,10,12,7,9,8,12,9,11,12,9,10,11,10,那么频数为4的组是
A.5.5-7.5
B.7.5-9.5
C.9.5-11.5
D.11.5-13.5honghua821年前1 -
吴热里件细 共回答了20个问题
|采纳率90%D,12三次,13一次1年前查看全部
大家在问
- 1下列说法中错误的是( )A.π的值等于3.14B.π的值是圆周长与直径的比值C.π的值与圆的大小无关D.π是一个无限小
- 2授权委托书中申请执行英语怎么说啊,
- 3求冰川时代4观后感的开头,不能抄百度,快。。。
- 4鸡的输卵管细胞能合成卵清蛋白,红细胞能合成β-珠蛋白,胰岛细胞能合成胰岛素.用编码上述蛋白质的基因分别做探针,对三种细胞
- 5There is ______ my iPad. It isn’t working. A.something with
- 6含有2N(A)个阴离子的CaC2与饱和食盐水反应,在标准状况下能产生约44.8L的乙炔气体.请问是怎么算的?
- 7若不在同一直线上的三点A,B,C到平面的距离相等,且A∉α,则
- 8以 那一次,我真()为题的作文
- 9英语翻译重点是no obligation.
- 10物体的形状与周围磁场是什么关系?比如金字塔的三角形状能引起特殊磁场能量(使食物长保新鲜等)是否属谣言
- 11神采飞扬的解释
- 12我喜欢的一次活动-论语大赛 作文
- 13明明量得一棵大树的树干周长约是3.14m.这棵大树的横截面积是多少?
- 14设集合A={x|-3≤x≤a}且A≠∅,B={y|y=3x+10,x∈A},C={z|z=5-x,x∈A}且B∩C=C,
- 15新学期新计划 作文