TAAT序列都是启动子吗只要含有TAAT序列,这个位置就是启动子吗?还是在其他部位(比如基因内部编码序列)也可以有TAA
 whanmyself2022-10-04 11:39:541条回答
whanmyself2022-10-04 11:39:541条回答只要含有TAAT序列,这个位置就是启动子吗?还是在其他部位(比如基因内部编码序列)也可以有TAAT,但不是启动子.其他的如caat、gc box等都是同样的吗?分不多了,
TATA,写错了抱歉.
已提交,审核后显示!提交回复
共1条回复
 八角箩 共回答了17个问题
八角箩 共回答了17个问题 |采纳率94.1%- 这是个很有意思的问题.
还真的有,XM_007821768.1,有兴趣可以看下
因为TATA box是段很短的序列(TATAATAAT),在长长的基因组DNA序列中找到相似的,太容易了,但是要注意阅读框的位置,TAA是终止密码子.
作为真核生物启动子的元件,必须要在特定的位置 - 1年前
相关推荐
- 数字信号处理 计算长度为N的有限长序列 x(n)=an (0≤n≤N-1)的DFT
海洋之心07691年前0
-
共回答了个问题
|采纳率
- 数字信号处理题目设x【k】是一N点序列x【k】=1(0
沙与海1年前1
-
fanfanxl 共回答了22个问题
|采纳率90.9%最大正值位置为k1=h/2-1和k2=3n/2-1的位置,最大值同为n/2
最小的负值位置k3=n-1处,最小值为-n
这道题你用画图的方法做,你应该学过用图解法解卷积的吧
当两个正部重合和两个负部重合时卷积取最大值
当正部重合到负部时卷积取最小值
很简单的!1年前查看全部
- 已知二叉树的后序遍历序列和中序遍历序列,怎样求其前序遍历序列!
已知二叉树的后序遍历序列和中序遍历序列,怎样求其前序遍历序列!
举个例子,捻月为盟1年前1 -
Maria_wu 共回答了17个问题
|采纳率88.2%首先理解概念:
前序遍历:访问根结点的操作发生在遍历其左右子树之前.
中序遍历:访问根结点的操作发生在遍历其左右子树之中(间).
后序遍历:访问根结点的操作发生在遍历其左右子树之后.
eg:后序遍历为DBCEFGHA,中序遍历为EDCBAHFG,求前序遍历(网上例子)
首先 看后序遍历DBCEFGHA,A为总根节点
然后 寻找中序遍历EDCBAHFG中A位置,则EDCB在A的左枝,HFG在A的右枝;
重复前两步,从后序遍历最后一位找,在中序遍历寻找对应点,得出左右分枝...
最后得到AECDBHGF,再自己验证即可...1年前查看全部
- 用射线照射的方法使某生物基因中的脱氧核苷酸序列发生如下变化:.CTAACG.→...CTGACG.,那么该生物将发生的变
用射线照射的方法使某生物基因中的脱氧核苷酸序列发生如下变化:.CTAACG.→...CTGACG.,那么该生物将发生的变化和结果是?
基因突变,性状没有改变wonderwall_oasis1年前1 -
shuihuo815 共回答了15个问题
|采纳率86.7%因为变了一个碱基,所以是基因突变,但是发生的是同义突变,不影响蛋白质翻译,也就不影响性状
三个可能的阅读框:
CTA=CTG=亮氨酸
TAA=TGA=终止
AAC=GAC=天门冬酰胺1年前查看全部
- 根据氨基酸序列确定碱基序列,遗传信息在这一过程中损失
我是摩羯女1年前3
-
unfairnju 共回答了12个问题
|采纳率75%是提取目的基因时用人工合成法根据氨基酸序列合成目的基因
根据氨基酸序列推测mRNA核苷酸序列→推测基因的核苷酸序列→合成目的基因
真核基因有非编码序列,推测不出来1年前查看全部
- 什么是pair-end 测序?只测一个片段的两端吗,那中间的序列怎么得知?有什么优点?
什么是pair-end 测序?只测一个片段的两端吗,那中间的序列怎么得知?有什么优点?
如题,谢谢大家了.elain19781年前1 -
lemon_tree28 共回答了19个问题
|采纳率94.7%Paired-end方法是指在构建待测DNA文库时在“两端”的接头上都加上测序引物结合位点,在第一轮完成后,去除第一轮测序的模板链,用对读测序模块引导互补链在原位置再生和扩增,以达到第二轮测序所用的模板量
优点:
pair end是直接在DNA两端假设接头进行双向测序,插入片段长度较短1年前查看全部
- 数据结构题,叙述对有环无向图求拓扑排序序列的步骤 (2)写出下图的4个不同的拓扑排序序列麻烦解答,
洛水依痕1年前1
-
游荡天边 共回答了23个问题
|采纳率87%(1)
设对有向无环图G=,求得它的一个拓扑序列为S,
初始化S为空,然后每次从G中选取一个入度为0的点v,将v插入到S的尾部,再在G中删除点v,并删除所有以v为弧尾的边(即由v引出去的边),如此循环,直到图G中的V为空集时结束.
2
1 2 3 4 5 6 7 8
1 3 2 4 5 7 6 8
3 1 4 2 5 6 7 8
3 1 2 5 4 7 8 61年前查看全部
- 碱基序列和DNA序列和基因序列有什么不同
kalin31861年前2
-
玉笛书生philo 共回答了18个问题
|采纳率94.4%碱基序列通常是指核苷酸序列,包括核糖核酸序列和脱氧核糖核酸序列(即DNA序列和RNA序列)
DNA序列就是指DNA链的脱氧核糖核苷酸的排列顺序
基因是指具有遗传效应的DNA片段.并非所有DNA都是基因.所以基因序列就只是指具有遗传效应的DNA序列(即能翻译出蛋白质的DNA序列)1年前查看全部
- 有关PCR技术的引物链的问题PCR技术的引物链的碱基序列是否可以是DNA中间的一部分?
易水89101年前1
-
momo08_20 共回答了26个问题
|采纳率88.5%楼主可以先反问自己两个问题:1.什么是PCR引物.2.PCR技术的引物链的碱基序列为什么不可以是DNA中间的一部分.然后找一条基因用Primer Premier 或Oligo等引物设计软件去验证一下. 对于粘性末端,不知道楼主是否真正的理解了这个概念.粘性末端平末端等都是与酶切、连接相关的概念与PCR反应无关.用楼主的一句话:问问题前请先动动脑子.1年前查看全部
- 任务:到gene bank 查GAPDH基因的mRNA全序列(查人的GAPDH)要求:贴出对应该基因的网址.关于该基因的
任务:到gene bank 查GAPDH基因的mRNA全序列(查人的GAPDH)要求:贴出对应该基因的网址.关于该基因的部分description!提示:gene bank 就是大名鼎鼎的 NCBI.实在不懂,自己google江建新1年前1
-
吴忧二世 共回答了14个问题
|采纳率78.6%1. 第一,先到 http://www.ncbi.nlm.nih.gov/pubmed/
2. 在顶上靠左侧的下拉菜单选中“Nucleotide" , 再在其右侧的空白处填入”Homo sapiens GAPDH“,点”search“
3.在得到的结果中间找到”GAPDH mRNA“的结果,点开.
4. 可以得到NM_002046.3(GADPH)的所有信息了,你也可以直接在搜索的时候输入NM_002046.3,而直接得到,不一定要输入”GAPDH mRNA“1年前查看全部
- 皱粒豌豆的形成:皱粒豌豆的DNA中插入了一段外来DNA序列,使编码?-------?的基因被打乱.
皱粒豌豆的形成:皱粒豌豆的DNA中插入了一段外来DNA序列,使编码?-------?的基因被打乱.
基因对性状的间接控制部分的,hr_zzl9111年前1 -
-刺猬 共回答了17个问题
|采纳率94.1%皱粒豌豆的形成:皱粒豌豆的DNA中插入了一段外来DNA序列,使编码淀粉分支酶的基因被打乱.
淀粉分支酶不能合成,蔗糖不能合成为淀粉,蔗糖含量升高,淀粉含量低的豌豆由于失水而显得皱缩.1年前查看全部
- 对下图所示的森林,将其转化为二叉树,并写出该二叉树的先根序、中根序和后根序历序列.
滚烫雪花1年前1
-
czm1688 共回答了29个问题
|采纳率93.1%A
B H
E C F NULL
NULL F NULL D NULL J
G NULL K NULL
先 EFBCGDAFKJH
中 ABEFCDGHFJK
后 FEGDCBKJFHA1年前查看全部
- 基因组信息对于人类疾病的诊治有重要意义.人类基因组计划至少应测几条染色体的碱基序列?为什么?
兔子西西1年前1
-
rr十周年大涨 共回答了17个问题
|采纳率82.4%常染色体每一对中取一条 性染色体都要 因为要全部的遗传信息 同源染色体带相同遗传物质 所以一半就行了 但性染色体有非同源区段 所以两条都要 生物书第3册有 不清楚问我 或者看书 在基因工程那段 如 人 22条常+两条性染色体1年前查看全部
- 推测相应基因中脱氧核苷酸序列--生产相应蛋白质这个过程为什么需要涉及基因工程?
知风801年前1
-
ana1226 共回答了14个问题
|采纳率85.7%蛋白质的种类很多,特定的基因片段(DNA不同序列组合:关键是碱基对的不同衔接)生成特定的蛋白质.由所需蛋白质逆推出相应的基因序列后,依靠基因工程通过截取DNA上的特殊片段或人工合成,采用序列扩展衔接等操作得到所需要的特定DNA片段,并将其导入到能大量增殖的工程菌中进行基因编码,从而生成相应的蛋白质,整个过程都需要用到基因工程.1年前查看全部
- 用简单插入排序法,对关键字值序列:9,2,20,45,3,18按从小到大的顺序进行排列,试打印出每趟排序的结果.
ming8008241年前1
-
laojizhi 共回答了20个问题
|采纳率100%1.起始状态(9,2,20,45,3,18)
2.第一趟(2,9,20,45,3,18)
3.第二趟(2,9,20,45,3,18)
3.第三趟(2,9,20,45,3,18)
3.第四趟(2,3,9,20,45,18)
3.第五趟(2,3,9,18,20,45)1年前查看全部
- 基因工程中涉及多种工具酶。(1)限制酶是一种能识别特定核苷酸序列并在特定位点切割双链DNA的“基因剪刀”。被限制酶识别的
基因工程中涉及多种工具酶。
(1)限制酶是一种能识别特定核苷酸序列并在特定位点切割双链DNA的“基因剪刀”。被限制酶识别的序列往往正反读顺序相同,断裂的位置交错,但又是围绕着一个轴线(对称轴)对称排列的,如下图甲。PstI和EcoRI都是限制酶。请补全下图乙的互补链,画出对称轴以及切割后的产物。
(2)DNA连接酶是基因操作的“分子缝合针”,其作用是把基于______能力而黏合在一起但存在的切口封闭,进而才可能形成有意义的________。
(3)逆转录酶也常被用于基因工程,其存在于_______(生物)中,催化以______为模板合成DNA的过程。快意蒹葭1年前1 -
znblb 共回答了20个问题
|采纳率90%(1)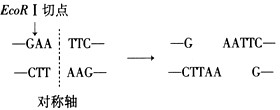
(2)碱基互补配对 重组DNA
(3)(某些)病毒 mRNA1年前查看全部

- 若兔子肌细胞内有a种不同序列的DNA分子,青菜叶肉细胞中都有b种不同序列的DNA分子.当免子摄入大量青菜后,兔子肌细胞的
若兔子肌细胞内有a种不同序列的DNA分子,青菜叶肉细胞中都有b种不同序列的DNA分子.当免子摄入大量青菜后,兔子肌细胞的细胞核内含有不同序列的DNA分子的种类是( )
A. a+b
B. 大于a且小于a+b
C. a
D. 小于adrttyuu31年前4 -
mosonzhang 共回答了14个问题
|采纳率92.9%解题思路:DNA是细胞中的遗传物质,该物质主要存在于细胞核中的染色体上,另外在线粒体和叶绿体中也有少量分布.当免子摄入大量青菜后,青菜中的核酸将被分解为核苷酸被兔子吸收,即青菜的不同序列的DNA分子不会影响兔子细胞内DNA分子的种类.
又由于兔子肌细胞内DNA主要存在于细胞核中,另外在线粒体中也有少量分布,因此兔子肌细胞的细胞核内含有不同序列的DNA分子的种类小于a种.
故选:D.点评:
本题考点: 核酸的种类及主要存在的部位.
考点点评: 本题考查了核酸的分布以及种类等有关知识,要求考生能够明确肌肉细胞中的DNA分布在细胞核和线粒体中;并且动物食物中核酸的种类不会影响动物自身核酸的种类.1年前查看全部
- 从1~n个数中选择n个数(可重复)构成一个递增序列,有多少种选取方式?
从1~n个数中选择n个数(可重复)构成一个递增序列,有多少种选取方式?
从1~n个数中选择n个数(可重复)构成一个递增(不一定严格递增)序列,有多少种选取方式?最好有推导过程,
例如,n=1时有1种;
n=2时有3种:11,12,22
n=3时有10种:111,112,113,122,123,133,222,223,233,333快乐三亚1年前2 -
42643527 共回答了21个问题
|采纳率85.7%该推导需要结合杨辉三角,设杨辉三角第i行,第j列为Aij.
可以知道其通项满足Aij=A(i-1)(j-1)+A(i-1)j.
而该问题组成序列个数为Kn,有Kn=An1+A(n+1)2+.+A(2n-1)n.
杨辉三角第n行的数依次是C(0,n-1),C(1,n-1),C(2,n-1)……C(n-1,n-1).
其中C是组合数.
故有Kn=C(0,n-1)+C(1,n)+C(2,n+1)+.+C(n-1,2n-2).
不好意思了,推导过程太繁杂了,不过结合杨辉三角还是满直观的.1年前查看全部
- java中方用while循环那输出如下数列 1 1 2 3 5 8 13,一直输出20个这样规律的数字的序列.
java中方用while循环那输出如下数列 1 1 2 3 5 8 13,一直输出20个这样规律的数字的序列.
必须是while枕霞旧友1231年前1 -
buy33decd 共回答了14个问题
|采纳率85.7%public class Demo2 {
/**
* @param args
*/
public static void main(String[] args) {
int i =2;
int[] ss = new int[20];
ss[0]=1;
ss[1]=1;
System.out.print(ss[0]+" "+ss[1]+" ");
while(i1年前查看全部
- (2010•南通二模)某DNA分子中含有某限制酶的一个识别序列,用该限制酶切割该DNA分子,可能形成的两个DNA片段是(
(2010•南通二模)某DNA分子中含有某限制酶的一个识别序列,用该限制酶切割该DNA分子,可能形成的两个DNA片段是( )
选项 片段1 片段2 A 

B 

C 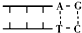
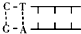
D 
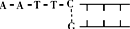
A.A
B.B
C.C
D.DddBLUE1年前1 -
可以想你吗 共回答了23个问题
|采纳率91.3%解题思路:能够识别双链DNA分子的某种特定核苷酸序列,并且使每一条链中特定部位的两个核苷酸之间的磷酸二酯键断裂,形成黏性末端和平末端两种,同种限制酶切割形成的黏性末端相同.A、同一个限制酶切割产生的末端存在相同且互补序列,①中两个黏性末端的碱基序列不相同也不互补,不是同种限制酶切割产生的,A错误;
c、②中两个平末端的碱基序列连接起来后,上面是GGAT,下面是ATCC,碱基序列不同,不是同种限制酶切割产生的,c错误;
C、③中两个平v末端的碱基序列连接起来后,上面是AGCT,下面是TCGA,属于反向对称重复排列的,C正确;
D、④中两个黏性末端的碱基序列是相同的,能进行碱基互补配对形成双链DNA,是由同一种限制酶切割,D正确.
故选:CD.点评:
本题考点: 基因工程的原理及技术.
考点点评: 本题考查限制酶的相关知识,意在考查考生的理解判断能力,属于中档题.1年前查看全部
- 随机变量序列如果具有相同的数学期望和方差 可否断定它们就是同分布的呢?
聚光洒1年前1
-
qoho956 共回答了16个问题
|采纳率93.8%不可以
期望和方差相同的太多了.完全不是一回事
反之,同分布则期望方差相同成立1年前查看全部
- 人类基因组图需要分析____条染色体的_____序列?
glasscup271年前1
-
阳光宝马 共回答了14个问题
|采纳率100%24条,DNA
22对常染色体中各取一条加一对性染色体1年前查看全部
- 基因芯片是将大量特定序列的DNA片段(探针)有序固定在尼龙膜、玻片或硅片上,从而能大量、快速地对DNA分子的碱基序列进行
基因芯片是将大量特定序列的DNA片段(探针)有序固定在尼龙膜、玻片或硅片上,从而能大量、快速地对DNA分子的碱基序列进行测定和定量分析.其原理如图:基因芯片技术中用荧光分子标记的是( )
 A. PCR扩增中的模板DNA
A. PCR扩增中的模板DNA
B. 基因芯片上已知序列的特定DNA
C. DNA聚合酶
D. 样品DNAstylish19811年前1 -
漫天小子 共回答了27个问题
|采纳率88.9%解题思路:基因芯片是将大量特定序列的DNA片段(探针)有序地固定在尼龙膜、玻片或硅片上,从而大量、快速、平行地对DNA分子的碱基序列进行测定和定量分析.其依据的原理是DNA分子杂交技术.基因探针是指用放射性同位素(或荧光分子)标记的含有目的基因DNA片段,一种探针只能检测一种DNA分子.基因芯片是将大量特定序列的DNA片段(探针)有序地固定在尼龙膜、玻片或硅片上,依据DNA分子杂交原理,与待测样品进行碱基互补配对,从而对待测样品进行测定和定量分析.而大量特定序列的DNA片段被称为基因探针,往往是被放射性同位素(或荧光)标记的.
故选:B.点评:
本题考点: 基因工程的原理及技术.
考点点评: 本题考查了基因工程的相关内容,意在考查学生对基因探针的结构和应用的了解.1年前查看全部
- DNA分子-CCGCGG-序列被限制酶切割后随之断裂的氢键有多少个
发仔啦啦1年前1
-
脸被砖拍过 共回答了16个问题
|采纳率93.8%答:DNA分子-CCGCGG-序列被限制酶切割后随之断裂的氢键有6个.
-CCGCGG-序列的切割位置是:—CCGC↓GG—,所以切割后形成的是:
-CCGC GG-
-GG CGCC-
也就是断开两个C与G间的氢键,由于每个C-G间有三个氢键,所以断开的是6个氢键.1年前查看全部
- 某洋底钻心的地层序列如图所示,请根据该序列特征简述区域地质演化过程
向日葵花1年前1
-
超级大狗勇 共回答了16个问题
|采纳率93.8%总的来说这里的地层出现了抬升现象.上白垩统含有石灰岩地层,还处于海相环境,之后逐渐脱离海洋,上新统与渐新统之间有地层缺失(中新统).说明地层抬升之后遭到风化剥蚀,从最上层的第四系地层也可以看出,这时处于风化环境之下.1年前查看全部
- 问一个极其复杂的序列组合概率题,
问一个极其复杂的序列组合概率题,
是这样的 一副扑克牌 抽5张出来,问 其中有3张红(红桃方板) 2张黑(黑桃梅花大小王) 或者 3张黑(黑桃梅花大小王)2张红(红桃方板)这样的概率有多大?或者说 5张出现4红1黑 或5红 或4黑1红或5黑的 概率也行!木兰F1年前3 -
秋枫林21892 共回答了20个问题
|采纳率80%从54张牌中抽5张:C(54,5)
3张红,从红的26张牌中取3张,C(26,3)
2张黑,从28张中取2张,C(28,2)
概率:C(26,3)*C(28,2)/C(54,5)=0.310766
3张黑:C(28,3)
2张红:C(26,2)
概率:C(28,3)*C(26,2)/C(54,5)=0.3366631年前查看全部
- 已知一棵二叉树的中序序列和后序序列,请画出该二叉树 中序序列 DIGJLKBAECHF 后序序列 ILKJGDBEHFC
已知一棵二叉树的中序序列和后序序列,请画出该二叉树 中序序列 DIGJLKBAECHF 后序序列 ILKJGDBEHFCA偶才素呆呆1年前1
-
strawring 共回答了22个问题
|采纳率90.9%先画出二叉树:
前序为:ABDGIJKLCEHF1年前查看全部
- 内部排序 序列的状态是逆序列 使用哪种排序方法比较好
内部排序 序列的状态是逆序列 使用哪种排序方法比较好
某序列是逆序列(比如按大到小排列) 要将它排成正序列(按小到大排列)
使用哪种排序方法比较好(比如直接插入法,冒泡法,快速排列,简单选择排列,堆排列等等,哪一种方法比较好)cexowfnh1年前1 -
whrt 共回答了26个问题
|采纳率84.6%快速排列 堆排列 归并排序nlongn 其它都会达到n^21年前查看全部
- (2013•蓬溪县模拟)观察并完成序列:0、1、3、6、10、______、21、______.
begin9909161年前1
-
斜桥影里 共回答了22个问题
|采纳率95.5%因为,0+(1)=1,
1+(2)=3,
3+(3)=6,
6+(4)=10,
10+(5)=15,
15+(6)=21,
21+(7)=28,
所以,应该填:15;28;
故答案为:15;28.1年前查看全部
- 小鼠BRAF基因V599E和V600E的基因的序列是多少?怎么查?设计PCR引物呢?
小鼠BRAF基因V599E和V600E的基因的序列是多少?怎么查?设计PCR引物呢?
我是一个本科生,想知道小鼠BRAF基因V599E和V600E的基因的序列是多少?怎么查?如何设计它们PCR引物猪猪仔1年前1 -
applejuice666 共回答了20个问题
|采纳率90%你的问题太多 我实在没时间.
但愿能引你一下 好运!1年前查看全部
- 写出下列二叉树的中序遍历序列
_4151年前1
-
夺_oo 共回答了12个问题
|采纳率91.7%中序是左中右,序列为BDCEAFHG
遍历过程请参考:http://zhidao.baidu.com/question/89674628.html1年前查看全部
- 如果一个逆序序列是用单链表表示的话.欲得到这个逆序排列的数据元素序列的正序输出序列的有效方法是什么
如果一个逆序序列是用单链表表示的话.欲得到这个逆序排列的数据元素序列的正序输出序列的有效方法是什么
河工大2010年计算机考研的一道问答题xiaoran_11年前1 -
maqin1981 共回答了16个问题
|采纳率100%单链表倒置(使用头插法就可以轻松实现),然后从头到尾遍历一次,就是正序输出.不需要用到栈.1年前查看全部
- 基因研究最新发现,人与小鼠的基因约80%相同,则人与小鼠DNA碱基序列相同的比例是( )
基因研究最新发现,人与小鼠的基因约80%相同,则人与小鼠DNA碱基序列相同的比例是( )
A. 20%
B. 80%
C. 100%
D. 无法确定wdakui1年前2 -
Decemberlie 共回答了19个问题
|采纳率73.7%解题思路:基因是有遗传效应的DNA分子片段,每个基因都是由成百上千个脱氧核苷酸构成.虽然人与小鼠的基因约80%相同,但由于组成基因的碱基数目、排列顺序不同,所以基因所携带的遗传信息不同.尤其是DNA分子中只有少部分碱基序列有遗传效应,大部分碱基序列位于基因与基因之间,因此,无法确定人与小鼠DNA碱基序列相同的比例.
故选:D.点评:
本题考点: DNA分子的多样性和特异性.
考点点评: 本题考查DNA分子的多样性和特异性的相关知识,意在考查学生的识记能力和判断能力,运用所学知识综合分析问题和解决问题的能力.1年前查看全部
- eviews分析中,时间序列中有大量负数,在对这一时间序列做ADF平稳性检验的时候要对这些负数进行处理吗?
ssx00321年前1
-
hdpagain 共回答了24个问题
|采纳率91.7%不需要做特殊的处理
我替别人做这类的数据分析蛮多的1年前查看全部
- 我做的是双向测序,片段300bp左右.请问怎么在测序结果中找出引物?需不需要把某个片段或序列变方向之类的
zhengtong781年前2
-
茉美眉 共回答了15个问题
|采纳率80%正向测序结果可以找到反向引物的反向互补序列
反向测序结果可以找到正向引物的反向互补序列1年前查看全部
- 数据结构中,已知序列【10,1,15,18,7,15 ,9,21】 写出希尔排序的每趟结果
52zzy1年前0
-
共回答了个问题
|采纳率
- 时间序列分析中,通常把因变量的变化看成是趋势项,波动项、季节项等的合成,这些项中哪些是可省的,哪些是不可省的.如果同样的
时间序列分析中,通常把因变量的变化看成是趋势项,波动项、季节项等的合成,这些项中哪些是可省的,哪些是不可省的.如果同样的问题,同样的数据,都采用时间序列分析,那么不同的人得到的结果会相同吗?急,急!
丑丑爱美丽1年前1 -
zhiweiai 共回答了19个问题
|采纳率94.7%时间序列分析是一个很大的分类,包括很多模型,分别适用于不同的情况.所以得到的结果一不一样和建的模型一不一样有关系.至于模型长什么样要看数据长什么样.把数据按时间画出来,看有没有明显趋势,波动或者季节性,然后一个一个模型试.1年前查看全部
- 哪家公司可以代做实验,设计EGFP融合表达载体构建的相关序列?
sxdtjfb1年前1
-
paciwood66 共回答了19个问题
|采纳率100%我也在烦我的毕业论文,我之前想找威斯腾生物做,但是价格稍微有点高,不过据说质量杠杠的,所以我也在纠结,要不你去试试然后给我说,不过时间越来越紧张了.1年前查看全部
- 如何由DNA序列计算RNA序列?
yusiweihao1年前1
-
D龙游四海 共回答了11个问题
|采纳率90.9%按照碱基互补配对原则,
A-U
C-G
G-C
T-A
左侧是DNA,右侧是RNA.
然后依次写出RNA上的碱基即可.
若是计算百分含量,则对一特定碱基,其占DNA双链的比例与对应(与之配对)的RNA所占的比例相等.1年前查看全部
- DNA复制时,DNA聚合酶先与-35区的DNA序列(即启动子)结合,然后滑动到-10区开始转录
DNA复制时,DNA聚合酶先与-35区的DNA序列(即启动子)结合,然后滑动到-10区开始转录
1.它从-35到-10这段序列是干什么?
2.-10序列是不是基因的第一个外显子的第一个核苷酸?
3.这里出现的-35,-10.那0点是相对哪里定的?为什么定义那个地方为0点?wang139363003761年前2 -
BJ三色堇 共回答了16个问题
|采纳率87.5%1.你得让人家有个过渡吧,你有兴趣看看具体的转录起始过程,转录起始复合物有N多个亚基,西格玛亚基先与-35区结合,这是结合亚基,然后开始组装转录起始复合体,形成催化亚基,与-10区相互作用,起始转录,转录开始后西格玛亚基脱落,催化亚基才能前进.-35区如果和-10区连着,催化亚基形成之后直接在起始位点后面了,鬼和他作用啊.有时候没用就是大用处.
2.既然是-10区当然就不是.是不就是0区了吗.
3.2答完了你也就知道了吧.1年前查看全部
- fft是序列傅立叶变换的快速算法
雷霆炫飞龙1年前1
-
mayao2233 共回答了15个问题
|采纳率100%楼上正解.
fast Fourier transform (FFT):快速傅里叶变换
A fast Fourier transform (FFT) is an efficient algorithm to compute the discrete Fourier transform (DFT) and its inverse.1年前查看全部
- 如何查找拟南芥霜霉病基因rpp13的序列
识见1年前1
-
sdfsfwasdf 共回答了13个问题
|采纳率100%通过显微镜观察查找1年前查看全部
- 简述判断时间序列是否为直线型的方法?
qhg81年前1
-
bacmilano 共回答了19个问题
|采纳率84.2%电大作业吧 直接复制即可
时间顺序有成动态数列,他是由反映市场现象在不同时间上的数量特征的一系列观察值按时间先后顺序排列后形成的数列,市场现象的发展变化收到多种因素的影响,不同因素的影响会是时间序列呈现不同的变动特征.有些因素对现象的发展起着长期的 决定性作用,致使现象的发展趋势呈现出某种倾向或规律性;有些因素则对现象的发展起着短期的 非决定性做用,致使现象呈现出某种不规则性 所以 时间序列不是直线型方法1年前查看全部
- 有一个分数序列:2/1、3/2、5/3、8/5,13/8,21/13……求这个数列的前20项及总和
有一个分数序列:2/1、3/2、5/3、8/5,13/8,21/13……求这个数列的前20项及总和
#include
int main()
{
x05int fz=2,fm=1,t,i=1;
x05double fs,s=0;
x05while(i<=20)
x05{x05
x05x05fs=fz/fm;
x05x05s=s+fs;
x05x05t=fz;
x05x05fz=fz+fm;
x05x05fm=t;
x05x05i++;
x05x05printf("fs=%d,s=%d,fz=%d,fm=%dn",fs,s,fz,fm);
x05}
x05return 0;
}
这是我写的程序,为什么是这样的结果
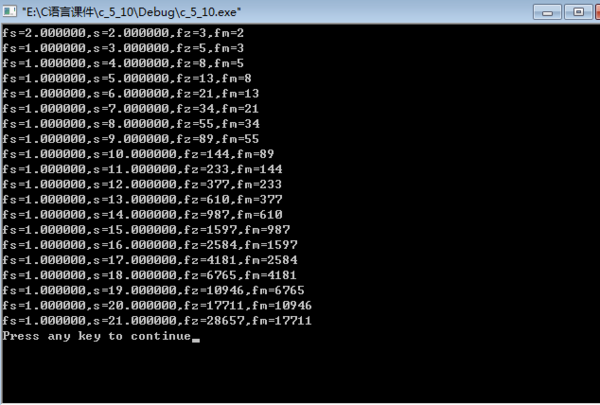 15890838yj1年前1
15890838yj1年前1 -
绝对球王 共回答了21个问题
|采纳率85.7%s 没有赋初值、数据类型有问题 程序第5行改为folate fs,s=0;
doubt指的是双精度整型吧 所以你的程序输出结果是取整后的结果1年前查看全部
- 1基因的脱氧核苷酸排列序列称为().基因突变是()的主要来源也是()的主要因素
1基因的脱氧核苷酸排列序列称为().基因突变是()的主要来源也是()的主要因素
2基因突变是指基因内部的()包括DNA碱基对的()或(),在自然条件下,对某一生物来说,突变发生率().3、已知A对a,B对b显性.他们分别位于两对同源染色体上,现在一个精原细胞和一个卵原细胞减数分裂产生精子的基因型为()产生卵细胞的基因型为()【写出所有可能的基因型】Pass:会做那道就做哪道.zocrates1年前1 -
yongzhang551 共回答了21个问题
|采纳率85.7%2基因突变是指基因内部的(改变)包括DNA碱基对的(缺失)或(增添),在自然条件下,对某一生物来说,突变发生率(极低).3、已知A对a,B对b显性.他们分别位于两对同源染色体上,现在一个精原细胞和一个卵原细胞减数分裂产生精子的基因型为()产生卵细胞的基因型为()【写出所有可能的基因型】
第三题不知道题目的意思是什么,没有给出细胞的基因型,怎么确定其减数分裂的基因型呢?1年前查看全部
- 光学设计中序列和非序列各指什么意思?
jiajia200411291年前1
-
神奇宝宝 共回答了22个问题
|采纳率81.8%序列是单方向,从物到像.非序列是允许多次反射折射,主要用于照明等的模拟.1年前查看全部
- 有些病毒的核酸与甫乳动物细胞DNA某些片段的碱基序列十分相似
zjk_231年前3
-
钟山看雨 共回答了13个问题
|采纳率84.6%这很正常
病毒会把自己的基因序列插入到人类染色体中,再重新包装的时候,有时会发生错误,将人类的一段序列包装进去1年前查看全部
- 对一对夫妇所生的两个女儿(非双胞胎)甲和乙的X染色体进行DNA序列的分析,假定DNA序列不发生任何变异,则结果应当是(
对一对夫妇所生的两个女儿(非双胞胎)甲和乙的X染色体进行DNA序列的分析,假定DNA序列不发生任何变异,则结果应当是( )
A. 甲的两条彼此相同、乙的两条彼此相同的概率为1
B. 甲来自母亲的一条与乙来自母亲的一条相同的概率为1
C. 甲来自父亲的一条与乙来自父亲的一条相同的概率为1
D. 甲的任何一条与乙的任何一条都不相同的概率为1qy11741年前1 -
沫沫射手 共回答了10个问题
|采纳率100%解题思路:XY型生物雌性个体的体细胞中性染色体为XX,两条X染色体是同源染色体,一条来自母方,一条来自父方.雄性个体的性染色体为XY,属于一对异型的同源染色体,其中X来自母方,Y染色体来自父方.A、甲的一条来自父亲的和乙的一条来自父亲的完全相同,来自母亲的是两条X,假设为X1和X2,女儿的基因型是XX1或XX2,第一个女儿是XX1的概率是[1/2],第二个女儿是XX1的概率是[1/2],所以两者同为XX1的概率是[1/4],同理两个女儿是XX2的概率也是[1/4],所以甲的两条彼此相同、乙的两条彼此相同的概率为[1/2],A错误;
B、取甲来自父亲的 X的可能为[1/2],取乙来自父亲的X的可能为[1/2],该可能为[1/4];取甲来自母亲的X的可能为[1/2],取乙来自母亲的可能为[1/2],相同的可能为[1/2],该可能为[1/2]×[1/2]×[1/2]=[1/8],所以相同概率为[3/8],不同为[5/8],B错误;
C、由于父亲只含一条X染色体,所以甲来自父亲的一条与乙来自父亲的一条相同的概率为1,C正确;
D、甲来自父亲的X与乙来自父亲的X肯定相同,所以甲的任何一条与乙的任何一条有可能相同,甲的任何一条与乙的任何一条都不相同的概率为[5/8],D错误.
故选:C.点评:
本题考点: 伴性遗传.
考点点评: 本题借助于性别决定和伴性遗传相关知识点,进行遗传概率的计算,意在考查学生利用所学知识解决实际问题的能力.1年前查看全部
- 数据结构试卷上的题,一个栈的输入序列为1 2 3 4 5,则下列序列中不可能是栈的输出序列的是A 2 3 4 1 5 B
数据结构试卷上的题,
一个栈的输入序列为1 2 3 4 5,则下列序列中不可能是栈的输出序列的是
A 2 3 4 1 5 B 5 4 1 3 2
C 2 3 1 4 5 D 1 5 4 3 2
来个高手讲清楚,感激不尽!jiephoenix1年前1 -
邦溪专营店球队 共回答了15个问题
|采纳率93.3%B
A、1进 2进 2出 3进 3出 4进 4出 1出 5进 5出
C、1进 2进 2出 3进 3出 1出 4进 4出 5进 5出
D、1进 1出 2进 3进 4进 5进 5出 4出 3出 2出1年前查看全部
大家在问
- 1(2013•天元区模拟)化学知识中有很多的“相等”.请你判断下列说法中不正确的是( )
- 2数学“圆”这一章中不是定理,但可以作为定理使用的一些结论有哪些,帮忙列出来,需要例题
- 3一个靠墙围起的直角梯形篱笆,篱笆共长45米,它的面积是多少平方米?
- 4若要获取耐高温淀粉酶微生物,其富集培养应选择什么培养基?并在< >条件下培养?
- 5一个两位数,十位上的数字比个位上的数字小1,十位数的数字与个位上的数字的和是这个两位数的0.2倍,求这个
- 6中“野火烧不尽,春风吹又生.”可以说是描写春天的景物的诗句吗?
- 79月10日,8月18日,7月4日,12月24日,2月2日的英文!
- 8自来水公司的仓库里有一堆水管,第一层放3根水管,第二层放5根水管,以后每层多放两根,最底层15层,这堆水管有多少根?
- 9现有Na2O、 NaOH、Na2CO3的混合物11.2g,将其与49.5g20%的稀盐酸混合,恰好完全反应,同时放出2.
- 10若单项式—6a的x—2b与2分之1a的3次方b的3—y是同类项,则代数式(x的平方—y的3次方)—(y—x)的值为
- 11听音乐是令人轻松的用英语怎么说
- 12宇宙大爆炸具体过程是什么?我对这方面十分感兴趣,宇宙大爆炸是否是由某种单个原子的某种核变化产生的?
- 132005年9月12日是星期一,2006年同一天为什么是星期二
- 14我12岁,求英语生日演讲稿要有翻译!求求了!在宾馆,上台演讲
- 15将四分之一圆分割成一个三角形和一个几何图形,三角形10cm²,问该几何图形面积